當select語句中有ORDER BY子句的時候,有可能會遇到using filesort的情況(explain)。
以下面的表結構和sql語句為例:
CREATE TABLE `tbl` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`a` VARCHAR(255) NOT NULL DEFAULT '',
`b` VARCHAR(255) DEFAULT NULL,
`c` CHAR(255) NOT NULL DEFAULT '',
`d` INT(11) DEFAULT NULL,
`e` INT(11) DEFAULT NULL,
`f` INT(11) NOT NULL DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1;
SELECT a,b,c FROM tbl WHERE d=1 ORDER BY e DESC
e字段上沒有索引,會引發filesort.
不過filesort也並不表示一定就會用到臨時文件,即使只在sort buffer中完成排序,在explain的時候,還是會顯示filesort。
mysql有2種filesort的算法:
1) original method
過程如下:
1. 讀取符合WHERE d=1 條件的全部記錄。
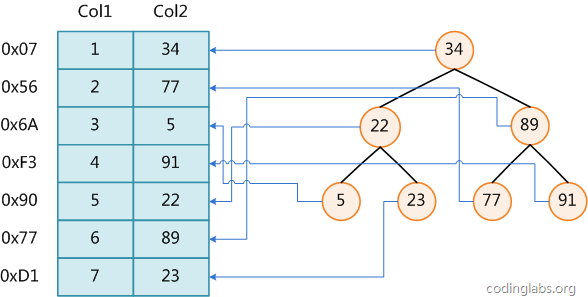
2. 對於1中的每一條記錄,在sort buffer中存儲 key與rowid,稱為一個pair:
|<key>|<rowid>|
<key>是order by的字段,在本例中是e,但是會經過Field::make_sort_key()的處理。
可以看到,雖然我們的select語句涉及到了很多字段,但是只有e字段出現在了sort buffer中,rowid可以認為是一個指向原始記錄的指針。
<rowid>的長度記為ref_length。
<key>與<rowid>的長度之和記為sort_length,沒錯,<rowid>也會參與到排序:
if (using_addon_fields())
{
res_length= addon_length;
}
else
{
//original method:
res_length= ref_length;
/*
The reference to the record is considered
as an additional sorted field
*/
sort_length+= ref_length;
}
3. 如果sort buffer足夠容納2中全部的pair,那麼就可以在內存中完成排序,否則在sort buffer寫滿的時候,在sort buffer中進行radixsort或者qsort或者stable_sort,然後把sort buffer寫入臨時文件,稱為一個sorted block。
4. 重復過程3,直到全部記錄都讀取完畢。
5. 在另外一個臨時文件中,merge 過程3中的各個sorted block。(multi-merge)。
6. 略。見文後的參考資料。
7. 在最後一次merge的過程中,只把rowid寫入result file。
這樣result file就是已排序狀態了。
8. 從result file中按順序讀出rowid,並去原始記錄中查詢。
可以看到,在過程1與過程8的時候,mysql對原始記錄進行了2次讀取。而且過程8更是一個隨機讀取過程。
為了避免重復讀取原始記錄,就出現了modified method。
2) modified method
過程如下:
1. 讀取符合WHERE d=1 條件的全部記錄。
2. 對於1中的每一條記錄,在sort buffer中存儲sql語句中涉及到的column與key,稱為一個tuple:
|<key>|<null bits>|<field a><field b>….|
<key> 仍然是經過處理的排序字段。在本例中為字段e。長度記為sort_length。
<field x> select語句中涉及到的其它字段,在本例中為字段abcde。(恩,d和e 也包含在內。忘記有沒有id字段了。)
<null bits> 每一個未被定義為not null 的 field對應一個bit,表示此field是否為null。
<null bits>與<field x>的長度之和記為 addon_length。
3. 當sort buffer寫滿的時候,在內存中sort,然後寫入臨時文件。
4. merge-sort 這個臨時文件,然後順序讀取此文件即可,不必再去原始記錄中查詢。(沒有隨機讀取操作)
modified method與original method比起來,只去原始記錄中讀取一次數據,不過也存在一個缺點,由於會把select語句涉及到的字段都寫入sort buffer,所以每行記錄會占用更多的內存空間,這樣就更容易把sort buffer寫滿並使用臨時文件。
如果original method可以在sort buffer中完成排序,而modified method卻要使用臨時文件的話,那麼modified method反而會比較慢一些。
現在,應該能夠理解,為什麼很多人都說select的時候盡量避免SELECT *了吧? select出的字段越少,sort buffer中就可以容納更多條tuple了。
優化器更傾向於modified method,不過當select語句涉及到BLOB或者TEXT字段的時候,就只能選擇original method了。
還有一種情況是,只有在 max_length_for_sort_data(默認值1024)的值大於e+a+b+c+d+e+1+id (排序字段+select語句中涉及到的全部字段再加上可以為null的字段個數轉化成占用字節數再加上主鍵)的情況下,才會采用modified method:
for (pfield= ptabfield; (field= *pfield) ; pfield++)
{
.......
.......
total_length+= field_length;
.......
.......
}
total_length+= (null_fields + 7) / 8;
if (total_length + sortlength > max_length_for_sort_data)
{
DBUG_ASSERT(addon_fields == NULL);
return NULL;
}
modified method需要更長時間的排序過程。
在mysql 5.7.3以前,modified method中有一個偷懶的做法:對於varchar(xx)類型的字段,在sort buffer或是臨時文件中為其分配空間的時候,分配出來的空間是xx字節,並非真實長度,比如varchar(255),即使真實長度為3,它在sort buffer中仍然會占用255字節,256 maybe.
這種做法非常便於計算每一個tuple的偏移量(畢竟每個tuple都是定長的)。代價是浪費了空間,更加容易導致臨時文件的使用,在確定要使用臨時文件的情況下,也會導致更多次的merge過程。
所以定義varchar(xx)的時候,xx控制的越小越好啦,雖然僅僅從存儲的角度來講,varchar(1)與varchar(255)並沒有什麼區別。
與varchar字段類似,char,或者其它可能為null的字段都有可能浪費空間。