DBI 數據類型
從某些方面來說,使用Perl DBI API 類似於使用第6章介紹的C 客戶機庫。在使用C 客戶機庫時,主要依靠指向結構或數組的指針來調用函數和訪問與MySQL相關的數據。在使用DBI API 時,除了函數稱為方法,指針稱為引用外,也調用函數和使用指向結構的指針。
指針變量稱為句柄,句柄指向的結構稱為對象。
DBI 使用若干種句柄。它們往往通過表7-1所示的慣用名稱在DBI 文件中引用。而慣用的非句柄變量的名稱如表7 - 2所示。實際上,在本章中,我們並不使用每個變量名,但是,在閱讀其他人編寫的DBI 腳本時,了解它們是有用的。
表7-1慣用的Perl DBI 句柄變量名 名稱說明$dbh數據庫對象的句柄$sth語句(查詢)對象的句柄$fh打開文件的句柄$h“通用”句柄;其意義取決於上下文
表7-2 慣用的Perl DBI 非句柄變量的名稱
名稱說明$rc從返回真或假的操作中返回的代碼$rv從返回整數的操作中返回的值$rows從返回行數的操作中返回的值@ary查詢返回的表示一行值的數組(列表)一個簡單的DBI 腳本
讓我們從一個簡單腳本d um p _ member s開始,它舉例說明了DBI 程序設計中若干標准概念,如與MySQL服務器的連接和斷開、檢索數據等。此腳本產生的結果為以制表符分隔形式列出的歷史同盟成員。這個格式本身並不讓人感興趣:在這裡,了解如何使用DBI 比產生漂亮的輸出更為重要。
dump_members 如下:

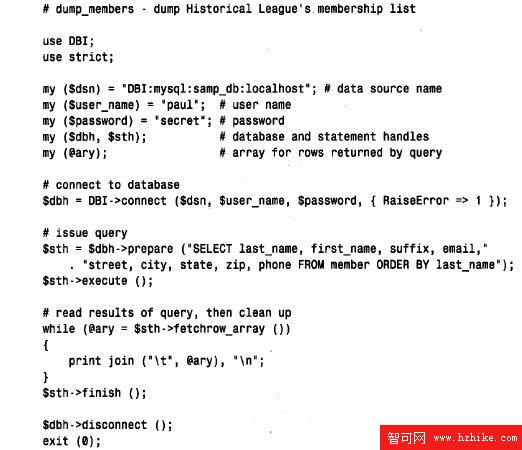
要想自己試驗這個腳本,可以下載它(請參閱符錄A),或使用文本編輯器創建它,然後使之可執行,以便能運行。當然,可能至少需要更改一些連接參數(主機名、數據庫名、用戶名和口令)。本章中的其他DBI 腳本也是這樣。在參數缺省時,本章下載腳本的權限設置為只允許讀。如果您將自己的MySQL用戶名和口令放在它們之中,我建議將它們保留為這種方式,以便其他人不能讀取這些值。以後,在7 . 2 . 8節“指定連接參數”中,我們將看到如何從選項文件中獲得這些參數,而不是將它們直接放在腳本中。
現在,讓我們逐行看完這個腳本。第一行是標准行,指出哪裡可以找到Perl 的指示器:
#! /usr/bin/perl
在本章將要討論的腳本中,每個腳本都包含這行;以後不再說明。此腳本中至少應該含有一個簡短的目的說明,這是一個好主意,所以下一行是一個注釋,給閱讀此腳本的人提供一個關於它做什麼的線索:
# dump_members.dump Historical League's membership list
從‘#’字符到行尾部的文本為注釋。有必要做一些練習,就是在整個腳本中編寫一些注釋來解釋它們如何工作。
接下來是兩個use 行:
use DBI;
use strict;
use DBI 告知Perl 解釋程序它需要引入DBI 模塊。如果沒有這一行,試圖在腳本中做與DBI 相關的任何事,都將出現錯誤。不需要指出想要哪個DBD 級別的模塊。在連接數據庫時,DBI 會激活相應的模塊。
use strict 告知Perl,在使用它們之前需要聲明變量。如果沒有use strict 行,也可以編寫腳本,但是,它有助於發現錯誤,所以建議始終要包括這行。例如,置為嚴格模式時,如果聲明變量$ my _ v a r,但是之後錯誤地用$mv_var 來訪問,則在運行這個腳本時,將獲得下面的消息:
Global symbol "$mv_var" requires explicit package name at line n
這個消息會使您想,“怎麼了?$ m v _ v a r?我從未使用過這種名稱的變量!”,然後,找到腳本中的第n行,看是什麼問題,並改正它。如果不用嚴格模式, Perl 不會給出$ m v _ v a r;將只是簡單地按具有un d e f(未定義的)值的該名稱創建一個新的變量,並毫無動靜地使用它,然後,您會莫名其妙腳本為什麼不工作。
因為我們在嚴格模式下操作,所以我們將定義腳本使用的變量:

現在我們准備連接數據庫:
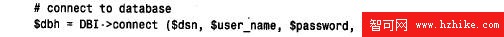
connect( ) 調用作為DBI->connect( ) 來調用,因為它是DBI 類的方法。不必真正知道它是什麼意思;它只是一個使人頭痛的面向對象的行話(如果的確想知道,那麼它意味著connect( ) 是“屬於”DBI 的一個函數)。connect( ) 有若干參數:
數據源。(經常調用的數據源名稱,或D S N。)數據源格式由要使用的特定DBD 模塊需求來確定。對於MySQL驅動程序,允許的格式如下:
"DBI:MySQL:db_name"
"DBI:MySQL:db_name:host_name"
對於第一種格式,主機名缺省為localhost(實際上有其他允許的數據源格式,我們將在後面7 . 2 . 8節“指定連接參數”中討論)。“DBI”大寫沒關系,但是“ MySQL”必須小寫。
用戶名和口令。
表示額外連接屬性的可選參數。這個參數控制DBI 的錯誤處理行為,我們指定的看起來有點奇怪的構造啟用了RaiseError 屬性。這導致DBI 檢查與數據庫相關的錯誤,並顯示消息,而且只要它檢測到錯誤就退出(這就是為什麼在dump_members 腳本中的任何地方都沒有看到錯誤檢查代碼的原因; DBI 將它全部處理了)。7 . 2 . 3節“處理錯誤”包括了對錯誤響應的可選方法。
如果connect( ) 調用成功,則它返回數據庫句柄,我們分配給$dbh(如果connect( ) 失敗,通常返回un d e f。然而,因為我們在腳本中啟用了R a i s e E r r o r,所以connect( )不返回;但是,DBI 將顯示一條錯誤消息,並且在出現錯誤時退出)。
連接到數據庫後, dump_members 發布一條SELECT 語句查詢來檢索全體成員列表,然後,執行一個循環來處理返回的每一行。這些行構成了結果集。
為了完成S E L E C T語句,首先需要准備,然後再運行它:
# issue query
$sth=$dbh->prepare("SELECT last_name,first_name,suffix,email,"
"street,city,state,zip,phone FROM member ORDER BY last_name");
$sth->execute();
利用數據庫句柄調用prepare( );在執行前,它將SQL 語句傳遞給預處理的驅動程序。實際上,在這裡某些驅動程序做了一些有關這條語句的事情。其他驅動程序只是記住它,直到調用execute( ) 使這條語句被執行為止。從prepare( ) 返回的值是一個語句句柄$ s t h,如果出現錯誤,則為un d e f。在進一步處理與這條語句相關的所有內容時,都使用這個語句句柄。
請注意,指定的這個查詢沒有分號結束符。您無疑有這樣的(經過長時間使用MySQL程序養成的)習慣,用‘ ;’字符終止SQL 語句。然而,在使用DBI時,最好打破這個習慣,因為分號經常導致查詢出現語法錯誤而失敗。向查詢增加‘ g’也類似,使用DBI時不要這樣。
在調用一個方法而不用向它傳遞任何參數時,可以沒有這個圓括號。下列兩個調用是等價的:
$sth->execute();
$sth->execute;
我寧願有圓括號,因為它使人感到這個調用看上去不像變量。您的選擇就可能不同了。
調用execute( ) 後,可以處理成員列表的行。在dump_members 腳本中,提取行的循環簡單地顯示了每行的內容:

fetchrow_array( ) 返回含有當前行的列值的數組,在沒有剩余的行時,返回一個空數組。這樣,此循環提取了由SELECT 語句返回的連續行,並顯示列值之間用制表符分隔的每一行。在數據庫中NULL 作為undef 值返回到Perl 腳本,但是將它們顯示為空字符串,而不是單詞“NULL”。
請注意,制表符和換行符(表示為‘ t’和‘ n’)括在雙引號中。在Perl 中,只解釋出現在雙引號內的轉義符序列,不解釋出現在單引號內的轉義符序列。如果使用單引號,則輸出將為字符串“ t”和“ n”。
提取行的循環終止以後,調用finish( ) 告知DBI 不再需要語句句柄,並且釋放分配給它的所有臨時資源。實際上,除非只提取結果集的一部分(無論是設計的原因,還是因為出現一些問題),否則不需要調用finish( )。然而,在提取循環之後, finish( ) 始終是很保險的,我認為調用並執行finish( ),比區分何時需要,何時不需要更容易一些。
我們已經顯示完了全部成員列表,所以我們可以從服務器上斷開連接,並且退出:
$dbh->disconnect();
exit(0);
dump_members 示出了許多DBI 程序的大多數通用概念,而且不必了解更多的知識,就可以著手編寫自己的DBI 程序。例如,要想寫出一些其他表的內容,所需要做的只是更改傳遞給prepare( ) 方法的SELECT 語句的文本。而且實際上,如果想了解這種技術的某些應用,可略過這部分,直接跳到7 . 3節“運行DBI”中討論如何生成歷史同盟一年一度的宴會成員列表程序和League 打印目錄的部分。然而,DBI 提供許多其他有用的功能。下一節介紹了一些,以便能夠在Perl 腳本中看看如何完成比運行一條簡單的SELECT 語句更多的事情。
處理錯誤
在dump_members 調用connect( )方法時,應該啟用RaiseError 錯誤處理屬性,以便這些錯誤用一條錯誤消息就能自動地終止相應的腳本。也可以用其他方式處理這些錯誤。例如,可以自己檢查錯誤而不必使用DBI。
為了查看如何控制DBI 的錯誤處理行為,我們來仔細查看一下connect( ) 調用的最終參數。下面兩個相關的屬性是RaiseError 和P r i n t E r r o r:
如果啟用R a i s e E r r o r(設為非零值),如果在DBI 方法中出現錯誤,則DBI 調用dIE( ) 來顯示一條消息並且退出。
如果啟用P r i n t E r r o r,在出現DBI錯誤時,DBI 會調用warn( ) 來顯示一條消息,但是相應腳本會繼續執行。
缺省時, RaiseError 是禁用的,而PrintError 啟用。在此情況下,如果connect( )調用失敗,則DBI 顯示一條消息,而且繼續執行。這樣,如果省略connect( ) 的四個參數,則得到缺省的錯誤處理行為,可以如下檢查錯誤:
$dbh=DBI->connect($dsn,$user_name,$passWord) or exit (1);
如果出現錯誤,則connect( ) 返回undef 表示失敗,並且觸發對exit( ) 的調用。因為DBI 已經顯示了錯誤消息,所以您就不一定要顯示它了。
如果明確給出該錯誤檢查屬性的缺省值,可如下調用connect( )。
$dbh=DBI->connect($dsn,$user_name,$passWord,{RaiseError=>0,PrintError=>1})
or exit (1);
這就需要更多的編寫工作,但是即使對不經意的讀者,處理錯誤行為也會更為明顯。
如果想自己檢查錯誤,並顯示自己的消息,應該禁用RaiseError 和P r i n t E r r o r:

變量$DBI::err 和$ DBI : :er r s t r,只用於所顯示的dIE( ) 調用中,有助於構造錯誤消息。它們含有MySQL錯誤代碼和錯誤字符串,非常像C API 函數中的mysql_errno( ) 和MySQL_error( )。
如果僅僅要DBI 處理錯誤,以便不必自己檢查它們,則啟用R a i s e E r r o r:
$dbh=DBI->connect ($dsn,$user_name,$passWord,{RaiseError=>1});
到目前為止,這是最容易的方法,並且是dump_members 帶來的。如果在腳本退出時,想要執行某種類型的清除代碼,啟用RaiseError 可能是不恰當的,盡管在這種情況下,可以重新定義$SIG{_DIE_} 句柄,可以做想做的事情。
避免啟用RaiseError 屬性的另一個原因是DBI 在它的消息中顯示技術信息,如下:
disconnect(DBI::db=HASH(0x197aae4)invalidates 1active statement.Either
destroy statement handles or call finish on them before disconnecting.
對於編程者來說,這是好的信息,但對普通用戶可能沒有什麼意義。在此情形,最好自己檢查錯誤,以便可以顯示對期望使用這個腳本的人更有意義的消息。或者也可在這裡考慮重新定義$SIG{_DIE_} 句柄。這樣可能很有用,因為它允許啟用RaiseError 來使錯誤處理簡單化,而不是用自己的消息替換DBI 給出的缺省錯誤消息。為了提供自己的_DIE_ 句柄,可在執行任何DBI 調用以前,進行下面的工作:
$SIG{_DIE_}=sub{dIE "Sorry,an error occurred ";};
也可以用普通的風格定義一個子例程,並利用這個子例程的引用來設置這個句柄值:

除了在connect( ) 調用中逐字傳遞錯誤處理屬性之外,還可以利用散列定義它們,並傳遞對這個散列的引用。有人發現以這種方式准備屬性設置使腳本更容易閱讀和編輯,但是在功能上這兩種方法是相同的。下面是一個說明如何使用屬性散列的樣例:
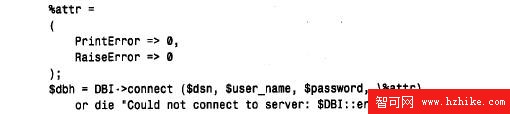
下面的腳本dump_members2 舉例說明了當要自己檢查錯誤並顯示自己的消息時,如何編寫腳本。dump_member2 處理和dump_members 一樣的查詢,但是明確地禁用PrintError 和R a i s e E r r o r,然後測試每個DBI 調用的結果。如果出現錯誤,在退出以前,腳本調用了子例程bail_out( ) 顯示消息及$DBI::err 和$DBI::errstr 的內容:


除了bail_out( ) 是退出而不是返回到調用者以外, bail_out( ) 類似於我們在第6章中為編寫C 程序使用的print_error( ) 函數。每次想顯示錯誤消息時, bail_out( ) 解除了寫出$DBI::err 和$DBI::errstr 名稱的麻煩。同樣,通過封裝顯示到子例程的錯誤消息,可更改子例程使整個腳本中錯誤消息的格式一致。
dump_member2 腳本在提取行循環的後面有一個測試,這是dump_members 所沒有的。因為如果在fetchrow_array( ) 中出現錯誤,dump_members2 不會自動地退出,所以人們判斷循環是因為結果集讀取完成而終止(正常終止),還是因為出現錯誤而終止做出確定是很困難的。當然,任何一種方式,循環都將終止,但是如果出現錯誤,則將刪截腳本的輸出。如果沒有錯誤檢查,運行該腳本的人將無法知道是否有錯!如果自己檢查錯誤,應該檢查提取循環的結果。
處理不返回結果集的查詢
D E L E T E、INSERT、REPLACE和UPDATE等執行後不返回行的語句比S E L E C T、DESCRIB、EXPLAIN 和SHOW 等執行後返回行的語句的處理相對要容易一些。為處理一條非SELECT 語句,利用數據庫句柄,將它傳遞給do( )。do( ) 方法在一個步驟內准備和執行該查詢。例如,開始輸入一個新的成員, Marcis Brown,終止日期為2002 年6 月3 日,可以這樣做:
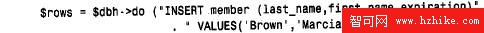
do( ) 方法返回涉及行的計數,如果出現錯誤,則返回un d e f。因為各種原因,可能出現錯誤(例如,這個查詢可能是畸形的,或可能沒有訪問這個表的權力)。對於非undef 的返回,注意那些沒有受到影響的行的情況。當這種情況發生時, do( ) 不返回數字0;而是返回字符串“0 E 0”(0的Perl科學計數法形式)。“0 E 0”在數值上等價於0,但是,在條件測試中將其視為真,以便可以將其與早期的undef 區別。如果do( ) 返回0,則區分是出現了錯誤( un d e f)還是“沒有受到影響的行”這兩種情況將更困難。使用下面的兩個測試之一可以檢查錯誤:
if (!defined ($rows)){#error}
if (!$rows) {#error}
在數值環境中,“0 E 0”與0 等價。下面的代碼將正確地顯示$rows 的任何非undef 值的行數:

也可以用printf( ) 使用‘% d’格式顯示$row 來強制進行隱含的數字轉換:

do( ) 方法等價於後跟execute( ) 的prepare( )。前面的INSERT 語句可以不調用do( ),如下發布:

處理返回結果集的查詢
本章提供了有關實現SELECT 查詢中提取行循環的若干選項的詳細信息(或其他類似於SELECT 的返回行的查詢,如DESCRIB E、EXPLAIN 和S H O W )。還討論了如何獲得結果中行數的計數值,如何處理不需要循環的結果集,以及如何一次檢索整個結果集的全部內容等。
1. 編寫提取行的循環
dump_members 腳本利用DBI 方法的標准序列檢索數據:prepare( ) 使驅動程序處理查詢,execute( ) 開始執行這個查詢, fetchrow_array( ) 提取結果集中的每一行, finish( ) 釋放與這個查詢相關的資源。
prepare( )、execute( ) 和finish( ) 是處理返回行的查詢中非常標准的部分。然而,對於提取的行,fetchrow_array( ) 實際上只是若干方法中的一種(請參閱表7 - 3)。
方法名返回值fetchrow_array( )行值的數組fetchrow_arrayref( )對行值數組的引用fetch( )與fetchrow_arrayref( ) 相同fetchrow_hashref( )對行值的散列引用,列名鍵索引
下面的例子說示出了怎樣使用每個提取行方法。這些例子在整個結果集的行中循環,對於每一行,顯示由逗號分隔的列值。在某些情況下,編寫這些顯示代碼還有一些更有效的方法,但是這些例子是以能夠說明訪問單個列值的語法的方式編寫的。
可如下使用fetchrow_array( ):

對fetchrow_array( ) 的每個調用都返回行值數組,不再有行時,返回一個空數組。
選擇將返回值分配給數組變量,可以在一組標量變量中提取列值。如果想使用比$ a r y [ 0 ]、$ary[1] 等更有意義的變量名,就可以這樣做。假設要在變量中檢索名稱和電子郵件值,可使用fetchrow_array( ),可以如下選擇並提取行:
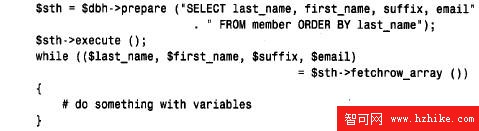
當然,在以這種方式使用一列變量時,必須保證查詢按正確的次序選擇列。DBI 不關心SELECT 語句指定列的次序,所以正確地分配變量是您的職責。在提取行時,使用一種稱為參數約束的技術,也可以使列值自動分配給單獨的變量。
fetchrow_arrayref( ) 類似於fetchrow_array( ),但不返回包含當前行的列值的數組,而是返回這個數組的引用,在沒有乘余行時,返回un d e f。如下使用:

通過數組引用$ary_ref 訪問數組元素。這類似於引用指針,所以使用了$ary_ref->[$i] 而不是$ a r y [ $ i ]。要想引用整個數組,就要使用@{$ary_ref} 結構。
fetchow_arrayef( ) 不適合在列表中提取變量。例如,下面的循環不起作用:

實際上,只要fetchrow_arrayref( ) 提取一行,這個循環就能正確地運行。但是在沒有更多的行時, fetchrow_arrayref( ) 返回un d e f,並且@{undef} 不合法(它有些像在C 程序中試圖廢棄一個NULL 指針)。
提取行的第三個方法fetchrow_hashref( ),如下使用:

對fetchrow_hashref( ) 的每個調用都返回一個按列名索引的行值散列的引用,在沒有更多的行時,返回un d e f。在此情況下,列值不按特定的次序出現; Perl 散列的成員是無序的。然而,散列元素是按列名索引的,所以$hashref 提供了一個單獨的變量,可通過它按名稱訪問任何列值。這使得能按任意需要的次序來提取值(或者它們中的任何子集),而且不必知道SELECT 查詢檢索的列的次序。例如,如果想訪問名稱和電子郵件域,可以如下進行:

如果希望將一行值傳遞給某個函數而又不需要這個函數知道SELECT 語句中指定列的次序時,fetchrow_hashref( ) 是非常有用的。既然如此,可以調用fetchrow_hashref( ) 來檢索行,並且編寫一個使用列名訪問來自行散列值的函數。