replace、regexp的用法
0 Comments | This entry was posted on Apr 08 2010
mysql replace用法
1.replace into
replace into table (id,name) values('1′,'aa'),('2′,'bb')
此語句的作用是向表table中插入兩條記錄。如果主鍵id為1或2不存在
就相當於
insert into table (id,name) values('1′,'aa'),('2′,'bb')
如果存在相同的值則不會插入數據
2.replace(object,search,replace)
把object中出現search的全部替換為replace
select replace('www.163.com','w','Ww')—>WwWwWw.163.com
例:把表table中的name字段中的aa替換為bb
update table set name=replace(name,'aa','bb')
——————————————————————————–
由MySQL提供的模式匹配的其它類型是使用擴展正則表達式。當你對這類模式進行匹配測試時,使用REGEXP和NOT REGEXP操作符(或RLIKE和NOT RLIKE,它們是同義詞)。
擴展正則表達式的一些字符是:
· ‘.'匹配任何單個的字符。
· 字符類“[...]”匹配在方括號內的任何字符。例如,“[abc]”匹配“a”、“b”或“c”。為了命名字符的范圍,使用一個“-”。“[a-z]”匹配任何字母,而“[0-9]”匹配任何數字。
· “ * ”匹配零個或多個在它前面的字符。例如,“x*”匹配任何數量的“x”字符,“[0-9]*”匹配任何數量的數字,而“.*”匹配任何數量的任何字符。
如果REGEXP模式與被測試值的任何地方匹配,模式就匹配(這不同於LIKE模式匹配,只有與整個值匹配,模式才匹配)。
為了定位一個模式以便它必須匹配被測試值的開始或結尾,在模式開始處使用“^”或在模式的結尾用“$”。
為了說明擴展正則表達式如何工作,下面使用REGEXP重寫上面所示的LIKE查詢:
為了找出以“b”開頭的名字,使用“^”匹配名字的開始:
mysql> SELECT * FROM pet WHERE name REGEXP ‘^b';
+——–+——–+———+——+————+————+
| name| owner | species | sex | birth | death |
+——–+——–+———+——+————+————+
| Buffy | Harold | dog| f | 1989-05-13 | NULL|
| Bowser | Diane | dog| m | 1989-08-31 | 1995-07-29 |
+——–+——–+———+——+————+————+
如果你想強制使REGEXP比較區分大小寫,使用BINARY關鍵字使其中一個字符串變為二進制字符串。該查詢只匹配名稱首字母的小寫‘b'。
mysql> SELECT * FROM pet WHERE name REGEXP BINARY ‘^b';
為了找出以“fy”結尾的名字,使用“$”匹配名字的結尾:
mysql> SELECT * FROM pet WHERE name REGEXP ‘fy$';
+——–+——–+———+——+————+——-+
| name| owner | species | sex | birth | death |
+——–+——–+———+——+————+——-+
| Fluffy | Harold | cat| f | 1993-02-04 | NULL |
| Buffy | Harold | dog| f | 1989-05-13 | NULL |
+——–+——–+———+——+————+——-+
為了找出包含一個“w”的名字,使用以下查詢:
mysql> SELECT * FROM pet WHERE name REGEXP ‘w';
+———-+——-+———+——+————+————+
| name| owner | species | sex | birth | death |
+———-+——-+———+——+————+————+
| Claws | Gwen | cat| m | 1994-03-17 | NULL|
| Bowser| Diane | dog| m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL|
+———-+——-+———+——+————+————+
既然如果一個正則表達式出現在值的任何地方,其模式匹配了,就不必在先前的查詢中在模式的兩側放置一個通配符以使得它匹配整個值,就像你使用了一個SQL模式那樣。
為了找出包含正好5個字符的名字,使用“^”和“$”匹配名字的開始和結尾,和5個“.”實例在兩者之間:
mysql> SELECT * FROM pet WHERE name REGEXP ‘^…..$';
+——-+——–+———+——+————+——-+
| name | owner | species | sex | birth | death |
+——-+——–+———+——+————+——-+
| Claws | Gwen| cat| m | 1994-03-17 | NULL |
| Buffy | Harold | dog| f | 1989-05-13 | NULL |
+——-+——–+———+——+————+——-+
你也可以使用“{n}”“重復n次”操作符重寫前面的查詢:
mysql> SELECT * FROM pet WHERE name REGEXP ‘^.{5}$';
+——-+——–+———+——+————+——-+
| name | owner | species | sex | birth | death |
+——-+——–+———+——+————+——-+
| Claws | Gwen| cat| m | 1994-03-17 | NULL |
| Buffy | Harold | dog| f | 1989-05-13 | NULL |
+——-+——–+———+——+————+——-+
附錄G:MySQL正則表達式 提供了關於正則表達式的句法的詳細信息。
3.3.4.8. 計數行數據庫經常用於回答這個問題,“某個類型的數據在表中出現的頻度?”例如,你可能想要知道你有多少寵物,或每位主人有多少寵物,或你可能想要對你的動物進行各種類型的普查。
計算你擁有動物的總數目與“在pet表中有多少行?”是同樣的問題,因為每個寵物有一個記錄。COUNT(*)函數計算行數,所以計算動物數目的查詢應為:
mysql> SELECT COUNT(*) FROM pet;
+———-+
| COUNT(*) |
+———-+
| 9 |
+———-+
在前面,你檢索了擁有寵物的人的名字。如果你想要知道每個主人有多少寵物,你可以使用COUNT( )函數:
mysql> SELECT owner, COUNT(*) FROM pet GROUP BY owner;
+——–+———-+
| owner | COUNT(*) |
+——–+———-+
| Benny | 2 |
| Diane | 2 |
| Gwen| 3 |
| Harold | 2 |
+——–+———-+
注意,使用GROUP BY對每個owner的所有記錄分組,沒有它,你會得到錯誤消息:
mysql> SELECT owner, COUNT(*) FROM pet;
ERROR 1140 (42000): Mixing of GROUP columns (MIN(),MAX(),COUNT(),…)
with no GROUP columns is illegal if there is no GROUP BY clause
COUNT( )和GROUP BY以各種方式分類你的數據。下列例子顯示出進行動物普查操作的不同方式。
每種動物的數量:
mysql> SELECT species, COUNT(*) FROM pet GROUP BY species;
+———+———-+
| species | COUNT(*) |
+———+———-+
| bird | 2 |
| cat| 2 |
| dog| 3 |
| hamster | 1 |
| snake| 1 |
+———+———-+
每種性別的動物數量:
mysql> SELECT sex, COUNT(*) FROM pet GROUP BY sex;
+——+———-+
| sex | COUNT(*) |
+——+———-+
| NULL | 1 |
| f | 4 |
| m | 4 |
+——+———-+
(在這個輸出中,NULL表示“未知性別”。)
按種類和性別組合的動物數量:
mysql> SELECT species, sex, COUNT(*) FROM pet GROUP BY species, sex;
+———+——+———-+
| species | sex | COUNT(*) |
+———+——+———-+
| bird | NULL | 1 |
| bird | f | 1 |
| cat| f | 1 |
| cat| m | 1 |
| dog| f | 1 |
| dog| m | 2 |
| hamster | f | 1 |
| snake| m |1 |
+———+——+———-+
若使用COUNT( ),你不必檢索整個表。例如, 前面的查詢,當只對狗和貓進行時,應為:
mysql> SELECT species, sex, COUNT(*) FROM pet
-> WHERE species = ‘dog' OR species = ‘cat'
-> GROUP BY species, sex;
+———+——+———-+
| species | sex | COUNT(*) |
+———+——+———-+
| cat| f | 1 |
| cat| m | 1 |
| dog| f | 1 |
| dog| m | 2 |
+———+——+———-+
或,如果你僅需要知道已知性別的按性別的動物數目:
mysql> SELECT species, sex, COUNT(*) FROM pet
-> WHERE sex IS NOT NULL
-> GROUP BY species, sex;
+———+——+———-+
| species | sex | COUNT(*) |
+———+——+———-+
| bird | f | 1 |
| cat| f | 1 |
| cat| m | 1 |
| dog| f | 1 |
| dog| m | 2 |
| hamster | f | 1 |
| snake| m | 1 |
+———+——+———-+
3.3.4.9. 使用1個以上的表
pet表追蹤你有哪個寵物。如果你想要記錄其它相關信息,例如在他們一生中看獸醫或何時後代出生,你需要另外的表。這張表應該像什麼呢?需要:
· 它需要包含寵物名字以便你知道每個事件屬於哪個動物。
· 需要一個日期以便你知道事件是什麼時候發生的。
· 需要一個描述事件的字段。
· 如果你想要對事件進行分類,則需要一個事件類型字段。
綜合上述因素,event表的CREATE TABLE語句應為:
mysql> CREATE TABLE event (name VARCHAR(20), date DATE,
-> type VARCHAR(15), remark VARCHAR(255));
對於pet表,最容易的方法是創建包含信息的用定位符分隔的文本文件來裝載初始記錄:
name
date
type
remark
Fluffy
1995-05-15
litter
4 kittens, 3 female, 1 male
Buffy
1993-06-23
litter
5 puppies, 2 female, 3 male
Buffy
1994-06-19
litter
3 puppies, 3 female
Chirpy
1999-03-21
vet
needed beak straightened
Slim
1997-08-03
vet
broken rib
Bowser
1991-10-12
kennel
Fang
1991-10-12
kennel
Fang
1998-08-28
birthday
Gave him a new chew toy
Claws
1998-03-17
birthday
Gave him a new flea collar
Whistler
1998-12-09
birthday
First birthday
采用如下方式裝載記錄:
mysql> LOAD DATA LOCAL INFILE ‘event.txt' INTO TABLE event;
根據你從已經運行在pet表上的查詢中學到的,你應該能執行對event表中記錄的檢索;原理是一樣的。但是什麼時候event表本身不能回答你可能問的問題呢?
當他們有了一窩小動物時,假定你想要找出每只寵物的年齡。我們前面看到了如何通過兩個日期計算年齡。event表中有母親的生產日期,但是為了計算母親的年齡,你需要她的出生日期,存儲在pet表中。說明查詢需要兩個表:
mysql> SELECT pet.name,
-> (YEAR(date)-YEAR(birth)) - (RIGHT(date,5)<RIGHT(birth,5)) AS age,
-> remark
-> FROM pet, event
-> WHERE pet.name = event.name AND event.type = ‘litter';
+——–+——+—————————–+
| name| age | remark |
+——–+——+—————————–+
| Fluffy | 2 | 4 kittens, 3 female, 1 male |
| Buffy | 4 | 5 puppies, 2 female, 3 male |
| Buffy | 5 | 3 puppies, 3 female|
+——–+——+—————————–+
關於該查詢要注意的幾件事情:
FROM子句列出兩個表,因為查詢需要從兩個表提取信息。
當從多個表組合(聯結)信息時,你需要指定一個表中的記錄怎樣能匹配其它表的記錄。這很簡單,因為它們都有一個name列。查詢使用WHERE子句基於name值來匹配2個表中的記錄。
因為name列出現在兩個表中,當引用列時,你一定要指定哪個表。把表名附在列名前即可以實現。
你不必有2個不同的表來進行聯結。如果你想要將一個表的記錄與同一個表的其它記錄進行比較,可以將一個表聯結到自身。例如,為了在你的寵物之中繁殖配偶,你可以用pet聯結自身來進行相似種類的雄雌配對:
mysql> SELECT p1.name, p1.sex, p2.name, p2.sex, p1.species
-> FROM pet AS p1, pet AS p2
-> WHERE p1.species = p2.species AND p1.sex = ‘f' AND p2.sex = ‘m';
+——–+——+——–+——+———+
| name| sex | name| sex | species |
+——–+——+——–+——+———+
| Fluffy | f | Claws | m | cat|
| Buffy | f | Fang| m | dog|
| Buffy | f | Bowser | m | dog|
+——–+——+——–+——+———+
在這個查詢中,我們為表名指定別名以便能引用列並且使得每一個列引用與哪個表實例相關聯更直觀。
3.4. 獲得數據庫和表的信息如果你忘記數據庫或表的名字,或給定的表的結構是什麼(例如,它的列叫什麼),怎麼辦?MySQL通過提供數據庫及其支持的表的信息的幾個語句解決這個問題。
你已經見到了SHOW DATABASES,它列出由服務器管理的數據庫。為了找出當前選擇了哪個數據庫,使用DATABASE( )函數:
mysql> SELECT DATABASE();
+————+
| DATABASE() |
+————+
| menagerie |
+————+
如果你還沒選擇任何數據庫,結果是NULL。
為了找出當前的數據庫包含什麼表(例如,當你不能確定一個表的名字),使用這個命令:
mysql> SHOW TABLES;
+———————+
| Tables in menagerie |
+———————+
| event|
| pet|
+———————+
如果你想要知道一個表的結構,可以使用DESCRIBE命令;它顯示表中每個列的信息:
mysql> DESCRIBE pet;
+———+————-+——+—–+———+——-+
| Field| Type | Null | Key | Default | Extra |
+———+————-+——+—–+———+——-+
| name | varchar(20) | YES || NULL ||
| owner| varchar(20) | YES || NULL ||
| species | varchar(20) | YES || NULL | |
| sex| char(1)| YES || NULL ||
| birth| date | YES || NULL ||
| death| date | YES || NULL ||
+———+————-+——+—–+———+——-+
Field顯示列名字,Type是列的數據類型,Null表示列是否能包含NULL值,Key顯示列是否被索引而Default指定列的默認值。
如果表有索引,SHOW INDEX FROM tbl_name生成有關索引的信息。
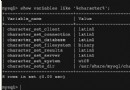
今天在做mysql的一個搜索的時候發現我用 select name from contact where name like ‘%a%'的時候出來的結果除了包含a的名字外連包含中文“新”的名字也出現在搜索結果裡面,這令我想弄清楚mysql的匹配模式和規則到底是怎麼樣的, 所以決定查查資料了解了解,另外在匹配的時候正則表達式也很常用!所以准備在這裡記錄我學習這兩個玩意的收獲!
出現這個問題的原因是:MySQL在查詢字符串時是大小寫不敏感的,在編繹MySQL時一般以ISO-8859字符集作為默認的字符集,因此在比較過程中中文編碼字符大小寫轉換造成了這種現象。
解決辦法
1.在建表的時候對於包含中文的字段加上“BINARY”屬性,使之進行二進制比較,例如講″name char(10)”改成”name char(10) BINARY”。但是這樣你對該表的該字段進行匹配的時候是區分大小寫的。
2. 如果使用源碼編譯MySQL,可以在編譯的時候使用–with–charset=gbk參數,這樣mysql就直接支持中文查找和排序。
3. 使用mysql的locate函數來判斷。如:
SELECT * FROM table WHERE locate(substr,str)>0 ;
locate()有兩個形式:LOCATE(substr,str), LOCATE(substr,str,pos)。返回substr在str中的位置,如果str不包含substr返回0。這個函數也是不區分大小寫的。
4.這樣使用sql語句:SELECT * FROM TABLE WHERE FIELDS LIKE BINARY ‘%FIND%',但是這和1一樣是區分大小寫的如果你想進行不區分大小寫的查詢的時候就要使用upper或者lower進行轉換。
5.使用 binary和ucase函數及concat函數。ucase是講英文全部轉換大寫,concat對字符串進行連接。新的sql語句如下:
select id,title,name from achech_com.news where binary ucase(title) like concat('%',ucase('a'),'%')
也可以寫為select id,title,name from achech_com.news where binary ucase(title) like ucase('%a%')
檢索的結果還算滿意吧,不過速度可能會因此而慢N毫秒喔。 因為使用like和%進行匹配的話對效率會有一定的影響。
正則表達式:
正則表達式是為復雜搜索指定模式的強大方式。
^
所匹配的字符串以後面的字符串開頭
mysql> select “fonfo” REGEXP “^fo$”; -> 0(表示不匹配)
mysql> select “fofo” REGEXP “^fo”; -> 1(表示匹配)
$
所匹配的字符串以前面的字符串結尾
mysql> select “fono” REGEXP “^fono$”; -> 1(表示匹配)
mysql> select “fono” REGEXP “^fo$”; -> 0(表示不匹配)
.
匹配任何字符(包括新行)
mysql> select “fofo” REGEXP “^f.*”; -> 1(表示匹配)
mysql> select “fonfo” REGEXP “^f.*”; -> 1(表示匹配)
a*
匹配任意多個a(包括空串)
mysql> select “Ban” REGEXP “^Ba*n”; -> 1(表示匹配)
mysql> select “Baaan” REGEXP “^Ba*n”; -> 1(表示匹配)
mysql> select “Bn” REGEXP “^Ba*n”; -> 1(表示匹配)
a+
匹配1個或多個a字符的任何序列。
mysql> select “Ban” REGEXP “^Ba+n”; -> 1(表示匹配)
mysql> select “Bn” REGEXP “^Ba+n”; -> 0(表示不匹配)
a?
匹配一個或零個a
mysql> select “Bn” REGEXP “^Ba?n”; -> 1(表示匹配)
mysql> select “Ban” REGEXP “^Ba?n”; -> 1(表示匹配)
mysql> select “Baan” REGEXP “^Ba?n”; -> 0(表示不匹配)
de|abc
匹配de或abc
mysql> select “pi” REGEXP “pi|apa”; -> 1(表示匹配)
mysql> select “axe” REGEXP “pi|apa”; -> 0(表示不匹配)
mysql> select “apa” REGEXP “pi|apa”; -> 1(表示匹配)
mysql> select “apa” REGEXP “^(pi|apa)$”; -> 1(表示匹配)
mysql> select “pi” REGEXP “^(pi|apa)$”; -> 1(表示匹配)
mysql> select “pix” REGEXP “^(pi|apa)$”; -> 0(表示不匹配)
(abc)*
匹配任意多個abc(包括空串)
mysql> select “pi” REGEXP “^(pi)*$”; -> 1(表示匹配)
mysql> select “pip” REGEXP “^(pi)*$”; -> 0(表示不匹配)
mysql> select “pipi” REGEXP “^(pi)*$”; -> 1(表示匹配)
{1} {2,3}
這是一個更全面的方法,它可以實現前面好幾種保留字的功能
a*
可以寫成a{0,}
a
可以寫成a{1,}
a?
可以寫成a{0,1}
在{}內只有一個整型參數i,表示字符只能出現i次;在{}內有一個整型參數i,
後面跟一個“,”,表示字符可以出現i次或i次以上;在{}內只有一個整型參數i,
後面跟一個“,”,再跟一個整型參數j,表示字符只能出現i次以上,j次以下
(包括i次和j次)。其中的整型參數必須大於等於0,小於等於 RE_DUP_MAX(默認是25
5)。 如果同時給定了m和n,m必須小於或等於n.
[a-dX], [^a-dX]
匹配任何是(或不是,如果使用^的話)a、b、c、d或X的字符。兩個其他字符之間的“-”字符構成一個范圍,與從第1個字符開始到第2個字符之間的所有字符匹配。例如,[0-9]匹配任何十進制數字 。要想包含文字字符“]”,它必須緊跟在開括號“[”之後。要想包含文字字符“-”,它必須首先或最後寫入。對於[]對內未定義任何特殊含義的任何字符,僅與其本身匹配。
mysql> select “aXbc” REGEXP “[a-dXYZ]“; -> 1(表示匹配)
mysql> select “aXbc” REGEXP “^[a-dXYZ]$”; -> 0(表示不匹配)
mysql> select “aXbc” REGEXP “^[a-dXYZ] $”; -> 1(表示匹配)
mysql> select “aXbc” REGEXP “^[^a-dXYZ] $”; -> 0(表示不匹配)
mysql> select “gheis” REGEXP “^[^a-dXYZ] $”; -> 1(表示匹配)
mysql> select “gheisa” REGEXP “^[^a-dXYZ] $”; -> 0(表示不匹配)
[[.characters.]]
表示比較元素的順序。在括號內的字符順序是唯一的。但是括號中可以包含通配符,
所以他能匹配更多的字符。舉例來說:正則表達式[[.ch.]]*c匹配chchcc的前五個字符
。
[=character_class=]
表示相等的類,可以代替類中其他相等的元素,包括它自己。例如,如果o和( )是
一個相等的類的成員,那麼[[=o=]]、[[=( )=]]和[o( )]是完全等價的。
[:character_class:]
在括號裡面,在[: 和:]中間是字符類的名字,可以代表屬於這個類的所有字符。
字符類的名字有: alnum、digit、punct、alpha、graph、space、blank、lower、uppe
r、cntrl、print和 xdigit
mysql> select “justalnums” REGEXP “[[:alnum:]] “; -> 1(表示匹配)
mysql> select “!!” REGEXP “[[:alnum:]] “; -> 0(表示不匹配)
alnum 文字數字字符
alpha 文字字符
blank 空白字符
cntrl 控制字符
digit 數字字符
graph 圖形字符
lower 小寫文字字符
print 圖形或空格字符
punct 標點字符
space 空格、制表符、新行、和回車
upper 大寫文字字符
xdigit 十六進制數字字符
[[:<:]]
[[:>:]]
分別匹配一個單詞開頭和結尾的空的字符串,這個單詞開頭和結尾都不是包含在alnum中
的字符也不能是下劃線。
mysql> select “a word a” REGEXP “[[:<:]]word[[:>:]]”; -> 1(表示匹配)
mysql> select “a xword a” REGEXP “[[:<:]]word[[:>:]]”; -> 0(表示不匹配)
mysql> select “weeknights” REGEXP “^(wee|week)(knights|nights)$”; -> 1(表示
匹配)
要想在正則表達式中使用特殊字符的文字實例,應在其前面加上2個反斜槓“\”字符。MySQL解析程序負責解釋其中一個,正則表達式庫負責解釋另一個。例如,要想與包含特殊字符“+”的字符串“1+2” 匹配,在下面的正則表達式中,只有最後一個是正確的:
mysql> SELECT ‘1+2′ REGEXP ‘1+2′; -> 0
mysql> SELECT ‘1+2′ REGEXP ‘1\+2′; -> 0
mysql> SELECT ‘1+2′ REGEXP ‘1\\+2′; -> 1