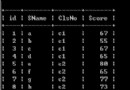
一個站有可能經歷gb2312(gbk,big5)到utf8的轉換過程,其中會遇到很多的問題。站點太龐大了怎麼辦呢,只能一步步來了。要是能在極少改動前端代碼的情況下,先完成數據的轉換將會使整件事情容易得多。經過幾天測試終於發現,Mysql以utf8存儲gbk輸出是可以實現的。mysql4.1後都有個特性,可以指定當前客戶端連接所使用的字符集,MySQL默認都是latin1,或由mySQL Server端配置的字符集進行連接校對。我使用utf8_general_ci來創建字段。
DB:
SQL代碼:
程序代碼
Create TABLE `table` (
`id` INT( 10 ) NOT NULL ,
`name` VARCHAR( 50 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
INDEX ( `g_id` )
) ENGINE = innodb CHARACTER SET utf8 COLLATE utf8_general_ci;
PHP:
存儲操作指定使用utf8字符集進行連接校對,讀取操作指定使用gbk字符集進行連接校對。
PHP代碼:
程序代碼
<?PHP
// Select DB And Set Link Use UTF8
function _select_db_utf()
{
MySQL_select_db($this->db_name, $this->db_link);
// init character
MySQL_query("SET NAMES utf8", $this->db_link);
MySQL_query("SET CHARACTER SET utf8", $this->db_link);
MySQL_query("SET COLLATION_CONNECTION=’utf8_general_ci’", $this->db_link);
return true;
}
// Select DB And Set Link Use GBK
function _select_db_gb()
{
MySQL_select_db($this->db_name, $this->db_link);
// init character
MySQL_query("SET NAMES gbk", $this->db_link);
MySQL_query("SET CHARACTER SET gbk", $this->db_link);
MySQL_query("SET COLLATION_CONNECTION=’gbk_chinese_ci’", $this->db_link);
return true;
}
?>
需要注意幾點:
1. MySQL必須把gbk,gb2312,utf8等字符集編譯進去。
2. 入庫的數據內容必須保證是最正確的UTF8編碼。
3. 存儲和讀取操作要指定正確的字符集進行連接校對。
要是前端代碼操作數據入庫不能以UTF8進行,則需要對字符進行轉碼了。(例如用AJax提交的數據便是正確的UTF8,這時是不用轉換的。)
因為mb_string是PHP所支持字符最全的,而iconv比它稍差一點,mb_string並不能完全支持一些特殊字符的轉碼,所以目前為止都沒有完美的轉碼方法。
再次對mb_string和iconv進行比較:
mb_string:
1. 所支持字符最全
2. 內容自動識別編碼,不需要確定原來字符的編碼,但是執行效率比iconv差太多
3. $content = mb_convert_encoding($content, "UTF-8", "GBK,GB2312,BIG5");(順序不同效果也有差異)
iconv:
1. 所支持字符不全
2. 需要確定原來字符的編碼,但在確定編碼的情況下執行效率比mb_convert_encoding高
3. $content = iconv("GBK", "UTF-8", $content);