6.9 MySQL 查詢緩存
從 MySQL 4.0.1 開始,MySQL Server 有一個重要的特征:Query Cache。 當在使用中,查詢緩存會存儲一個 SELECT 查詢的文本與被傳送到客戶端的相應結果。如果之後接收到一個同樣的查詢,服務器將從查詢緩存中檢索結果,而不是再次分析和執行這個同樣的查詢。
注意:查詢緩存絕不返回過期數據。當數據被修改後,在查詢緩存中的任何相關詞條均被轉儲清除。
在某些表並不經常更改,而你又對它執行大量的相同查詢時,查詢緩存將是非常有用的。對於許多 WEB 服務器使用大量的動態信息,這是一個很典型的情況。
下面是查詢緩存的一個性能數據。(這些結果的產生,是通過在一個 a Linux Alpha 2 x 500 MHz、2GB RAM 和 64MB 查詢緩存上執行 MySQL 基准套件和到的):
* 如果你執行的所有查詢均是簡單的(比如從表中一行一行的選取);但是仍然是不同的,所以該查詢不能被緩沖,查詢緩存處於活動時,開銷為 13%。這可以被看作是最差的情況。然而,在實際情況下,查詢是比我們的簡單示例要復雜得多的,所以開銷通常顯著得低。
* 在只有一行記錄表中搜索一行後,搜索將快 238% 。這可以被認為是接近於對一個被緩沖的查詢所期望的最小的加速。
* 如果你希望禁用查詢緩存,設置 query_cache_size=0。禁用了查詢緩存,將沒有明顯的開銷。(在配置選項 --without-query-cache 的幫助下,查詢緩存可以被排除在外碼之外)
6.9.1 查詢緩存如何運作
查詢在分析之前先被比較,因而
SELECT * FROM tbl_name
和
Select * from tbl_name
對於查詢緩存被當作是不同的查詢,因而查詢需要嚴格的一致(字節對字節的),才會被認為是同樣的。 另外,如果一個客戶端使用一個新的連接協議格式或不同於其它客戶端的另一個字符集,一個查詢將被視為不同的。
使用不同數據庫的,使用不同協議版本的,或使用不同的缺省字符串的查詢將被認為是不同的查詢,並將分別的緩沖。
高速緩沖不對 SELECT CALC_ROWS ... 和 SELECT FOUND_ROWS() ... 類型的查詢起作用,因為找到的行的數目也是被存儲在緩沖裡的。
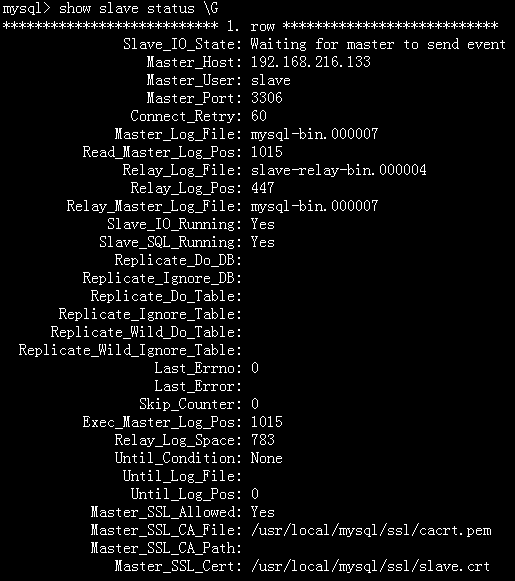
如果查詢結果被從查詢緩存中返回,那麼狀態變量 Com_select 將不會被增加,但是 Qcache_hits 卻會增加。查看章節 6.9.4 查詢緩存的狀態和維護。
如果一個表發生的改變 (INSERT, UPDATE, DELETE, TRUNCATE, ALTER 或 DROP TABLE|DATABASE),那麼所有這張表使用的緩沖的查詢(可能通過一個 MRG_MyISAM 表!)將被得失效,並從緩沖中移除。
InnoDB 表的事務所做的更改將在一個 COMMIT 被完成時,使數據失效。
如果一個查詢包括下面的函數,它將不能被緩沖:
函數 函數 函數
User-Defined Functions CONNECTION_ID FOUND_ROWS
GET_LOCK RELEASE_LOCK LOAD_FILE
MASTER_POS_WAIT NOW SYSDATE
CURRENT_TIMESTAMP CURDATE CURRENT_DATE
CURTIME CURRENT_TIME DATABASE
ENCRYPT (只有一個參數調用) LAST_INSERT_ID RAND
UNIX_TIMESTAMP (無參數調用) USER BENCHMARK
如果一個查詢包含用戶變量,引用 MySQL 系統數據庫,或下列之一的格式,SELECT ... IN SHARE MODE, SELECT ... INTO OUTFILE ..., SELECT ... INTO DUMPFILE ... 或 SELECT * FROM AUTOINCREMENT_FIELD IS NULL (檢索最後一個插入 ID - ODBC 語句),該查詢亦不可以被緩存。