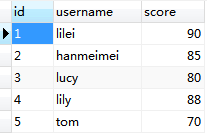
數據庫中有個大表,需要查找其中的名字有重復的記錄id,以便比較。
如果僅僅是查找數據庫中name不重復的字段,很容易
- SELECT min(`id`),`name`
- FROM `table`
- GROUP BY `name`;
但是這樣並不能得到說有重復字段的id值。(只得到了最小的一個id值)
查詢哪些字段是重復的也容易
- SELECT `name`,count(`name`) as count
- FROM `table`
- GROUP BY `name` HAVING count(`name`) >1
- ORDER BY count DESC;
但是要一次查詢到重復字段的id值,就必須使用子查詢了,於是使用下面的語句來實現MySQL大表重復字段查詢。
- SELECT `id`,`name`
- FROM `table`
- WHERE `name` in (
- SELECT `name`
- FROM `table`
- GROUP BY `name` HAVING count(`name`) >1
- );
但是這條語句在mysql中效率太差,感覺MySQL並沒有為子查詢生成臨時表。
於是使用先建立臨時表
- create table `tmptable` as (
- SELECT `name`
- FROM `table`
- GROUP BY `name` HAVING count(`name`) >1
- );
然後使用多表連接查詢
- SELECT a.`id`, a.`name`
- FROM `table` a, `tmptable` t
- WHERE a.`name` = t.`name`;
結果這次結果很快就出來了。
用 distinct去重復
- SELECT distinct a.`id`, a.`name`
- FROM `table` a, `tmptable` t
- WHERE a.`name` = t.`name`;