有些程序員在撰寫數據庫應用程序時,常專注於 OOP 及各種 framework 的使用,卻忽略了基本的 SQL 語句及其「性能 (performance) 優化」問題。曾聽過台灣某半導體大廠的新進程序員,所組出來的一段 PL/SQL 跑了好幾分鐘還跑不完;想當然,即使他的 AJax 及 ooxx 框架用得再漂亮,系統性能也會讓使用者無法忍受。以下是整理出的一些數據庫規劃、SQL performance tuning 簡單心得,讓長年鑽研 .Net、AJax、一堆高深 ooxx framework,卻無暇研究 SQL statement 的程序員,透過最短時間對本文的閱讀,能避免踩到一些 SQL 的性能地雷。
1、數據庫設計與規劃
? Primary Key 字段的長度盡量小,能用 small integer 就不要用 integer。例如員工數據表,若能用員工編號當主鍵,就不要用身分證號碼。
? 一般字段亦同。若該數據表要存放的數據不會超過 3 萬筆,用 small integer 即可,不必用 integer。
? 文字數據字段若長度固定,如:身分證號碼,就不要用 varchar 或 nvarchar,應該用 char 或 nchar。
? 文字數據字段若長度不固定,如:地址,則該用 varchar 或 nvarchar。除了可節省存儲空間外,存取硬盤時也會較有效率。
? 設計字段時,若其值可有可無,最好也給一個默認值,並設成「不允許 NULL」(一般字段默認為「允許 NULL」)。因為 SQL Server 在存放和查詢有
NULL 的數據表時,會花費額外的運算動作 [2]。
? 若一個數據表的字段過多,應垂直切割成兩個以上的數據表,並可用同名的 Primary Key 一對多連結起來,如:Northwind 的 Orders、Order Details 數據表。以避免在存取數據時,以「集簇索引 (clustered index)」掃描時會加載過多的數據,或修改數據時造成互相鎖定或鎖定過久。
2、適當地建立索引
? 記得自行幫 Foreign Key 字段建立索引,即使是很少被 JOIN 的數據表亦然。
? 替常被查詢或排序的字段建立索引,如:常被當作 WHERE 子句條件的字段。
? 用來建立索引的字段,長度不宜過長,不要用超過 20 個 Byte 的字段,如:地址。
? 不要替內容重復性高的字段建立索引,如:性別;反之,若重復性低的字段則適合建立索引,如:姓名。
? 不要替使用率低的字段建立索引,以免浪費硬盤空間。
? 不宜替過多字段建立索引,否則反而會影響到「INSERT、UPDATE、DELETE」的性能,尤其是以「OLTP (聯機事務處理;在線交易)」為主的網站數據庫。
? 若數據表存放的數據很少,就不必刻意建立索引。否則可能數據庫沿著存放索引的「樹狀結構」(Balanced Tree) 去搜尋索引中的數據,反而比掃描整個數據表還慢。
? 若查詢時符合條件的數據很多,則透過「非集簇索引 (non-clustered index)」搜尋的性能,反而 可能不如整個數據表逐筆掃描。
? 建立「集簇索引」的字段選擇至為重要,會影響到整個索引結構的性能。要用來建立「集簇索引」的字段,務必選擇「整數」類型 (鍵值會較小)、唯一、不可為 NULL。
3、適當地使用索引
? 有些書籍會提到,使用「LIKE、%」做模糊查詢時,即使您已替某個字段建立索引 (如下方代碼的 CustomerID
字段),但以常量字符開頭才會使用到索引,若以萬用字符 (%) 開頭則不會使用索引,如下所示:
USE Northwind; GO SELECT * FROM Orders WHERE CustomerID LIKE 'D%'; --使用索引 SELECT * FROM Orders WHERE CustomerID LIKE '%D'; --不使用索引
在 SQL Server 2005 執行完成後按 Ctrl + L,可檢閱如下圖的「執行計劃」。
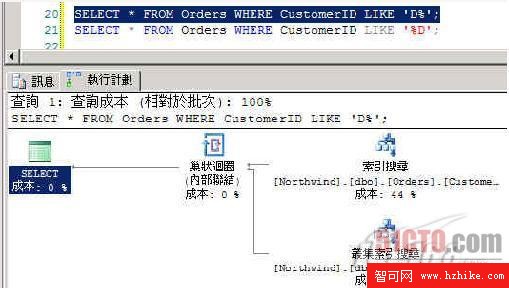
圖 1
可看出「查詢最佳化程序」有使用到索引做搜尋
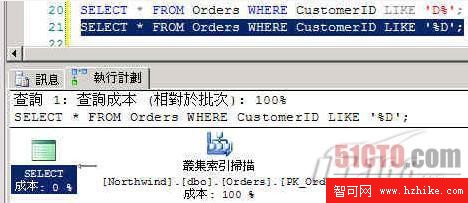
圖 2
在此的「集簇索引」掃描,並未直接使用索引,性能上幾乎只等於掃描整個數據表
但經反復測試,這種語法是否會使用到索引,抑或會逐筆掃描,並非絕對的。仍要看所下的查詢關鍵詞,以及字段內 所存儲的數據內容而定。但對於存儲數據筆數龐大的數據表,最好還是少用 LIKE 做模糊查詢。
? 以下的運算符會造成「負向查詢」,常會讓「查詢最佳化程序」無法有效地使用索引,最好能用其它運算符和語法改寫 (經版工測試,並非有負向運算符,就絕對無法使用索引):
NOT 、 != 、 <> 、 !> 、 !< 、 NOT EXISTS 、 NOT IN 、 NOT LIKE
? 避免讓 WHERE 子句中的字段,去做字符串的串接或數字運算,否則可能導致「查詢最佳化程序」無法直接使用索引,而改采「集簇索引掃描」(經版工測試並非絕對)。
? 數據表中的數據,會依照「集簇索引」字段的順序存放,因此當您下 BETWEEN、GROUP BY、ORDER BY 時若有包含「集簇索引」字段,由於數據已在數據表中排序好,因此可提升查詢速度。
? 若使用「復合索引」,要注意索引順序上的第一個字段,才適合當作過濾條件。
4、避免在 WHERE 子句中對字段使用函數
對字段使用函數,也等於對字段做運算或串接的動作,一樣可能會讓「查詢最佳化程序」無法有效地使用索引。但真正對性能影響最重大的,是當您的數據表內若有 10 萬筆數據,則在查詢時就需要呼叫函數 10 萬次,這點才是真正的性能殺手。程序員應
注意,在系統開發初期可能感覺不出差異,但當系統上線且數據持續累積後,這些語法細節所造成的性能問題就會逐步浮現。
SELECT * FROM Orders WHERE DATEPART(yyyy, OrderDate) = 1996 AND DATEPART(mm, OrderDate)=7
可改成
SELECT * FROM Orders WHERE OrderDate BETWEEN '19960701' AND '19960731'
SELECT * FROM Orders WHERE SUBSTRING(CustomerID, 1, 1) = 'D'
可改成
SELECT * FROM Orders WHERE CustomerID LIKE 'D%'
注意當您在下 UPDATE、DELETE 語句時,若有采用 WHERE 子句,也應符合上述原則。
5、AND 與 OR 的使用
在 AND 運算中,「只要有一個」條件有用到索引 (如下方的 CustomerID),即可大幅提升查詢速度,如下圖 3 所示:
SELECT * FROM Orders WHERE CustomerID='VINET' AND Freight=32.3800 --使用索引,會出現下圖 3 的畫面
SELECT * FROM Orders WHERE Freight=32.3800 --不使用索引,會出現上圖 2 的畫面
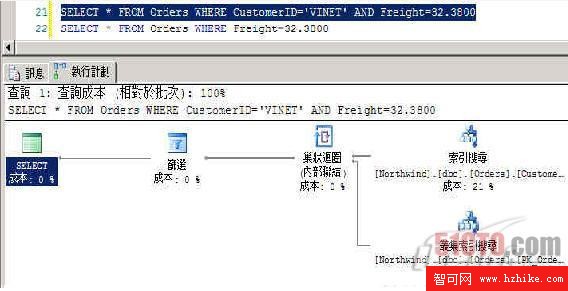
圖 3
但在 OR 運算中,則要「所有的」條件都有可用的索引,才能使用索引來提升查詢速度。因此 OR 運算符的使用必須特別小心。
若您將上方 AND 的范例,邏輯運算符改成 OR 的話,如下所示:
SELECT * FROM Orders WHERE CustomerID='VINET' OR Freight=32.3800
由於無法有效地使用索引,也會出現圖 2 的畫面。
在使用 OR 運算符時,只要有一個條件 (字段) 沒有可用的索引,則其它所有的條件 (字段) 都有索引也沒用,只能如圖 2 般,把整個數據表或整個集簇索引都掃描過,以逐筆比對是否有符合條件的數據。
據網絡上文件的說法 [1],上述的 OR 運算語句,我們還可用 UNION 聯集適當地改善,如下:
SELECT * FROM Orders WHERE CustomerID='VINET' UNION SELECT * FROM Orders WHERE Freight=32.3800
此時您再按 Ctrl + L 檢閱「執行計劃」,會發現上半段的查詢會使用索引,但下半段仍用集簇索引掃描,對性能不無小補。
6、適當地使用子查詢
相較於「子查詢 (Subquery)」,若能用 JOIN 完成的查詢,一般會比較建議使用後者。原因除了 JOIN 的語法較容易理解外,在多數的情況下,JOIN 的性能也會比子查詢較佳;但這並非絕對,也有的情況可能剛好相反。
我們知道子查詢可分為「獨立子查詢」和「關聯子查詢」兩種,前者指子查詢的內容可單獨執行,後者則無法單獨執行,亦即外層查詢的「每一次」查詢動作都需要引用內層查詢的數據,或內層查詢的「每一次」查詢動作都需要參考外層查詢的數據。
以下我們看一個比較極端的例子 [2]。若我們希望所有查詢出來的數據,都能另外給一個自動編號,版工我在之前的文章「ASP.Net 數據分頁第一篇 - 探討分頁原理及 SQL Server 2005 的 ROW_NUMBER 函數」中有介紹過,可用 SQL Server 2005 中新增的 ROW_NUMBER 函數輕易地達成,且 ROW_NUMBER 函數還能再加上「分群 (PARTITION BY)」等功能,而且執行性能極佳。
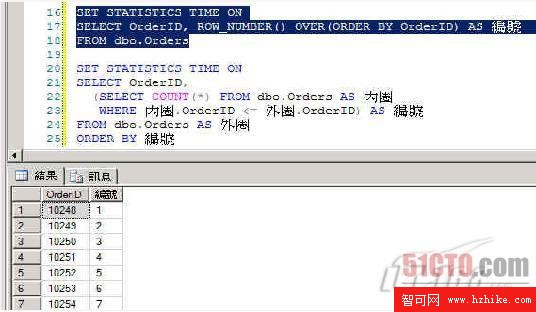
圖 4
將 Orders 數據表的 830 筆數據都撈出來,並在右側給一組自動編號
現在我們要如上圖 4 般,將 Northwind 數據庫中 Orders 數據表的 830 筆數據都撈出來,並自動給一組編號,若用 ROW_NUMBER 函數的寫法如下所示,而且性能極佳,只要 2 ms (毫秒),亦即千分之二秒。
SET STATISTICS TIME ON SELECT OrderID, ROW_NUMBER() OVER(ORDER BY OrderID) AS 編號 FROM dbo.Orders
但如果是傳統的「子查詢」寫法,或 輔以 AS 關鍵詞的「衍生數據表」的語法,寫法必須如下 (拷貝後在 SQL Server 中實際可執行):
SET STATISTICS TIME ON SELECT OrderID, (SELECT COUNT(*) FROM dbo.Orders AS 內圈 WHERE 內圈.OrderID <= 外圈.OrderID) AS 編號 FROM dbo.Orders AS 外圈 ORDER BY 編號
但這種舊寫法,會像先前所提到的,外層 (外圈) 查詢的「每一次」查詢動作都需要引用內層 (內圈) 查詢的數據。以上方示例而言,外層查詢的每一筆數據,都要等內層查詢「掃描整個數據表」並作比對和計數,因此 830 筆數據每一筆都要重復掃描整個數據表 830 次,所耗用的時間也因此爆增至 170 ms。
若您用相同的寫法,去查詢 AdventureWorks 數據庫中,有 31,465 筆數據的 Sales.SalesOrderHeader 數據表,用 ROW_NUMBER 函數要 677 ms,還不到 1 秒鐘;但用子查詢的話,居然要高達 233,835 ms,將近快 4 分鐘的時間。
-- 用 ROW_NUMBER 的寫法,改查詢 AdventureWorks 數據庫 (31,465 筆數據,要 677 ms,還不到 1 秒鐘) SELECT SalesOrderID, ROW_NUMBER() OVER(ORDER BY SalesOrderID) AS rownum FROM Sales.SalesOrderHeader
-- 用「子查詢」的寫法,改查詢 AdventureWorks 數據庫 (31,465 筆數據,要 233,835 ms,將近 4 分鐘) SELECT SalesOrderID, (SELECT COUNT(*) FROM Sales.SalesOrderHeader AS 內圈 WHERE 內圈.SalesOrderID <= 外圈.SalesOrderID) AS 編號 FROM Sales.SalesOrderHeader AS 外圈 ORDER BY 編號
雖然這是較極端的范例,但由此可知子查詢的撰寫,在使用上不可不慎,尤其是「關聯子查詢」。程序員在系統開發初期、數據量還很少時感受不到此種 SQL 語法的重大陷阱;但等到系統上線幾個月或一兩年後,就會有反應遲緩的現象, 不可不慎。
注:AS 關鍵詞及「衍生數據表」是 SQL Server 2005 的新語法,「衍生數據表」只會存在內存中,AS 關鍵詞的作用是賦予一個別名。過去許多必須用暫存數據表或 VIEw (視圖) 的情況,現在都可以用「衍生數據表」來取代,如此一來不但可以降低數據庫管理工作的負擔,亦可提升查詢性能。
7、其他查詢技巧
? DISTINCT、ORDER BY 語法,會讓數據庫做額外的計算。此外「聯集」的使用,若沒有要剔除重復數據的需求,使用 UNION ALL 會比 UNION 更優,因為後者會加入類似 DISTINCT 的算法。
? 在 SQL Server 2005 中,存取數據庫對象時,最好明確指定該對象的「結構描述 (Schema)」,也就是使用兩節式的名稱,如下方代碼所示。否則若呼叫者的預設 Schema 不是 dbo,則 SQL Server 在執行時,會先尋找該使用者預設 Schema 所搭配的對象,找不到的話才會轉而使用預設的 dbo,會多耗費尋找的時間。因此若要執行一個叫做 dbo.mySP1 的 Stored Procedure,應使用以下的兩節式名稱: EXEC dbo.mySP1
8、盡可能用 Stored Procedure 取代應用程序直接存取數據表
Stored Procedure 除了經過事先編譯、性能較好以外,亦可節省 SQL 語句傳遞的網絡頻寬,也方便商業邏輯的重復使用。再搭配自訂函數和 VIEw 的使用,將來若要修改數據表結構、重新切割或「反正規化」時亦較方便。
9、盡可能在數據來源層,就先過濾數據
使用 SELECT 語法時,盡量避免傳回所有的數據至前端而不設定 WHERE 等過濾條件。雖然 ASP.Net 中 SqlDataSource、ObjectDataSource 控件的 FilterExpression 可再做篩選,GridVIEw 控件的 SortExpression 可再做排序,但會多消耗掉數據庫的系統資源、web server 的內存和網絡頻寬。最好還是在數據庫和數據來源層,就先用 SQL 條件式或 Stored Procedure 篩選出所要的資料。
結論
本文的觀念,不管是寫 SQL statement、Stored Procedure、自訂函數或 VIEw 皆然。本文只是挑出程序員較容易犯的 SQL 語法性能問題,以期能在短時間浏覽過本文後,在寫 ADO.Net 程序時能修正以往隨興的 SQL 語句撰寫習慣。文中提到的幾點,只不過是 SQL 語法性能議題的入門。市面上有很多更進階的書籍,例如:「The Art of SQL」、「SQL Tuning」,亦有針對 Oracle 或 SQL Server 數據庫撰寫的 performance tuning 相關書籍,有興趣可自行翻
閱