下面介紹幾種具體的實現方法.
建立實驗環境如下
mysql> create table tbl (
-> id int primary key,
-> col int
-> );
Query OK, 0 rows affected (0.08 sec)
mysql> insert into tbl values
-> (1,26),
-> (2,46),
-> (3,35),
-> (4,68),
-> (5,93),
-> (6,92);
Query OK, 6 rows affected (0.05 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql>
mysql> select * from tbl order by col;
+----+------+
| id | col |
+----+------+
| 1 | 26 |
| 3 | 35 |
| 2 | 46 |
| 4 | 68 |
| 6 | 92 |
| 5 | 93 |
+----+------+
6 rows in set (0.00 sec)
1. 直接在程序中實現;
這應該算是效率最高的一種,也極為方便。直接在你的開發程序中(PHP/ASP/C/...)等中,直接初始化一個變量nRowNum=0,然後在while 記錄集時,nRowNum++; 然後輸出即可。
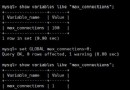
2. 使用MySQL變量;在某些情況下,無法通過修改程序來實現時,可以考慮這種方法。
缺點,@x 變量是 connection 級的,再次查詢的時候需要初始化。一般來說PHP等B/S應用沒有這個問題。但C/S如果connection一只保持則要考慮 set @x=0
mysql> select @x:=ifnull(@x,0)+1 as rownum,id,col
-> from tbl
-> order by col;
+--------+----+------+
| rownum | id | col |
+--------+----+------+
| 1 | 1 | 26 |
| 1 | 3 | 35 |
| 1 | 2 | 46 |
| 1 | 4 | 68 |
| 1 | 6 | 92 |
| 1 | 5 | 93 |
+--------+----+------+
6 rows in set (0.00 sec)
3. 使用聯接查詢(笛卡爾積)
缺點,顯然效率會差一些。
利用表的自聯接,代碼如下,你可以直接試一下 select a.*,b.* from tbl a,tbl b where a.col>=b.col 以理解這個方法原理。
mysql> select a.id,a.col,count(*) as rownum
-> from tbl a,tbl b
-> where a.col>=b.col
-> group by a.id,a.col;
+----+------+--------+
| id | col | rownum |
+----+------+--------+
| 1 | 26 | 1 |
| 2 | 46 | 3 |
| 3 | 35 | 2 |
| 4 | 68 | 4 |
| 5 | 93 | 6 |
| 6 | 92 | 5 |
+----+------+--------+
6 rows in set (0.00 sec)
4. 子查詢
缺點,和聯接查詢一樣,具體的效率要看索引的配置和MySQL的優化結果。
mysql> select a.*,
-> (select count(*) from tbl where col<=a.col) as rownum
-> from tbl a;
+----+------+--------+
| id | col | rownum |
+----+------+--------+
| 1 | 26 | 1 |
| 2 | 46 | 3 |
| 3 | 35 | 2 |
| 4 | 68 | 4 |
| 5 | 93 | 6 |
| 6 | 92 | 5 |
+----+------+--------+
6 rows in set (0.06 sec)
做為一款開源的數據庫系統,MySQL無疑是一個不做的產品。它的更新速度,文檔維護都不遜於幾大商業數據庫產品。估計在下一個版本中,我們可以看到由MySQL自身實現的ROWNUM。