爛sql不僅直接影響sql的響應時間,更影響db的性能,導致其它正常的sql響應時間變長。如何寫好sql,學會看執行計劃至關重要。下面我簡單講講mysql的執行計劃,只列出了一些常見的情況,希望對大家有所幫助。
測試表結構:
復制代碼 代碼如下:
CREATE TABLE `t1` (
`c1` int(11) NOT NULL DEFAULT '0',
`c2` varchar(128) DEFAULT NULL,
`c3` varchar(64) DEFAULT NULL,
`c4` int(11) DEFAULT NULL,
PRIMARY KEY (`c1`),
KEY `ind_c2` (`c2`),
KEY `ind_c4` (`c4`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `t2` (
`c1` int(11) NOT NULL DEFAULT '0',
`c2` varchar(128) DEFAULT NULL,
`c3` varchar(64) DEFAULT NULL,
`c4` int(11) DEFAULT NULL,
PRIMARY KEY (`c1`),
KEY `ind_c2` (`c2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `t3` (
`c1` int(11) NOT NULL DEFAULT '0',
`c2` varchar(128) DEFAULT NULL,
`c3` varchar(64) DEFAULT NULL,
`c4` int(11) DEFAULT NULL,
PRIMARY KEY (`c1`),
KEY `ind_c2` (`c2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
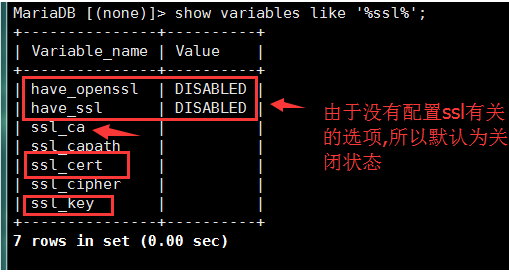
1.查看mysql執行計劃
explain select ......
2.執行計劃包含的信息
![]()
(1).id
含義,指示select字句或操作表的順序。
eg1:id相同,執行順序從上到下,下面的執行計劃表示,先操作t1表,然後操作t2表,最後操作t3表。

eg2:若存在子查詢,則子查詢(內層查詢)id大於父查詢(外層查詢),先執行子查詢。id越大,優先級越高。

(2).select_type
含義:select語句的類型
類型:
a.SIMPLE:查詢中不包含子查詢或者UNION
b.查詢中若包含任何復雜的子部分,最外層查詢則被標記為:PRIMARY
c.在SELECT或WHERE列表中包含了子查詢,該子查詢被標記為:SUBQUERY
d.在FROM列表中包含的子查詢被標記為:DERIVED(衍生)
e.若第二個SELECT出現在UNION之後,則被標記為UNION;若UNION包含在 FROM子句的子查詢中,
外層SELECT將被標記為:DERIVED
f.從UNION表獲取結果的SELECT被標記為:UNION RESULT
eg:

id為1的table顯示<derived2>,表示結果來源於衍生表2。
id為2表示子查詢,讀取t3表
id為3類型為union,是union的第二個select,最先執行;
id為NULL的類型為union result, <union 1,3>表示id為1的操作和id為3的操作進行結果集合並。
執行順序3->2->1->NULL
(3).type
含義:獲取記錄行采用的方式,亦即mysql的訪問方式。

a.ALL:Full Table Scan, MySQL將遍歷全表以找到匹配的行

b.index:Full Index Scan,index與ALL區別為index類型只遍歷索引,索引一般比記錄要小。

因為索引中含有c1,查詢c1,c2可以通過索引掃描實現。
c.range:索引范圍掃描,對索引的掃描開始於某一點,返回匹配值域的行,常見於between、<、>等的查詢
備注:range類型肯定是使用了索引掃描,否則type為ALL

d.ref:非唯一性索引掃描,返回匹配某個單獨值的所有行。常見於使用非唯一索引即唯一索引的非唯一前綴進行的查找

t2.c4為非唯一索引
e.eq_ref:唯一性索引掃描,對於每個索引鍵,表中只有一條記錄與之匹配。常見於主鍵或唯一索引掃描

t2.c1為主鍵索引,主鍵索引也是唯一索引
f.const、system:當MySQL對查詢某部分進行優化,並轉換為一個常量時,使用這些類型訪問。如將主鍵置於where列表中,
MySQL就能將該查詢轉換為一個常量,system是const類型的特例,當查詢的表只有一行的情況下, 使用system

(4).possible_keys
含義:指出MySQL能使用哪個索引在表中找到行,查詢涉及到的字段上若存在索引,則該索引將被列出,但不一定被查詢使用
(5).key
含義:顯示MySQL在查詢中實際使用的索引,若沒有使用索引,顯示為NULL
(6)key_len
含義:表示索引中使用的字節數,可通過該列計算查詢中使用的索引的長度
(7)ref
含義:用於連接查詢,表示具體某個表的某列被引用
(8)rows
含義:MySQL根據表統計信息及索引選用情況,估算的找到所需的記錄所需要讀取的行數,這個值是不准確的,只有參考意義。
(9)Extra
含義:顯示一些輔助的額外信息
a.Using index,表示使用了索引
b.Using where,表示通過where條件過濾
c.Using temporary,表示使用了臨時表,常見於分組和排序
d.Using filesort,表示無法使用索引排序,需要文件排序
eg1:t1.c3列沒有索引

eg2:使用索引列t1.c2