在MySQL數據庫中,表的不同部分在不同的位置被存儲為單獨的表。分區主要就是用來解決表在不同的位置存儲的問題。在其他數據庫中,也會存在這種情況。他們將這種類型的數據表稱之為分區表。分區的管理,對於MySQL數據庫來說至關重要。其直接跟數據庫的性能與安全性息息相關。對於分區的管理,筆者只有兩個字:細節。
細節一:確定所使用的版本是否支持分區
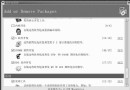
在MySQL中,並不是所有的數據庫版本都支持分區管理。為此數據庫管理員首先要做的就是,確認自己所采用的版本是否支持這個功能。如果支持的話,則可以在後續設計與維護時利用分區的特性來提升系統性能、提高數據安全。反之,則不行。要判斷所使用的版本是否支持分區功能,可以通過系統命令來實現。如下圖所示:
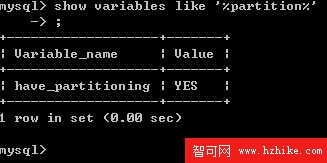
如果上面這個變量,其顯示的值是YES,那麼很慶幸的告訴你,你說是用的版本支持分區管理。如果這個變量的值是空白的,則表示所使用的版本不支持分區管理。筆者建議對現有的數據庫版本進行升級。
對於分區管理,筆者需要強調一點,即MySQL數據庫與其他數據庫在分區實現上的差異。對於MySQL數據庫來說,主要是通過分區函數來實現分區的控制。如這可能是一個HASH函數、或者一個數值列表。雖然數據庫管理員並不需要非常了解其內部的實現機制。但是需要明確的是,采用不同的分區類型,就選擇了不同的分區函數。反過來說,分區函數的特征就確定了所選擇分區的特性。從這個角度來講,掌握函數的一些基本特征,可以幫助我們更好的理解不同類型分區之間的差異。從而有利於數據庫管理員根據企業的實際情況來設計合理的分區。
細節二:存儲引擎與分區之間的關系
存儲引擎主要用來實現對數據庫數據的存儲。顯然這個存儲引擎與分區之間有著緊密的聯系。這個聯系主要體現在如下這個方面。
通常情況下,對於創建了分區的數據表,數據庫管理員可以使用數據庫服務器所支持的任何存儲引擎。也就是說,對於數據引擎來說,分區是透明的。這主要是因為在MySQL數據庫中,分區引擎是在一個單獨的層中運行的。並且可以和任何這樣的層進行相互溝通。不過如果再深挖下去的話,這裡仍然有一個細節問題需要考慮,即需要注意一個限制的規則。對於同一個分區表的所有分區都必須使用同一個存儲引擎。舉一個簡單的例子。現在有一個數據表,其有兩個數據分區,分別為A與B。此時如果數據庫管理員對於分區A采用了MYISAM;那麼對於分區B也只能夠使用MYISAM,而不能夠使用其它的,如INNODB。
這段話看起來好像有點互相矛盾的地方。其實我們可以將其總結為一句話。即不同的分區表,可以采用任何數據庫所支持的數據引擎。但是對於同一個數據表的不同分區,則只能夠使用同一個存儲引擎。
最後需要說明的是,從存儲引擎的相關信息中,並不能夠看出其服務的數據表是否支持分區的功能。也就是說,不能夠通過命令show engines來判斷數據庫是否支持分區。數據庫管理員只能夠通過上面的第一個命令來判斷數據庫分區的相關信息。
細節三:分區是一個整體,不能夠進行分割
一個數據表可以根據實際情況分為多個分區。但是分割後的分區仍然是一個整體。這是什麼意思呢?筆者舉一個例子,各位就可以理解了。現在有一個數據表,表中有記錄和索引。在進行分區設計時,不能夠只對數據分區而不對索引分區,也不能夠對索引分區而不對數據分區。這就好像是分蛋糕一樣。蛋糕會有上下兩層。在分蛋糕時,是上下兩層一起分。而不會只分上面一層奶油。為此需要切記,分區時是對數據表中的所有內容進行同時分區,而不能夠對部分進行分區。
另外需要注意的是,如果要對某個表進行分區,那麼就需要對整個表進行分區管理。而不能夠對部分進行分區。如對某個表的上半部分不執行分區,而只對下半部分進行分區管理,這是不允許的。
細節四:分區如何提高查詢效率
采用分區管理,可以很好的提高查詢的效率。筆者這裡舉一個零售企業的案例。如現在有一家超市,使用的是MySQL數據庫。一家超市,每年的銷售記錄會有幾千萬條。幾年累積下來,數據量非常的大。現在如果用戶需要查詢,去年一年某個產品的銷售情況,那就像大海撈針一樣,速度會非常的慢。
此時如果采用分區管理的話,會明顯的提高查詢的效率。在數據庫設計的時候,可以根據時間來劃分分區。如為每一年的數據單獨設置一個分區。此時再查詢2010年某個產品的銷售情況時,由於指定了Where條件語句,則系統只會從2010年這個數據分區中去查找相關的內容,而會忽略其他無關的分區,從而改善數據查詢效率。
在實際工作中,筆者還經常將某個表分為多個分區,然後將不同的分區放置在不同的磁盤上。此時可以通過多個硬盤來分散數據查詢,來獲得更大的查詢吞吐量。如果企業數據庫服務器中,已經使用了磁盤陣列5的話,采取這個措施就是多此一舉。如果服務器中只有一塊硬盤、或者雖然有多快硬盤但是沒有實現磁盤陣列的話,筆者將多個分區存放在多快硬盤上的做法,還是蠻值得推薦的。如還是以零售企業為例。如果企業一年的銷售記錄有上億條。此時要對這上億條的數據進行統計分析,對於硬盤的吞吐量是一個極大的考驗。此時我們可以對這個數據表進行分區。如可以根據季度將其分為四個區A、B、C、D。然後將AC兩個分區放在硬盤甲上,將剩余的BD兩個分區放在硬盤乙上。此時系統在讀取整年的數據時,會同時從兩塊硬盤上讀取數據。這麼設計的話,硬盤的吞吐量就可以提高一倍(假設不考慮管理開銷)。通過這種方式,也可以提高查詢的效率。其與磁盤陣列5有異曲同工之妙。只是其實現的級別不同。
可見采用分區之後,一些查詢能夠得到很大的優化。這主要是因為用戶可以借助於滿足一個給定的Where語句的數據可以只保存在某個特定的分區內(如2010年的交易數據)。如此在查詢時就不用再查找其他剩余的分區。雖然說分區可以在創建了分區表之後再進行修改。即使剛開始沒有考慮到這個內容,也可以在以後有需要的時候重新組織數據,對數據表進行分區。但是筆者並不贊成這麼做。因為對數據進行重新組織,就好像是重新剪貼、復制了一遍數據。在記錄比較多時,這個作業會大量的消耗服務器的資源。為此筆者還是建議,在數據庫設計時,管理員就需要對未來的數據量能夠進行預測。如果有必要采用分區管理的,那麼要提早做。
當然分區並不是對所有的企業都適用。如果企業的數據量比較少,又或者說大部分是一次性使用的數據,此時采用分區的話,不會給企業帶來價值。反而會增加管理上的開銷。