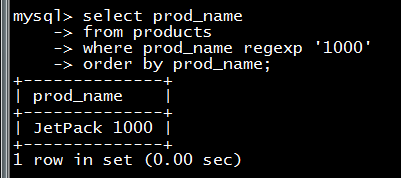
在以下幾種條件下,MySQL就會做全表掃描:
1>數據表是在太小了,做一次全表掃描比做索引鍵的查找來得快多了。當表的記錄總數小於10且記錄長度比較短時通常這麼做。
2>沒有合適用於 ON 或 WHERE 分句的索引字段。
3>讓索引字段和常量值比較,MySQL已經計算(基於索引樹)到常量覆蓋了數據表的很大部分,因此做全表掃描應該會來得更快。
4>通過其他字段使用了一個基數很小(很多記錄匹配索引鍵值)的索引鍵。這種情況下,MySQL認為使用索引鍵需要大量查找,還不如全表掃描來得更快。
對於小表來說,全表掃描通常更合適。但是對大表來說,嘗試使用以下技術來避免讓優化程序錯誤地選擇全表掃描:
1>執行 ANALYZE TABLE tbl_name 更新要掃描的表的索引鍵分布。
2> 使用 FORCE INDEX 告訴MySQL,做全表掃描的話會比利用給定的索引更浪費資源。
SELECT * FROM t1, t2 FORCE INDEX (index_for_column)
WHERE t1.col_name=t2.col_name;
3>啟動 mysqld 時使用參數 --max-seeks-for-key=1000 或者執行 SET max_seeks_for_key=1000 來告訴優化程序,所有的索引都不會導致超過1000次的索引搜索。