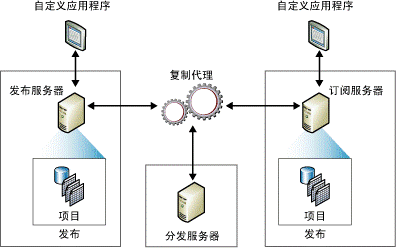
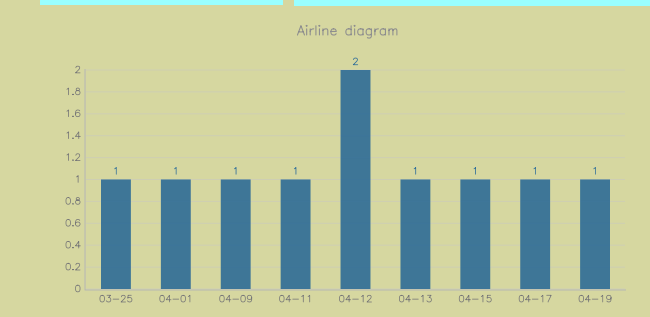
今天在我的虛擬機中布置了環境,測試抓圖如下:抓的這幾個都是第
最近做的一個項目要獲取存在於其他服務器的一些
在終端用cd 命令進入文件目錄 說明:此處例子我是拿項目中的
1. 下載:http://dev.mysql.com/dow
下面的是MySQL安裝的圖解,用的可執行文件安裝的,
MySQL服務器端的參數有很多,但是對於大多數初學者來說,眾