基本概念
• 字符(Character)是指人類語言中最小的表義符號。例如'A'、'B'等;
• 給定一系列字符,對每個字符賦予一個數值,用數值來代表對應的字符,這一數值就是字符的編碼(Encoding)。例如,我們給字符'A'賦予數值0,給字符'B'賦予數值1,則0就是字符'A'的編碼;
• 給定一系列字符並賦予對應的編碼後,所有這些字符和編碼對組成的集合就是字符集(Character Set)。例如,給定字符列表為{'A','B'}時,{'A'=>0, 'B'=>1}就是一個字符集;
• 字符序(Collation)是指在同一字符集內字符之間的比較規則;
• 確定字符序後,才能在一個字符集上定義什麼是等價的字符,以及字符之間的大小關系;
• 每個字符序唯一對應一種字符集,但一個字符集可以對應多種字符序,其中有一個是默認字符序(Default Collation);
• MySQL中的字符序名稱遵從命名慣例:以字符序對應的字符集名稱開頭;以_ci(表示大小寫不敏感)、_cs(表示大小寫敏感)或_bin(表示按編碼值比較)結尾。例如:在字符序``utf8_general_ci''下,字符``a''和``A''是等價的;
MySQL字符集設置
• 系統變量:
– character_set_server:默認的內部操作字符集
– character_set_client:客戶端來源數據使用的字符集
– character_set_connection:連接層字符集
– character_set_results:查詢結果字符集
– character_set_database:當前選中數據庫的默認字符集
– character_set_system:系統元數據(字段名等)字符集
– 還有以collation_開頭的同上面對應的變量,用來描述字符序。
• 用introducer指定文本字符串的字符集:
– 格式為:[_charset] 'string' [COLLATE collation]
– 例如:
• SELECT _latin1 'string';
• SELECT _utf8 '你好' COLLATE utf8_general_ci;
– 由introducer修飾的文本字符串在請求過程中不經過多余的轉碼,直接轉換為內部字符集處理。
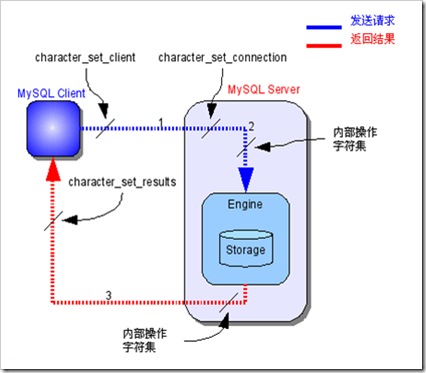
MySQL中的字符集轉換過程
1. MySQL Server收到請求時將請求數據從character_set_client轉換為character_set_connection;
2. 進行內部操作前將請求數據從character_set_connection轉換為內部操作字符集,其確定方法如下:
• 使用每個數據字段的CHARACTER SET設定值;
• 若上述值不存在,則使用對應數據表的DEFAULT CHARACTER SET設定值(MySQL擴展,非SQL標准);
• 若上述值不存在,則使用對應數據庫的DEFAULT CHARACTER SET設定值;
• 若上述值不存在,則使用character_set_server設定值。
3. 將操作結果從內部操作字符集轉換為character_set_results。
常見問題解析
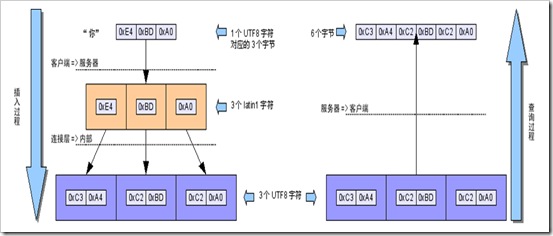
• 向默認字符集為utf8的數據表插入utf8編碼的數據前沒有設置連接字符集,查詢時設置連接字符集為utf8
– 插入時根據MySQL服務器的默認設置,character_set_client、character_set_connection和character_set_results均為latin1;
– 插入操作的數據將經過latin1=>latin1=>utf8的字符集轉換過程,這一過程中每個插入的漢字都會從原始的3個字節變成6個字節保存;
– 查詢時的結果將經過utf8=>utf8的字符集轉換過程,將保存的6個字節原封不動返回,產生亂碼……
• 向默認字符集為latin1的數據表插入utf8編碼的數據前設置了連接字符集為utf8
– 插入時根據連接字符集設置,character_set_client、character_set_connection和character_set_results均為utf8;
– 插入數據將經過utf8=>utf8=>latin1的字符集轉換,若原始數據中含有/u0000~/u00ff范圍以外的Unicode字符,會因為無法在latin1字符集中表示而被轉換為“?”(0x3F)符號,以後查詢時不管連接字符集設置如何都無法恢復其內容了。
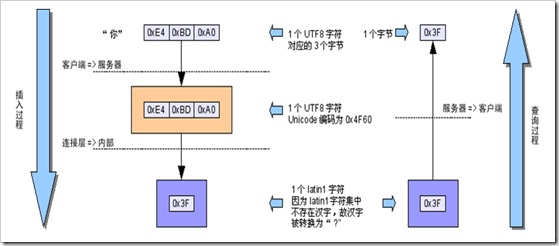
檢測字符集問題的一些手段
• SHOW CHARACTER SET;
• SHOW COLLATION;
• SHOW VARIABLES LIKE 'character%';
• SHOW VARIABLES LIKE 'collation%';
• SQL函數HEX、LENGTH、CHAR_LENGTH
• SQL函數CHARSET、COLLATION
使用MySQL字符集時的建議 • 建立數據庫/表和進行數據庫操作時盡量顯式指出使用的字符集,而不是依賴於MySQL的默認設置,否則MySQL升級時可能帶來很大困擾;
• 數據庫和連接字符集都使用latin1時雖然大部分情況下都可以解決亂碼問題,但缺點是無法以字符為單位來進行SQL操作,一般情況下將數據庫和連接字符集都置為utf8是較好的選擇;
• 使用mysql C API時,初始化數據庫句柄後馬上用mysql_options設定MYSQL_SET_CHARSET_NAME屬性為utf8,這樣就不用顯式地用SET NAMES語句指定連接字符集,且用mysql_ping重連斷開的長連接時也會把連接字符集重置為utf8;
• 對於mysql PHP API,一般頁面級的PHP程序總運行時間較短,在連接到數據庫以後顯式用SET NAMES語句設置一次連接字符集即可;但當使用長連接時,請注意保持連接通暢並在斷開重連後用SET NAMES語句顯式重置連接字符集。
其他注意事項 • my.cnf中的default_character_set設置只影響mysql命令連接服務器時的連接字符集,不會對使用libmysqlclient庫的應用程序產生任何作用!
• 對字段進行的SQL函數操作通常都是以內部操作字符集進行的,不受連接字符集設置的影響。
• SQL語句中的裸字符串會受到連接字符集或introducer設置的影響,對於比較之類的操作可能產生完全不同的結果,需要小心!/P>
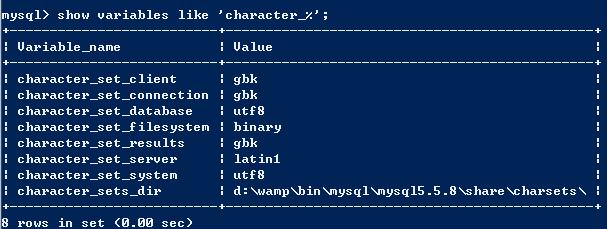
在mysql客戶端與mysql服務端之間,存在著一個字符集轉換器。
character_set_client =>gbk:轉換器就知道客戶端發送過來的是gbk格式的編碼
character_set_connection=>gbk:將客戶端傳送過來的數據轉換成gbk格式
character_set_results =>gbk:
注:以上三個字符集可以使用set names gbk來統一進行設置
例子:
create table test(
name varchar(64) NOT NULL
)charset utf8;#這裡的utf8表示服務器端的字符編碼
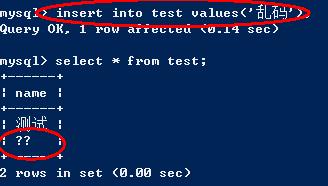
首先,往數據表test中插入一條數據
inert into test values('測試');
則,數據“測試”在數據庫中是以“utf8”格式保存的
過程:
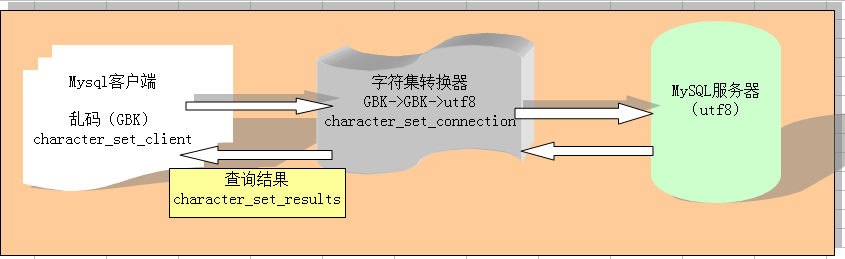
首先,通過mysql客戶端,將數據發送給Mysql服務器,經過字符集轉換器的時候,由於character_set_connection 值為gbk,所以會將客戶端發送過來的數據轉為gbk格式,緊接著,字符集轉換器將數據要傳送給服務器的時候,發現服務器是以utf8保存數據的,所以,在其內部會自動將數據由gbk轉換成utf8格式
什麼時候會出現亂碼?
客戶端的數據格式與聲明的 character_set_client不符
通過 header('Content-type:text/html;charset=utf8');將客戶端的數據轉成utf8格式的,在數據經過“字符集轉換器”的時候,由於character_set_client=gbk,而character_set_connection也等於gbk,所以從客戶端傳送過來的數據(其實是utf8格式)並不會被轉換格式。
但是,字符集轉換器在講數據發送給服務器的時候,發現服務器要的格式是utf8,所以會將當前數 據當做gbk格式來處理,從而轉成utf8(但是,這一步其實已經錯了。。。)。
2. result與客戶端頁面不符合的時候

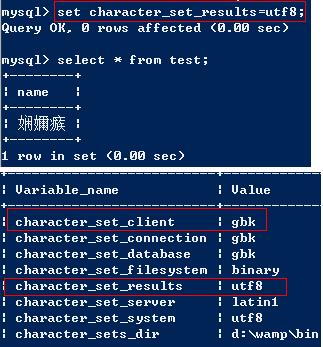
將返回結果的格式設置為utf8,但是客戶端接受的格式為gbk,因此會出現亂碼
通過show character set 語法,可以顯示所有可用的字符集
latin字符集


注意:Maxlen列顯示用於存儲一個字符的最大的字節數目。
utf8字符集
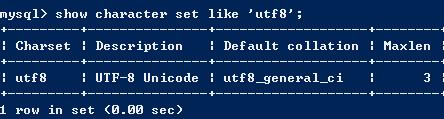

gbk字符集


什麼時候會丟失數據?
對比以上三幅圖可以知道,每種字符集中,用於存儲一個字符的最大的字節數目都不同,utf8最大,latin最小。所以在經過字符集轉換器的時候,如果處理不當,會造成數據丟失,而且是無法挽回的。
比如:
將character_set_connection的值改為lantin的時候
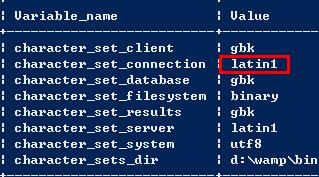

從客戶端發送過來的gbk數據,會被轉成lantin1格式,因為gbk格式的數據占用的字符數較多,從而會造成數據丟失

總結:
character_set_client和character_set_results 一般情況下要一致,因為一個表示客戶端發送的數據格式,另一個表示客戶端接受的數據格式為了避免造成數據丟失,需讓 character_set_connection的字符編碼 大於 character_set_client的字符編碼