MySQL中涉及的幾個字符集 character-set-server/default-character-set:服務器字符集,默認情況下所采用的。
character-set-database:數據庫字符集。
character-set-table:數據庫表字符集。
優先級依次增加。所以一般情況下只需要設置character-set-server,而在創建數據庫和表時不特別指定字符集,這樣統一采用character-set-server字符集。
character-set-client:客戶端的字符集。客戶端默認字符集。當客戶端向服務器發送請求時,請求以該字符集進行編碼。
character-set-results:結果字符集。服務器向客戶端返回結果或者信息時,結果以該字符集進行編碼。
在客戶端,如果沒有定義character-set-results,則采用character-set-client字符集作為默認的字符集。所以只需要設置character-set-client字符集。
要處理中文,則可以將character-set-server和character-set-client均設置為GB2312,如果要同時處理多國語言,則設置為UTF8。
關於MySQL的中文問題 解決亂碼的方法是,在執行SQL語句之前,將MySQL以下三個系統參數設置為與服務器字符集character-set-server相同的字符集。
character_set_client:客戶端的字符集。
character_set_results:結果字符集。
character_set_connection:連接字符集。
設置這三個系統參數通過向MySQL發送語句:set names gb2312
關於GBK、GB2312、UTF8 UTF-8:Unicode Transformation Format-8bit,允許含BOM,但通常不含BOM。是用以解決國際上字符的一種多字節編碼,它對英文使用8位(即一個字節),中文使用24為(三個字節)來編碼。UTF-8包含全世界所有國家需要用到的字符,是國際編碼,通用性強。UTF-8編碼的文字可以在各國支持UTF8字符集的浏覽器上顯示。如,如果是UTF8編碼,則在外國人的英文IE上也能顯示中文,他們無需下載IE的中文語言支持包。
GBK是國家標准GB2312基礎上擴容後兼容GB2312的標准。GBK的文字編碼是用雙字節來表示的,即不論中、英文字符均使用雙字節來表示,為了區分中文,將其最高位都設定成1。GBK包含全部中文字符,是國家編碼,通用性比UTF8差,不過UTF8占用的數據庫比GBD大。
GBK、GB2312等與UTF8之間都必須通過Unicode編碼才能相互轉換:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312
對於一個網站、論壇來說,如果英文字符較多,則建議使用UTF-8節省空間。不過現在很多論壇的插件一般只支持GBK。
GB2312是GBK的子集,GBK是GB18030的子集
GBK是包括中日韓字符的大字符集合
如果是中文的網站 推薦GB2312 GBK有時還是有點問題
為了避免所有亂碼問題,應該采用UTF-8,將來要支持國際化也非常方便
UTF-8可以看作是大字符集,它包含了大部分文字的編碼。
使用UTF-8的一個好處是其他地區的用戶(如香港台灣)無需安裝簡體中文支持就能正常觀看你的文字而不會出現亂碼。
gb2312是簡體中文的碼
gbk支持簡體中文及繁體中文
big5支持繁體中文
utf-8支持幾乎所有字符
首先分析亂碼的情況
1.寫入數據庫時作為亂碼寫入
2.查詢結果以亂碼返回
究竟在發生亂碼時是哪一種情況呢?
我們先在mysql 命令行下輸入
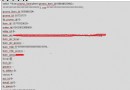
show variables like '%char%';
查看mysql 字符集設置情況:
mysql> show variables like '%char%';
+--------------------------+----------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------+
| character_set_client | gbk |
| character_set_connection | gbk |
| character_set_database | gbk |
| character_set_filesystem | binary |
| character_set_results | gbk |
| character_set_server | gbk |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/mysql/charsets/ |
+--------------------------+----------------------------------------+
在查詢結果中可以看到mysql 數據庫系統中客戶端、數據庫連接、數據庫、文件系統、查詢
結果、服務器、系統的字符集設置
在這裡,文件系統字符集是固定的,系統、服務器的字符集在安裝時確定,與亂碼問題無關
亂碼的問題與客戶端、數據庫連接、數據庫、查詢結果的字符集設置有關
*注:客戶端是看訪問mysql 數據庫的方式,通過命令行訪問,命令行窗口就是客戶端,通
過JDBC 等連接訪問,程序就是客戶端
我們在向mysql 寫入中文數據時,在客戶端、數據庫連接、寫入數據庫時分別要進行編碼轉
換
在執行查詢時,在返回結果、數據庫連接、客戶端分別進行編碼轉換
現在我們應該清楚,亂碼發生在數據庫、客戶端、查詢結果以及數據庫連接這其中一個或多
個環節
接下來我們來解決這個問題
在登錄數據庫時,我們用mysql --default-character-set=字符集-u root -p 進行連接,這時我們
再用show variables like '%char%';命令查看字符集設置情況,可以發現客戶端、數據庫連接、
查詢結果的字符集已經設置成登錄時選擇的字符集了
如果是已經登錄了,可以使用set names 字符集;命令來實現上述效果,等同於下面的命令:
set character_set_client = 字符集
set character_set_connection = 字符集
set character_set_results = 字符集
如果是通過JDBC 連接數據庫,可以這樣寫URL:
URL=jdbc:mysql://localhost:3306/abs?useUnicode=true&characterEncoding=字符集
JSP 頁面等終端也要設置相應的字符集
數據庫的字符集可以修改mysql 的啟動配置來指定字符集,也可以在create database 時加上
default character set 字符集來強制設置database 的字符集
通過這樣的設置,整個數據寫入讀出流程中都統一了字符集,就不會出現亂碼了
為什麼從命令行直接寫入中文不設置也不會出現亂碼?
可以明確的是從命令行下,客戶端、數據庫連接、查詢結果的字符集設置沒有變化
輸入的中文經過一系列轉碼又轉回初始的字符集,我們查看到的當然不是亂碼
但這並不代表中文在數據庫裡被正確作為中文字符存儲
舉例來說,現在有一個utf8 編碼數據庫,客戶端連接使用GBK 編碼,connection 使用默認
的ISO8859-1(也就是mysql 中的latin1),我們在客戶端發送“中文”這個字符串,客戶端
將發送一串GBK 格式的二進制碼給connection 層,connection 層以ISO8859-1 格式將這段
二進制碼發送給數據庫,數據庫將這段編碼以utf8 格式存儲下來,我們將這個字段以utf8
格式讀取出來,肯定是得到亂碼,也就是說中文數據在寫入數據庫時是以亂碼形式存儲的,
在同一個客戶端進行查詢操作時,做了一套和寫入時相反的操作,錯誤的utf8 格式二進制
碼又被轉換成正確的GBK 碼並正確顯示出來。