MySQL的主從同步機制非常方便的解決了高並發讀的應用需求,給Web方 面開發帶來了極大的便利。但這種方式有個比較大的缺陷在於MySQL的同步機制是依賴Slave主動向Master發請求來獲取數據的,而且由於服務器負 載、網絡擁堵等方面的原因,Master與Slave之間的數據同步延遲是完全沒有保證的。短在1秒內,長則幾秒、幾十秒甚至更長都有可能。
由於數據延遲問題的存在,當應用程序在Master上進行數據更新,然後又立刻需要從數據庫中讀取數據時,這時候如果應用程序從Slave上取數據(這也是當前Web開發的常規做法),就可能出現讀取不到期望的數據,造成程序運行異常。
解決這個問題有多種方式,比如最簡單的在所有的insert和update之後,強制sleep幾秒鐘。這是非常粗魯的方式,對於更新操作不是很高的中小型系統,此方式基本能解決問題。
另外一種方式是應用程序把被更新的數據保存在本機的內存(或者集中式緩存)中,如果在寫入數據完成後需要直接讀取數據,則從本機內存中讀取。這種方式的缺點是極大的增加了應用程序的復雜度,而且可靠性並不能完全得到保障。
使用MySQL Proxy可以很方便的解決這個問題。MySQL Proxy是基於MySQL Client 和 MySQL Server之間的代理程序,能夠完成對Client所發請求的監控、修改。從Client角度看,通過Proxy訪問Server和直接訪問Server沒有任何區別。對於既有的程序而言,只要把直接被訪問的Server的IP地址和端口號換成Proxy的IP地址和端口號就可以。
MySQL Proxy的工作原理也較簡單。在Proxy啟動時可以指定Proxy所需要使用的lua腳本,在lua腳本中預先實現6個方法:
當Proxy接收到Client請求時,在請求的不同的階段會調用上面的不同方法。這樣Proxy使用者就可以根據自己的業務需求,自由的實現這6個方法達到目的。
通過在read_query()中加入代碼,我們可以截取出當前的請求是insert、update還是select,然後把insert和update請求發送到Master中,把select請求發送到Slave中,這樣就解決了讀寫分離的問題。
在解決了讀寫分離後,如何解決同步延遲呢?
方法是在Master上增加一個自增表,這個表僅含有1個的字段。當Master接收到任何數據更新的請求時,均會觸發這個觸發器,該觸發器更新自增表中的記錄。如下圖所示:
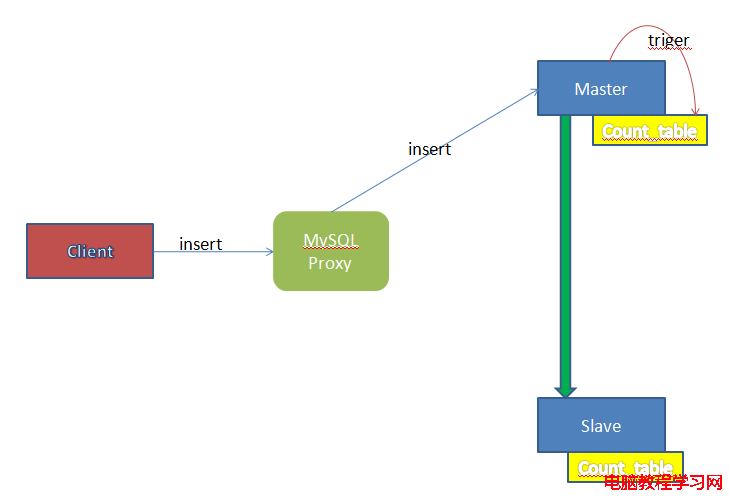
由於Count_table也參與Mysq的主從同步,因此在Master上作的Update更新也會同步到Slave上。當Client通過Proxy進行數據讀取時,Proxy可以先向Master和Slave的Count_table表發送查詢請求,當二者的數據相同時,Proxy可以認定Master和Slave的數據狀態是一致的,然後把select請求發送到Slave服務器上,否則就發送到Master上。如下圖所示:
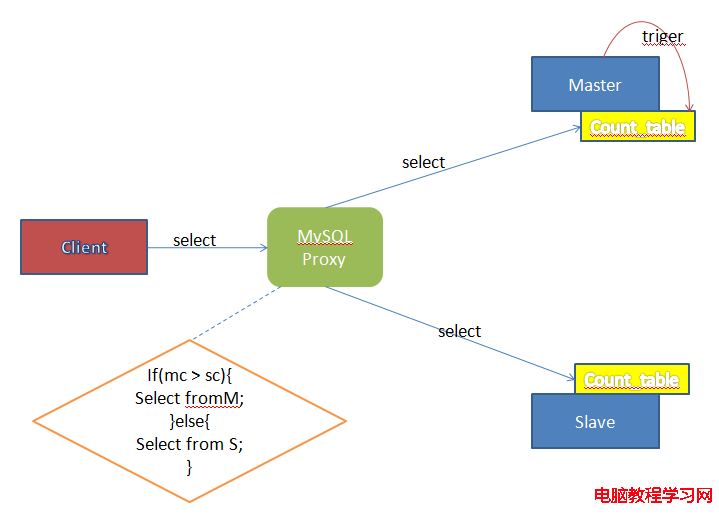
通 過這種方式,就可以比較完美的結果MySQL的同步延遲不可控問題。之所以所“比較完美”,是因為這種方案double了查詢請求,對Master和 Slave構成了額外的壓力。不過由於Proxy與真實的Mysql Server采用連接池的方式連接,因此額外的壓力還是可以接受的。