剛開始,根據我的想法,這個很簡單嘛,上sql語句
delete from zqzrdp where tel in (select min(dpxx_id) from zqzrdp group by tel having count(tel)>1);
執行,報錯!!~!~
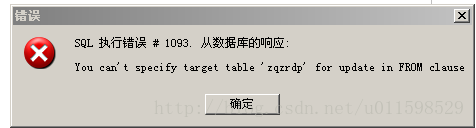
異常意為:你不能指定目標表的更新在FROM子句。傻了,MySQL 這樣寫,不行,讓人郁悶。
難倒只能分步操作,蛋疼
以下是網友寫的,同樣是坑爹的代碼,我機器上運行不了。
1. 查詢需要刪除的記錄,會保留一條記錄。
select a.id,a.subject,a.RECEIVER from test1 a left join (select c.subject,c.RECEIVER ,max(c.id) as bid from test1 c where status=0 GROUP BY RECEIVER,SUBJECT having count(1) >1) b on a.id< b.bid where a.subject=b.subject and a.RECEIVER = b.RECEIVER and a.id < b.bid
2. 刪除重復記錄,只保留一條記錄。注意,subject,RECEIVER 要索引,否則會很慢的。
delete a from test1 a, (select c.subject,c.RECEIVER ,max(c.id) as bid from test1 c where status=0 GROUP BY RECEIVER,SUBJECT having count(1) >1) b where a.subject=b.subject and a.RECEIVER = b.RECEIVER and a.id < b.bid;
3. 查找表中多余的重復記錄,重復記錄是根據單個字段(peopleId)來判斷
select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
4. 刪除表中多余的重復記錄,重復記錄是根據單個字段(peopleId)來判斷,只留有rowid最小的記錄
delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
5.刪除表中多余的重復記錄(多個字段),只留有rowid最小的記錄
delete from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
看來想偷懶使用一句命令完成這個事好像不太顯示,還是老老實實的分步處理吧,思路先建立復制一個臨時表,然後對比臨時表內的數據,刪除主表裡的數據
alter table tableName add autoID int auto_increment not null; create table tmp select min(autoID) as autoID from tableName group by Name,Address; create table tmp2 select tableName.* from tableName,tmp where tableName.autoID = tmp.autoID; drop table tableName; rename table tmp2 to tableName;