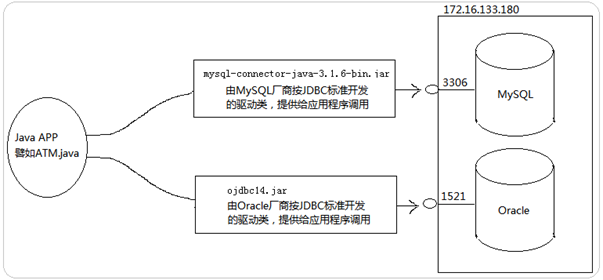
大多數查詢引擎提供了查詢簡化的功能,其目的就是使得查詢比原始輸入更加高效。MySQL 查詢優化器極大的發揮了這種功能,為了在絲毫不改變原始目標的前提下盡量簡化查詢,優化器對查詢進行分析有時甚至重新描述。
按照效率最高的原則,MySQL 查詢優化器啟用了一到兩條強調規則。查詢優化器的最主要的邏輯思想是盡多盡早的去掉一些行。這聽起來有悖於查詢的目標,查詢的確就是為了選出記錄,但這個邏輯卻並沒有錯。開始時優化器去掉的行越多,需要查詢按照附加規則去估值的行就越少。需要與規則進行比較的行數越少,查詢就能越快的完成任務。舉個例子,假設一個SELECT查詢使用 WHERE 語法規定了兩個條件:
WHERE col1 = 條件A AND col2 = 條件B現在,假設1,000行符合條件A而只有250行符合條件B。而且,只有5條記錄同時符合上述兩個條件。優化器選擇的是最小障礙路徑:250行匹配。原因很明顯:這樣只需要對符合條件B的250條記錄進行估值來找到同時符合兩個條件的記錄。如果優化器起初選擇符合條件A的1000條記錄,MySQL就得對這1000條記錄進行估值,來找到同時符合兩個條件的記錄。MySQL使用索引來確定到底哪個條件提供了最快捷的路徑
索引
簡單說來,索引就是指向數據文件中實際記錄的指針。索引包含了值對應了表中每一個值,但是 MySQL 是按照順序存儲索引值的。例如,在表employee中,你可能對字段 EmployeeNumber 進行索引。不管你怎樣整理表employee,索引值始終按照EmployeeNumber進行排序。
現在假設在表中查找編號為24的雇員。MySQL對表進行搜索並在索引值為25處停止。優化器知道,索引值超過25就不會再有更多指針符合查找規則。
現在,為了能夠理解下面的敘述,需要定義幾個必須知道的索引術語: 單列索引只考慮一列的值。
多列索引考慮一列以上的值。
左端前綴索引是充當索引的左端列的集合。
前兩個顧名思義;第三個復雜一些。多列索引有可能充當幾個前綴,這是因為索引中任意從最左邊開始的連續列,都可用來匹配數值。例如,假設有一個三列索引,其列名如下:LastName, FirstName,和Title。除了原來的索引,還可能有兩個以上索引:
LastName, FirstName
LastName