mysql5.6主從復制第二部分
本來第二部分是想測試主服務器掛掉,提升從服務器的情況,
可是出了點點意外,改為測試某一台從服務器掛掉的時候,如何恢復。
主服務器掛掉的情況放到第三部分吧。
繼續用mysql::sandbox來測試。
主服務器(別名black)(server-id:1)安裝在 /home/modify/sandboxes/msb_5_6_10/ 使用5610端口。
從服務器(別名blue)(server-id:2)安裝在 /home/modify/sandboxes/msb_5_6_10_a/ 使用5611端口。
從服務器(別名green)(server-id:3)安裝在 /home/modify/sandboxes/msb_5_6_10_b/ 使用5612端口。
按照前一篇文章介紹的方法設置好一主二從的復制。
假設從服務器blue由於dba誤操作,直接更改了數據庫裡面的數據,
blue:
mysql [localhost] {msandbox} (test) > TRUNCATE TABLE t;
Query OK, 0 ROWS affected (0.01 sec)
mysql [localhost] {msandbox} (test) >
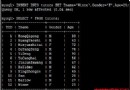
mysql [localhost] {msandbox} (test) > SHOW slave STATUS \G
*************************** 1. ROW ***************************
Slave_IO_State: Waiting FOR master TO send event
Master_Host: 127.0.0.1
Master_User: repl_user
Master_Port: 5610
Connect_Retry: 60
Master_Log_File: black-bin.000002
Read_Master_Log_Pos: 2048
Relay_Log_File: mysql_sandbox5611-relay-bin.000004
Relay_Log_Pos: 2218
Relay_Master_Log_File: black-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 2048
Relay_Log_Space: 2481
Until_Condition: NONE
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 05b47d41-7b10-11e2-9fff-00241db92e69
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has READ ALL relay log; waiting FOR the slave I/O thread TO UPDATE it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 05b47d41-7b10-11e2-9fff-00241db92e69:16-19
Executed_Gtid_Set: 05b47d41-7b10-11e2-9fff-00241db92e69:1-19,
4f65e570-7b32-11e2-a0de-00241db92e69:1
Auto_Position: 1
1 ROW IN SET (0.00 sec)
##可以停止復制了。
mysql [localhost] {msandbox} (test) > stop slave;
Query OK, 0 ROWS affected (1.36 sec)
可以看到Executed_Gtid_Set裡面多了一個 4f65e570-7b32-11e2-a0de-00241db92e69:1
考慮如何進行恢復。
比較靠譜的辦法是不操作主服務器, 導出從服務器green的數據,然後再導入blue中。
green:
mysql [localhost] {msandbox} (test) > stop slave;
mysql [localhost] {msandbox} (test) > FLUSH TABLES WITH READ LOCK;
Query OK, 0 ROWS affected (0.00 sec)
從green導出數據,端口是5612
[root@H209 msb_5_6_10_b]# /home/modify/mysql/5.6.10/bin/mysqldump -uroot -p -h127.0.0.1 -P5612 --all-databases --triggers --routines --events >all.sql
Enter password:
[root@H209 msb_5_6_10_b]#
green:
mysql [localhost] {msandbox} (test) > UNLOCK TABLES;
Query OK, 0 ROWS affected (0.00 sec)
mysql [localhost] {msandbox} (test) > START slave;
把數據導入blue,端口為5611
[root@H209 msb_5_6_10_b]# /home/modify/mysql/5.6.10/bin/mysql -uroot -p -h127.0.0.1 -P5611 < all.sql
Enter password:
ERROR 1840 (HY000) at line 24: GTID_PURGED can only be set when GTID_EXECUTED is empty.
額…出錯了..
all.sql:
21 -- GTID state at the beginning of the backup
22 --
23
24 SET @@GLOBAL.GTID_PURGED='05b47d41-7b10-11e2-9fff-00241db92e69:1-19';
25
blue:
mysql [localhost] {msandbox} (test) > SHOW global VARIABLES LIKE '%GTID%';
+--------------------------+-----------------------------------------------------------------------------------+
| Variable_name | VALUE |
+--------------------------+-----------------------------------------------------------------------------------+
| enforce_gtid_consistency | ON |
| gtid_executed | 05b47d41-7b10-11e2-9fff-00241db92e69:1-19,
4f65e570-7b32-11e2-a0de-00241db92e69:1 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 05b47d41-7b10-11e2-9fff-00241db92e69:1-15 |
+--------------------------+-----------------------------------------------------------------------------------+