先簡單介紹一下項目背景。這是一個在線考試練習平台,數據庫使用MySQL,表結構如圖所示:
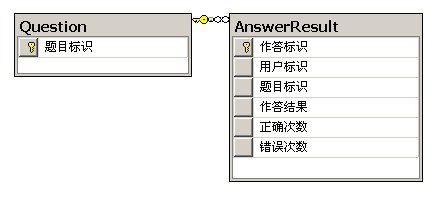
Question是存儲題目的表,數據量在3萬左右。AnswerResult表是存儲用戶作答結果的表,分表之後單表記錄大概在300萬-400萬。
需求:根據用戶的作答結果出練習卷,題目的優先級為:未做過的題目>只做錯的題目>做錯又做對的題目>只做對的題目。
在“做錯又做對的題目”中,會按錯誤次數和正確次數的比例進行權重計算,比如:A、做錯10次,做對100次;B、做錯10次,做對20次。這時B被選中出給用戶練習的概率就大。
備注:AnswerResult表中不存在QuestionId的記錄,則代表該題沒有做過。
之前使用的方法:
SELECT Question.題目標識,IFNULL((0-正確次數)/(正確次數+錯誤次數),1) AS 權重 FROM Question
LEFT JOIN AnswerResult ON AnswerResult.題目標識 = Question.題目標識
WHERE 用戶標識={UserId}
說明:IFNULL((0-正確次數)/(正確次數+錯誤次數),1)這個函數式分2部分,
公式:(0-正確次數)/(正確次數+錯誤次數)得到題目的權重,這個區間為[0,-1],0表示只做錯的題目,-1表示只做對的題目。IFNULL(value,1)則將未做過的題目權重設置為1,根據這個權重進行排序列出題目。
由於AnswerResult表是多達300、400百萬的表,所以通過LEFT JOIN進行左連接時,迪卡爾乘積過大,又加上AnswerResult是頻繁讀寫的表,很容易導致這條SQL變成慢查詢。
性能問題被提上日程後,這條SQL語句就變成的優化點。
1、IFNULL()這個函數計算可以調整成冗余字段。
2、LEFT JOIN的迪卡爾乘積太大,可以調整為冗余或者使用INNER JOIN以提高查詢速度。
3、根據需求,其實可以調整出題策略,不同的情況執行不同的SQL,而不需要在同一條SQL中實現。
解決方案針對以上三個點進行調整。雖然Question表有3萬條數據,但是出題的場景其實是針對知識點出題,單個知識點題目最多也只有1000題左右,所以獲取未做過的題目時,完全可以使用NOT IN走索引來完成。SQL語句如:
A:SELECT 題目標識 FROM Question WHERE 知識點={KnowledgePointCode} AND 題目標識 NOT IN (
SELECT 題目標識 FROM AnswerResult INNER JOIN Question AND Question.知識點={KnowledgePointCode}
WHERE AnswerResult.用戶標識 = {UserId}
)
針對只做錯的題目出題練習就簡單了(正確次數 = 0代表只做錯),SQL如:
B:SELECT 題目標識 FROM AnswerResult INNER JOIN Question AND Question.知識點={KnowledgePointCode}
WHERE AnswerResult.用戶標識 = {UserId} AND 正確次數 = 0 ORDER BY 錯誤次數 DESC
若要對做錯、做對或者只做對的題目進行出題,SQL就是這樣的(已經對權重進行冗余=IFNULL((0-正確次數)/(正確次數+錯誤次數),1)):
C:SELECT 題目標識 FROM AnswerResult INNER JOIN Question AND Question.知識點={KnowledgePointCode}
WHERE AnswerResult.用戶標識 = {UserId} AND 正確次數 > 0 ORDER BY 權重 DESC
不足:SQL語句A的查詢速度依然是較慢的,雖然有縮小NOT IN的結果集,但這裡還是有優化點。園子裡的朋友們能不能給點建議?
有人說JOIN是SQL的性能殺手,我覺得主要還是怎麼去使用JOIN,MySQL的索引優化相當重要,如果JOIN成為性能瓶頸,可以EXPLAIN看看是不是索引沒有建好,並且盡量讓迪卡爾乘積盡量小。使用冗余數據避免JOIN,當可能變化的冗余數據被分表之後,更新這些冗余數據就是一件非常頭痛的事了。海量數據高並發,確實是一件挺頭痛的事。
望園子裡有這方面經驗的朋友不吝賜教。謝謝。