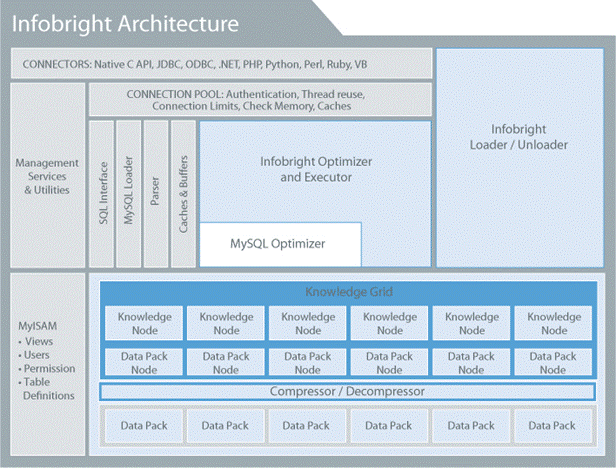
這三天看了高性能MySQL這本書的第七章-操作系統和硬件優化.
至於為什麼看這章節,主要是因為最近一直在看操作系統原理這本書,是想通過了解具體的軟件設計(比如Mysql)來進行思路的整理. 這章節不僅僅是優化,本身Mysql的設計也是借鑒了很多操作系統原理的知識,可以說假如了解了MySQL,那麼學習其他的就可能融會貫通. 1:不要假學習.
2:基礎理論知識理解深刻了,才能更好的學習其他的,這也不是一個實踐就能解決的問題. 其實任何系統最終的瓶頸可能都是I/O(包括網絡I/O),內存,Cpu.所以我們考慮問題的時候應該更有序.因為任何的問題最終都反映在這三個問題上面. 我們很難發現系統瓶頸的原因在於各個子系統之間都相互有關系,一個系統的問題會導致另外個子系統的瓶頸,這也是架構存在的理由(分層解決問題).一般來說MySQL基本上都是I/O瓶頸,因為內存總是會不夠的. 回想下我們做Msn Space項目的時候,申請數據庫資源的時候從沒考慮我們的業務特性是什麼,是Cpu密集型的還是I/O密集型的.另外不能單純檢查Cpu的負載,一定要平衡Cpu利用率和I/O負載. 選擇快的Cpu還是多的Cpu,文章如此解釋:高吞吐量:針對系統來說,吞吐量越高,說明做的事情越多. 目前的MySQL架構導致的問題:
1:不能充分利用多Cpu,因為對於單個請求不能並發運行多個查詢
2:復制由於是單進程的,所以利用不上其他Cpu.所以有的時候從服務器反而會遇到瓶頸
3:考慮到MySQL最大的問題是鎖(需要繼續學習),所以更快的Cpu更好,因為這時候有多個Cpu也沒用對於CPU架構來說,不管是系統還是應用程序盡量都是64位的.都是為了更好的使用內存. 對於本章說的多Cpu和核心來說:
雖然多個Cpu不能並行運行單個查詢,但是對於數據庫這樣的業務來說,多個Cpu能處理不同的鏈接,所以多Cpu還是好的 1:邏輯並發問題:應用程序對資源的競爭.可以通過調配存儲引擎或者不同的事務隔離級別
2:內部並發問題: 對信號量,頁面訪問的競爭,這其實屬於系統層面或者軟件層面的問題
系統的瓶頸只有經過評測才能真正知道,未來Cpu的發展是在多核而非Cpu的速度. 對於資源的金字塔模型以及局部性問題,很多計算機原理中都說了.基本上都是建議使用越底層的緩存.但是對於數據庫業務來說卻有區別:自己的內存管理比操作系統的緩存更有效,因為它了解應用. 接下來說說磁盤,包括計算機原理,操作系統都描述過,而對於互聯網應用來說基本都是討論隨機I/O和順序I/O. 1:順序I/O比隨機I/O快,並且順序I/O不建議使用系統文件緩存(比如數據庫業務). 2:存儲引擎對於不同磁盤訪問的讀取,需要理解下BTREE
3:內存對於寫入操作的優化
(1)多次內存寫,一次合並Sync磁盤
(2)I/O合並操作
預寫的作用就是I/O操作順序化和異步化本章節解釋working set的例子非常形象,原則上工作集盡量保持和內存匹配.
InnodDB的工作集包括索引和數據,其本身的設計是將更多可能有關聯的數據存儲在一個緩存單元中,所以優秀的聚集索引設計很重要.緩存單元是基於頁的. 內存磁盤比的使用要合適,主要有二點:
1:不要為了追求極致的Cpu利用率而浪費其它資源.
2:需要考慮系統中最脆弱的部分. 假如一個I/O密集型操作,應該如何選擇硬盤呢.
1:尋道時間和訪問