隨著各種多字節字符集的廣泛應用,而在軟件開發裡人數比例非常高的操英文的程序員對多字節字符並不是很了解,這是最近幾年很多漏洞都是多字節引起的一個原因。本文作者就
MySQL的字符集架構作用談了自己的看法。 最近幾個月,我每次用MySQL,幾乎都會想:MySQL現在如此層次分明的字符集架構作用真的很大嗎?
MySQL的字符集處理
發送請求
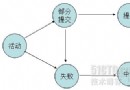
客戶端(character_set_clIEnt)=》數據庫連接(character_set_connection)=》存儲(table,column)
返回請求
存儲(table,column)=》數據庫連接(character_set_connection )=》客戶端(character_set_results)
在每一個非初始節點,都會做一次從上一個結點到當前節點的字符集轉換操作。舉個例子,有如下環境:
◆ character_set_connection utf-8
◆ character_set_results gbk
◆ character_set_clIEnt gb2312
◆ 有表A,字段字符集全部為BIG5
發送請求的時候,首先數據從gbk轉換為utf-8,再轉換為BIG5,然後再存儲。
返回請求的時候,首先數據從BIG5轉換為utf-8,再轉換為gb2312,然後再發送給客戶端。
架構的作用
1. 允許不同的客戶端具有不同的字符集。典型的例子就是,我有一個utf-8的站點,這個站點就是一個charset clIEnt為utf-8的客戶端。與此同時,我有可能需要在一個gbk的終端上讀寫數據庫,這又是一個客戶端,不過它的字符集是gbk。
2. 通過數據庫操作文件系統的時候,需要把文件路徑轉為文件系統的字符集。例如我的客戶端是gbk,而服務器文件系統是utf-8。操作”/A片 /Rina.rmvb”,發送過去的數據裡,“片”的數據和服務器是不一樣的。這時候就需要有個辦法可以把轉換GBK的“片”到utf-8。在這裡 MySQL引入了一個叫character_filesystem的東西來完成這個事情。
除此之外,我暫時想不到其他的作用了。但是仔細想想,我們真的需要這樣的處理嗎?很多網站,無非就是希望自己的數據能怎麼進去就怎麼出來。這裡又有兩種情況了。
1. 希望可以根據數據進行排序或者做like操作。首先說排序,對於包含中文的字段來說,根據字符集排序的概念如同雞肋。簡體中文排序,一般都是希望按拼音來排序。我沒有去真正了解過MySQL裡的校驗,但是從我接觸過的程序來看,需要做此類排序,都是專門建一個存放拼音的字段來排序。而拼音又存在多音字的情況。如果是UTF-8,還存在某個區間的中文同時被中日韓三國共用的情況。實現起來不是這麼容易,所以MySQL無論的GBK還是UTF-8的校驗集 應該都沒有實現拼音。我敢說,現在國內使用MySQL的大多數網站,所用到的校驗集,只是一個byte排序而已。而byte排序,根本不需要使用什麼字符 集。所以說對於中文站點,MySQL字符校驗在排序上沒任何意義。
但是在like操作上,倒是有了一點點意義。例如我like ‘%a%’,就有可能匹配到某個中文某個部分含有a。當然這種情況在utf-8下不會遇到,因為utf-8的存儲格式導致a只可能是a,不可能是一個多字節字符的一部分。但是在其他字符集可能就會有這個問題了。說到最後,like又變得和order一樣使得校驗沒意義了。暈倒。
2. 如果完全不需要對數據進行排序,like或者全文檢索,那麼請停止使用char,varchar,text之類的吧。 binary,varbinary,BLOB才是正確的選擇。binary之類的在存儲,取出的時候都不會進行字符集轉換,而在排序時候,只根據二進制內 容排序,所以在效率上高出char,varchar,text很多。
這種情況更不需要字符集了。但是按照目前MySQL的架構,在clIEnt和connection之間的字符集操作,是忽略字段類型的,在這兩個節點之間,依然會進行字符集轉換。
另外提一下PHP裡的設置字符集。大家請不要再使用mysql_query(”set names utf8″)這樣的語句了。mysql_set_charset()才是最完整的字符集設置方式。後者比前者多一個設置,就是把struct MySQL的charset成員也設置了。這個成員變量在escape的時候起著很重要的作用,特別是對於GBK這種運行把“\”作為字符一部分的編碼格式。如果你只使用mysql_query(”set names XXX”),那麼在某些字符集,會有重大的安全漏洞,導致MySQL_real_escape_string變得和addslashes一樣不安全。