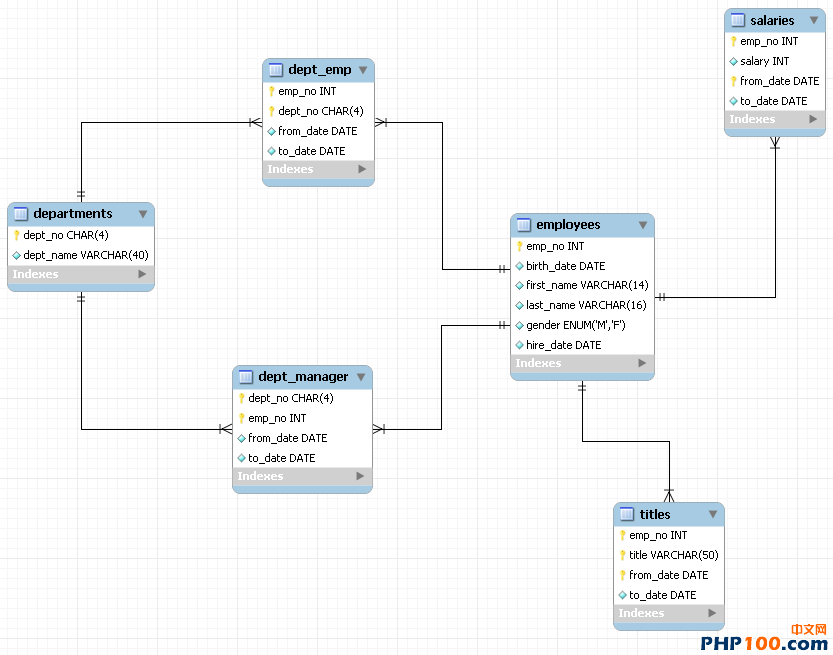
元數據是“關於數據的數據”。描述數據庫的任何數據—作為數據庫內容的對立面—是元數據。因此,列名、數據庫名、用戶名、版本名以及從SHOW語句得到的結果中的大部分字符串是元數據。還包括INFORMATION_SCHEMA數據庫中的表中的內容,因為定義的那些表存儲關於數據庫對象的信息。
元數據表述必須滿足這些需求:
· 全部元數據必須在同一字符集內。否則,對INFORM一個TION_SCHEMA數據庫中的表執行的SHOW命令和SELECT查詢不能正常工作,因為這些運算結果中的同一列的不同行將會使用不同的字符集。
· 元數據必須包括所有語言的所有字符。否則,用戶將不能夠使用它們自己的語言來命名列和表。
為了滿足這兩個需求,MySQL使用Unicode字符集存儲元數據,即UTF8。如果你從不使用重音字符,這不會導致任何破壞。但如果你使用重音字符,應該注意的是元數據是用UTF8存儲。
這意味著,USER()、CURRENT_USER()、DATABASE()和VERSION()函數的返回值被 默認設置為UTF8字符集,這與同義函數如SESSION_USER() 和SYSTEM_USER()的結果相同。
服務器將character_set_system系統變量設置為元數據字符集的名:
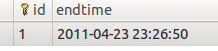
MySQL> SHOW VARIABLES LIKE 'character_set_system';
Variable_name Value character_set_system utf8
存儲元數據使用Unicode並不意味著列頭和DESCRIBE函數的結果默認在character_set_system字符集中。當你使用SELECT column1 FROM t語句時,名字為column1的列從服務器返回客戶端並使用由SET NAMES語句確定的字符集。更明確地說,使用的字符集是由character_set_results系統變量的值確定的。如果這個系統變量設置為NULL,不執行字符轉換,服務器使用最初的字符集(字符集由character_set_system系統變量設置)返回元數據。
如果你希望服務器不使用UTF8字符集返回元數據結果,那麼使用SET NAMES語句強制服務器執行字符集轉換或者在客戶端執行轉換。在客戶端執行轉換效率較高,但這種選項並不能使用於全部客戶端。
如果你正在一個語句中使用(例如)USER()函數進行比較或賦值,不要擔心。MySQL為你執行一些原子轉換。
SELECT * FROM Table1 WHERE USER() = latin1_column;
這是可以的,因為在比較之前latin1_column列的內容會自動轉換到UTF8。
INSERT INTO Table1 (latin1_column) SELECT USER();
這是可以的,因為賦值之前USER()函數返回的內容自動轉換為latin1。至今,自動轉換沒有全部實施,但是以後的版本中應該工作正常。
盡管自動轉換不屬於SQL標准,SQL標准化文檔中說每一個字符集是(根據支持的字符)Unicode的“子集”。因此,一個知名的原則是,“適用超集的字符集能夠應用於其子集”,我們相信Unicode的 校對規則能夠應用於非Unicode字符串的比較。
注釋:在MySQL5.1中,errmsg.txt文件全部使用UTF8。客戶端字符集的轉換是自動進行的,如同元數據。