相對於傳統行業的相對服務時間9x9x6或者9x12x5,因為互聯網電子商務以及互聯網游戲的實時性,所以服務要求7*24小時,業務架構不管是應用還是數據庫,都需要容災互備,在mysql的體系中,最好通過在最開始階段的數據庫架構階段來實現容災系統。所以這裡從業務宏觀角度闡述下mysql架構的方方面面。
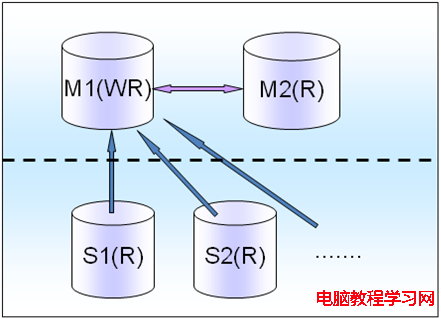
虛線表示跨機房部署,比如電子商務系統,一個Master既有讀也有些寫,對讀數據一致性需要比較重要的,讀要放在Master上面。
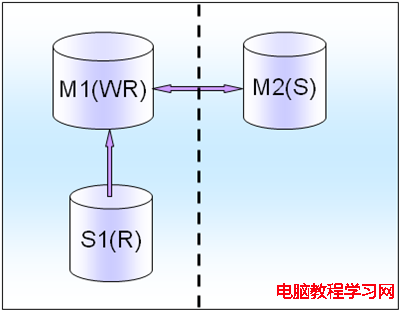
M(R)僅僅是一個備庫,只有M(WR)掛了之後,才會切換到M(R)上,這個時候M(R)就變成了讀寫庫。比如游戲系統,有很多Salve會掛載後面一個M(R)上面。
如果是電子商務類型的,這種讀多寫少的,一般是1個master拖上4到6個slave,所有slave掛載在一個master也足夠了。
切換的時候,把M1的讀寫業務切換到M2上面,然後把所有M1上的slave掛到M2上面去,如下所示:
如果是游戲行業的話,讀非常多蠻明顯的,會出現一般1個Master都會掛上10個以上的Slave的情況,所以這個時候,可以把一部分Slave掛載新的M(R)上面。至少會減少一些壓力,這樣至少服務器掛掉的時候,不會對所有的slave有影響,還有一部分在M(R)上的slave在繼續,不會對所有的slave受到影響,見圖3,
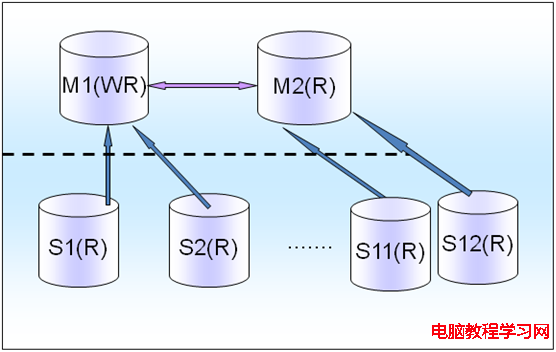
圖3
意味著讀並不會影響寫的效率,所以讀寫都可以放在一個M1(WR),而另外一個不提供讀也不提供寫,只提供standby冗余異地容災。
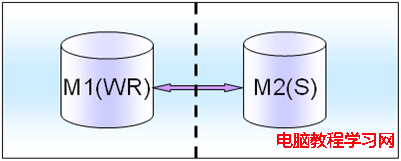
這個異地容災是非常重要的,否則如果是單機的,單邊的業務,萬一idc機房故障了,一般就會影響在線業務的,這種 造成業務2小時無法應用,對於在線電子商務交易來說,影響是蠻大的,所以為了最大限度的保證7*24小時,必須要做到異地容災,MM要跨idc機房。雖然對資源有一些要求,但是對HA來說是不可缺少的,一定要有這個MM機制。
做切換的時候,把所有的讀寫從M1直接切換到M2上就可以了。
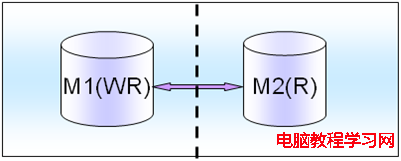
讀和寫差不多,但是讀不能影響寫的能力,把讀寫放在M1(WR)上,然後把一部分讀也放在M2(R)上面,當然M1和M2也是跨機房部署的。
切換的時候,把一部分讀和全部寫從M1切換到M2上就可以了。
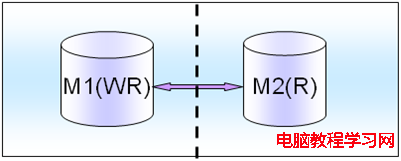
對讀一致性的權衡,如果是對讀寫實時性要求非常高的話,就將讀寫都放在M1上面,M2只是作為standby,就是采取和上面的一(4)的讀少寫多的一樣的架構模式。
比如,訂單處理流程,那麼對讀需要強一致性,實時寫實時讀,類似這種涉及交易的或者動態實時報表統計的都要采用這種架構模式
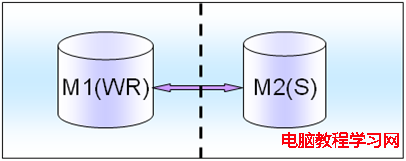
如果是弱一致性的話,可以通過在M2上面分擔一些讀壓力和流量,比如一些報表的讀取以及靜態配置數據的讀取模塊都可以放到M2上面。比如月統計報表,比如首頁推薦商品業務實時性要求不是很高,完全可以采用這種弱一致性的設計架構模式。
如果既不是很強的一致性又不是很弱的一致性,那麼我們就采取中間的策略,就是在同機房再部署一個S1(R),作為備庫,提供讀取服務,減少M1(WR)的壓力,而另外一個idc機房的M2只做standby容災方式的用途。
當然這裡會用到3台數據庫服務器,也許會增加采購壓力,但是我們可以提供更好的對外數據服務的能力和途徑,實際中盡可能兩者兼顧。
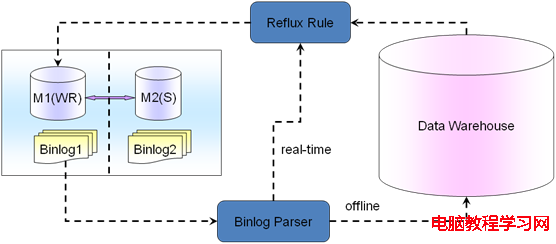
比如PV、UV操作、頁數的統計、流量的統計、數據的匯總等等,都可以劃歸為統計類型的業務。
數據庫上做大查詢的統計是非常消耗資源的。統計分為實時的統計和非實時的統計,由於mysql主從是邏輯sql的模式,所以不能達到100%的實時,如果是online要嚴格的非常實時的統計比如像火車票以及金融異地結算等的統計,mysql這塊不是它的強項,就只有查詢M1主庫來實現了。
A,但是對於不是嚴格的實時性的統計,mysql有個很好的機制是binlog,我們可以通過binlog進行解析Parser,解析出來寫入統計表進行統計或者發消息給應用端程序來進行統計。這種是准實時的統計操作,有一定的短暫的可接受的統計延遲現象,如果要100%實時性統計只有查詢M1主庫了。
通過binlog的方式實現統計,在互聯網行業,尤其是電商和游戲這塊,差不多可以解決90%以上的統計業務。有時候如果用戶或者客戶提出要實時read-time了,大家可以溝通一下為什麼需要實時,了解具體的業務場景,有些可能真的不需要實時統計,需要有所權衡,需要跟用戶和客戶多次有效溝通,做出比較適合業務的統計架構模型。
B,還有一種offline統計業務,比如月份報表年報表統計等,這種完全可以把數據放到數據倉庫裡面或者第三方Nosql裡面進行統計。
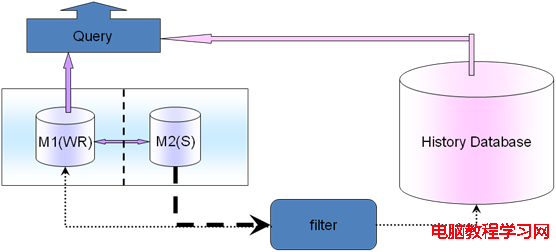
歷史數據遷移,需要盡量不影響現在線上的業務,盡量不影響現在線上的查詢寫入操作,為什麼要做歷史數據遷移?因為有些業務的數據是有時效性的,比如電商中的已經完成的歷史訂單等,不會再有更新操作了,只有很簡單的查詢操作,而且查詢也不會很頻繁,甚至可能一天都不會查詢一次。
如果這時候歷史數據還在online庫裡面或者online表裡面,那麼就會影響online的性能,所以對於這種,可以把數據遷移到新的歷史數據庫上,這個歷史數據庫可以是mysql也可以是nosql,也可以是數據倉庫甚至hbase大數據等。
實現途徑是通過slave庫查詢出所有的數據,然後根據業務規則比如時間、某一個緯度等過濾篩選出數據,放入歷史數據庫(History Databases)裡面。遷移完了,再回到主庫M1上,刪除掉這些歷史數據。這樣在業務層面,查詢就要兼顧現在實時數據和歷史數據,可以在filter上面根據遷移規則把online查詢和history查詢對接起來。比如說一個月之內的在online庫查詢一個月之前的在history庫查詢,可以把這個規則放在DB的遷移filter層和應用查詢業務模塊層。如果可以的話,還可以配置更細化,通過應用查詢業務模塊層來影響DB的遷移filter層,比如以前查詢分為一個月為基准,現在查詢業務變化了,以15天為基准,那麼應用查詢業務模塊層變化會自動讓DB的filter層也變化,實現半個自動化,更加智能一些。
像oracle這種基於rac基於共享存儲的方式,不需要sharding只需要擴從rac存儲就能實現了。但是這種代價相對會比較高一些,共享存儲一般都比較貴,隨著業務的擴展數據的爆炸式增長,你會不停累計你的成本,甚至達到一個天文數字。
目前這種share disk的方式,除了oracle的業務邏輯層做的非常完善之外其他的解決方案都還不是很完美。
Mysql的sharding也有其局限性,sharding之後的數據查詢訪問以及統計都會有很大的問題,mysql的sharding是解決share nothing的存儲的一種分布式的方法,大體上分為垂直拆分和水平拆分。
可以橫向拆分,可以縱向拆分,可以橫向縱向拆分,還可以按照業務拆分。
6.1.1橫向拆分
Mysql庫裡面的橫向拆分是指,每一個數據庫實例裡面都有很多個db庫,每一個db庫裡面都有A表B表,比如db1庫有A表B表,db2庫裡也有A表和B表,那麼我們把db1、db2庫的A表B表拆分出來,把一個庫分成2個,就拆分成db1、db2、db3、db4,其中db1庫和db2庫放A表數據,db3庫和db4庫放B表的數據,db1、db2庫裡面只有A表數據,db3、db4庫裡面只有B表的數據。
打個比方,作為電商來說,每個庫裡面都有日志表和訂單表,假如A表是日志表log表,B表是訂單表Order表,一般說來寫日志和寫訂單沒有強關聯性,我們可以講A表日志表和B表訂單表拆分出來。那麼這個時候就做了一次橫向的拆分工作,將A表日志表和B表訂單表拆分開來放在不同的庫,當然A表和B表所在的數據庫名也可以保持一致(PS:在不同的實例裡面),如下圖所示:
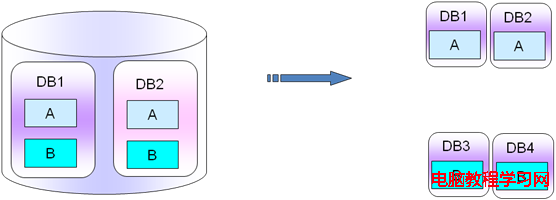
PS:這種拆分主要針對於不同的業務對表的影響不大,表之間的業務關聯很弱或者基本上沒有業務關聯。拆分的好處是不相關的數據表拆分到不同的實例裡面,對數據庫的容量擴展和性能提高的均衡來說,都是蠻有好處的。
6.1.2縱向拆分
把同一個實例上的不同的db庫拆分出來,放入單獨的不同實例中。這種拆分的適應場景和要求是db1和db2是沒有多少業務聯系的,類似6.1.2裡面的A表和B表那樣。如果你用到了跨庫業務同時使用db1和db2的話,個人建議要重新考慮下業務,重新梳理下盡量把一個模塊的表放在一個庫裡面,不要垮庫操作。
這種庫縱向拆分裡面,單獨的庫db1,表A和表B是強關聯的。如下圖所示:
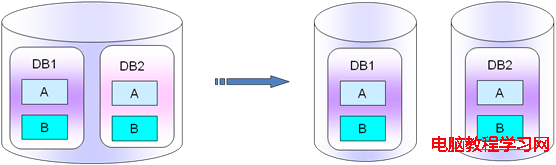
PS:看到很多使用mysql的人,總是把很多沒有業務關聯性的表放在一個庫裡面,或者總是把很多個的db庫放在同一個實例裡面,就像使用oracle那樣就一個instance的概念而已。Mysql的使用一大原則就是簡單,盡量單一,簡單的去使用mysql,庫要嚴格的分開;表沒有關系的,要嚴格拆分成庫。這樣的話擴展我們的業務就非常方便簡單了,只需要把業務模塊所在的db拆分出來,放入新的數據庫服務器上即可。