殊不知,在N年前被奉為“聖經”的數據庫設計3范式早就已經不完全適用了。這裡我整理了一些比較常見的數據庫表結構設計方面的優化技巧,希望對大家有用。
由於MySQL數據庫是基於行(Row)存儲的數據庫,而數據庫操作 IO 的時候是以 page(block)的方式,也就是說,如果我們每條記錄所占用的空間量減小,就會使每個page中可存放的數據行數增大,那麼每次 IO 可訪問的行數也就增多了。反過來說,處理相同行數的數據,需要訪問的 page 就會減少,也就是 IO 操作次數降低,直接提升性能。此外,由於我們的內存是有限的,增加每個page中存放的數據行數,就等於增加每個內存塊的緩存數據量,同時還會提升內存換中數據命中的幾率,也就是緩存命中率。
一、數據類型選擇
數據庫操作中最為耗時的操作就是 IO 處理,大部分數據庫操作 90% 以上的時間都花在了 IO 讀寫上面。所以盡可能減少 IO 讀寫量,可以在很大程度上提高數據庫操作的性能。
我們無法改變數據庫中需要存儲的數據,但是我們可以在這些數據的存儲方式方面花一些心思。下面的這些關於字段類型的優化建議主要適用於記錄條數較多,數據量較大的場景,因為精細化的數據類型設置可能帶來維護成本的提高,過度優化也可能會帶來其他的問題:
1.數字類型:非萬不得已不要使用DOUBLE,不僅僅只是存儲長度的問題,同時還會存在精確性的問題。同樣,固定精度的小數,也不建議使用DECIMAL,建議乘以固定倍數轉換成整數存儲,可以大大節省存儲空間,且不會帶來任何附加維護成本。對於整數的存儲,在數據量較大的情況下,建議區分開 TINYINT / INT / BIGINT 的選擇,因為三者所占用的存儲空間也有很大的差別,能確定不會使用負數的字段,建議添加unsigned定義。當然,如果數據量較小的數據庫,也可以不用嚴格區分三個整數類型。
2.字符類型:非萬不得已不要使用 TEXT 數據類型,其處理方式決定了他的性能要低於char或者是varchar類型的處理。定長字段,建議使用 CHAR 類型,不定長字段盡量使用 VARCHAR,且僅僅設定適當的最大長度,而不是非常隨意的給一個很大的最大長度限定,因為不同的長度范圍,MySQL也會有不一樣的存儲處理。
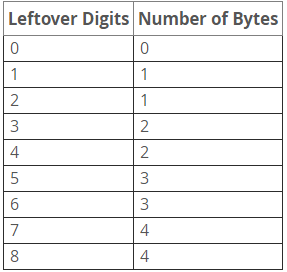
3.時間類型:盡量使用TIMESTAMP類型,因為其存儲空間只需要 DATETIME 類型的一半。對於只需要精確到某一天的數據類型,建議使用DATE類型,因為他的存儲空間只需要3個字節,比TIMESTAMP還少。不建議通過INT類型類存儲一個unix timestamp 的值,因為這太不直觀,會給維護帶來不必要的麻煩,同時還不會帶來任何好處。
4.ENUM & SET:對於狀態字段,可以嘗試使用 ENUM 來存放,因為可以極大的降低存儲空間,而且即使需要增加新的類型,只要增加於末尾,修改結構也不需要重建表數據。如果是存放可預先定義的屬性數據呢?可以嘗試使用SET類型,即使存在多種屬性,同樣可以游刃有余,同時還可以節省不小的存儲空間。
5.LOB類型:強烈反對在數據庫中存放 LOB 類型數據,雖然數據庫提供了這樣的功能,但這不是他所擅長的,我們更應該讓合適的工具做他擅長的事情,才能將其發揮到極致。在數據庫中存儲 LOB 數據就像讓一個多年前在學校學過一點Java的營銷專業人員來寫 Java 代碼一樣。
二、字符編碼
字符集直接決定了數據在MySQL中的存儲編碼方式,由於同樣的內容使用不同字符集表示所占用的空間大小會有較大的差異,所以通過使用合適的字符集,可以幫助我們盡可能減少數據量,進而減少IO操作次數。
1.純拉丁字符能表示的內容,沒必要選擇 latin1 之外的其他字符編碼,因為這會節省大量的存儲空間
2.如果我們可以確定不需要存放多種語言,就沒必要非得使用UTF8或者其他UNICODE字符類型,這回造成大量的存儲空間浪費
3.MySQL的數據類型可以精確到字段,所以當我們需要大型數據庫中存放多字節數據的時候,可以通過對不同表不同字段使用不同的數據類型來較大程度減小數據存儲量,進而降低 IO 操作次數並提高緩存命中率
三、適當拆分
有些時候,我們可能會希望將一個完整的對象對應於一張數據庫表,這對於應用程序開發來說是很有好的,但是有些時候可能會在性能上帶來較大的問題。
當我們的表中存在類似於 TEXT 或者是很大的 VARCHAR類型的大字段的時候,如果我們大部分訪問這張表的時候都不需要這個字段,我們就該義無反顧的將其拆分到另外的獨立表中,以減少常用數據所占用的存儲空間。這樣做的一個明顯好處就是每個數據塊中可以存儲的數據條數可以大大增加,既減少物理 IO 次數,也能大大提高內存中的緩存命中率。
上面幾點的優化都是為了減少每條記錄的存儲空間大小,讓每個數據庫中能夠存儲更多的記錄條數,以達到減少 IO 操作次數,提高緩存命中率。下面這個優化建議可能很多開發人員都會覺得不太理解,因為這是典型的反范式設計,而且也和上面的幾點優化建議的目標相違背。
四、適度冗余
為什麼我們要冗余?這不是增加了每條數據的大小,減少了每個數據塊可存放記錄條數嗎?
確實,這樣做是會增大每條記錄的大小,降低每條記錄中可存放數據的條數,但是在有些場景下我們仍然還是不得不這樣做:
被頻繁引用且只能通過 Join 2張(或者更多)大表的方式才能得到的獨立小字段
這樣的場景由於每次Join僅僅只是為了取得某個小字段的值,Join到的記錄又大,會造成大量不必要的 IO,完全可以通過空間換取時間的方式來優化。不過,冗余的同時需要確保數據的一致性不會遭到破壞,確保更新的同時冗余字段也被更新
五、盡量使用 NOT NULL
NULL 類型比較特殊,SQL 難優化。雖然 MySQL NULL類型和 Oracle 的NULL 有差異,會進入索引中,但如果是一個組合索引,那麼這個NULL 類型的字段會極大影響整個索引的效率。此外,NULL 在索引中的處理也是特殊的,也會占用額外的存放空間。
很多人覺得 NULL 會節省一些空間,所以盡量讓NULL來達到節省IO的目的,但是大部分時候這會適得其反,雖然空間上可能確實有一定節省,倒是帶來了很多其他的優化問題,不但沒有將IO量省下來,反而加大了SQL的IO量。所以盡量確保 DEFAULT 值不是 NULL,也是一個很好的表結構設計優化習慣。