Mysql的Replication是一個 “異步” 的復制過程,也就是從Master復制到一個Slave上。
Mysql 5.1 多線程實現主從復制
重要的是,從Mysql5.1起,Master與Slave之間的復制過程修改為三個線程來完成。
其中兩個線程(Sql線程和IO線程)在 Slave 端,另外一個線程(IO線程)在 Master 端,使用並行的處理方式。而老版本的主從復制是用一個線程來處理。這樣的話,就解決了從庫延遲的問題;以及,從庫處理Bin_log時,主庫又新增數據, 從而帶來的數據丟失問題。
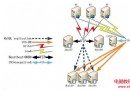
主從復制基本過程
主從庫的整個復制過程實際上就是:Slave從Master端獲取Binary log然後再按順序的執行日志中所記錄的各種操作。
Slave 上面的IO線程連接上 Master,並請求從指定日志文件的指定位置(或者從最開始的日志)之後的日志內容
Master 接收到來自 Slave 的 IO 線程的請求後,通過負責復制的 IO 線程根據請求信息讀取指定日志指定位置之後的日志信息,返回給 Slave 端的 IO 線程。返回信息中除了日志所包含的信息之外,還包括本次返回的信息在 Master 端的 Binary Log 文件的名稱以及在 Binary Log 中的位置
Slave 的 IO 線程接收到信息後,將接收到的日志內容依次寫入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,並將讀取到的Master端的bin-log的文件名和位置記錄到master- info文件中,以便在下一次讀取的時候能夠清楚的高速Master“我需要從某個bin-log的哪個位置開始往後的日志內容,請發給我”
Slave 的 SQL 線程檢測到 Relay Log 中新增加了內容後,會馬上解析該 Log 文件中的內容成為在 Master 端真實執行時候的那些可執行的 Query 語句,並在自身執行這些 Query。這樣,實際上就是在 Master 端和 Slave 端執行了同樣的 Query,所以兩端的數據是完全一樣的
Mysql主從延遲問題的解決
當然,即使是換成了現在這樣兩個線程來協作處理之後,同樣也還是存在 Slave 數據延時以及數據丟失的可能性的,畢竟這個復制是異步的。只要數據的更改不是在一個事務中,這些問題都是存在的。
如果要完全避免這些問題,就只能用 MySQL 的 Cluster 來解決了。不過 MySQL的 Cluster 仍然還是一個內存數據庫的解決方案,也就是需要將所有數據包括索引全部都 Load 到內存中,這樣就對內存的要求就非常大的大,對於一般的大眾化應用來說可實施性並不是太大