今天在我的虛擬機中布置了環境,測試抓圖如下:
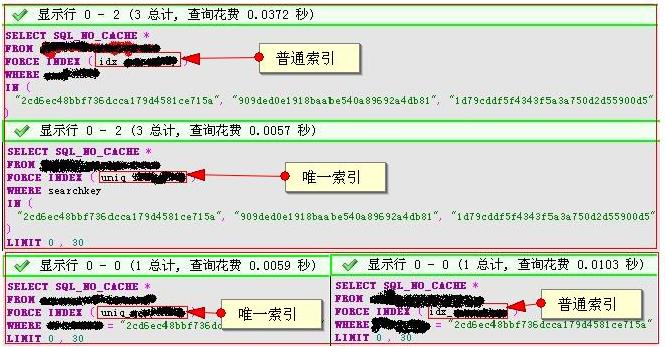
抓的這幾個都是第一次執行的,刷了幾次後,取平均值,效率大致相同,而且如果在一個列上同時建唯一索引和普通索引的話,mysql會自動選擇唯一索引。
谷歌一下:
唯一索引和普通索引使用的結構都是B-tree,執行時間復雜度都是O(log n)。
補充下概念:
1、普通索引
普通索引(由關鍵字KEY或INDEX定義的索引)的唯一任務是加快對數據的訪問速度。因此,應該只為那些最經常出現在查詢條件(WHEREcolumn=)或排序條件(ORDERBYcolumn)中的數據列創建索引。只要有可能,就應該選擇一個數據最整齊、最緊湊的數據列(如一個整數類型的數據列)來創建索引。
2、唯一索引
普通索引允許被索引的數據列包含重復的值。比如說,因為人有可能同名,所以同一個姓名在同一個“員工個人資料”數據表裡可能出現兩次或更多次。
如果能確定某個數據列將只包含彼此各不相同的值,在為這個數據列創建索引的時候就應該用關鍵字UNIQUE把它定義為一個唯一索引。這麼做的好處:一是簡化了MySQL對這個索引的管理工作,這個索引也因此而變得更有效率;二是MySQL會在有新記錄插入數據表時,自動檢查新記錄的這個字段的值是否已經在某個記錄的這個字段裡出現過了;如果是,MySQL將拒絕插入那條新記錄。也就是說,唯一索引可以保證數據記錄的唯一性。事實上,在許多場合,人們創建唯一索引的目的往往不是為了提高訪問速度,而只是為了避免數據出現重復。
注:
終於找到同事說執行效率不一樣的原因了,他在普通索引上創建的是前綴索引,只取了前16個字節,而唯一索引使用的全字節 :)