對於mysql數據庫架構為雙主復制模式的不少技術朋友都非常困惑,如何准確判斷mysqld服務是否能正常提供服務,以及能否自動判斷並且進行主機的切換?同時,對mysqld服務的檢測機制要求消耗資源少、判斷簡單且准確、開發和維護成本低等。我們在實際的生產環境檢測過程中,也曾經犯過錯誤,為此寫一篇短小的文章,把相關經驗、思路、做法分享給大家,為更多的技術朋友起到答疑解惑。
要想做到自動切換提供數據庫服務請求的主備服務器關鍵,就是要確定雙主復制架構中的mysql數據庫實例是否能正常提供服務請求,最讓人頭疼的就是mysqld服務出現hang住的情況。那麼mysqld服務hang住的時候,會有哪些表象呢?先列出本人及圈內朋友們出現過的情況:
● 不能對數據庫中的對象或數據執行修改性操作,但能正常執行查詢操作;
● 能對系統數據庫(備注:mysql、information_schema)的對象或數據進行查詢操作,不能對非系統數據庫的對象和數據;
● 只能對虛擬數據庫(備注: information_schema)的對象及數據進行查詢操作,不能對其他數據庫的對象和數據;
● 不能對對任何數據庫的對象或數據進行查詢操作,但是能執行SHOW PROCESSLIST;
● 不能對對任何數據庫的對象或數據進行查詢操作,也不能執行SHOW PROCESSLIST,但是可以執行部分SHOW操作,例如:SHOW STATUS;
● 其他,還未發現的狀態信息;
針對上述mysqld服務hang住的情況做一個分析及匯總,可以發現其有一些共同特征,總結如下:
● mysqld服務存在,且能ping或telnet;
● 能接受客戶端發送過來的請求,但是不繼續處理,而是停留在其發生hang住的當下SQL執行的狀態;
● 若能執行SHOW PROCESSLIST的話,能看到所有的SQL執行狀態停留不變;
● 數據庫服務器的LOAD會突然下降,甚至LOAD下降為0,CPU、IO等都會接近沒負荷狀態;
● 若mysqld服務發生hang住的時候,一般都無法對數據庫的對象或數據執行修改性質的操作;
文章開篇描述了mysqld服務hang住的時候,mysqld接受、處理服務請求的情況,以及數據庫服務器的狀態信息,既然可以發現這些特征,那麼對於常用檢測mysqld服務是否還活著或者網絡是否通的辦法:
● ping或telnet mysqld服務的端口;
● 通過執行SHOW 命令;
● 通過執行SELECT查詢操作;
上述三類檢測辦法是否能真正做到准確檢測呢?答案是:NO,只能准確監測到mysqld進程是否活著、程序與數據庫服務器之間的網絡是否暢通,對於mysqld服務能否正常接收和完成處理請求,就無法做到或者部分做到,綜合上述分析信息,以及從目前我們將近三年實施效果看,對數據庫中的數據進行修改操作,再配合程序對數據修改操作的判斷邏輯是最穩妥的方法,詳細步驟:
● 檢測頻率為:每隔10S,對當前提供服務的mysqld數據庫實例上的檢測表,做一次UPDATE操作,探測數據庫實例是否正常提供服務;
● 若上一次數據庫實例服務檢測操作,沒有正常返回更新信息,則每隔1S做一次數據庫檢測表的UPDATE操作,總共做2次探測;
● 若前兩個步驟的數據庫實例服務探測結束,當前提供服務的數據庫實例服務都沒恢復正常,則每隔5MS對數據庫檢測表再做一次UPDATE操作,總共檢測三次,若還是沒有正常返回信息,則認定此數據庫實例服務不能正常接收服務請求;
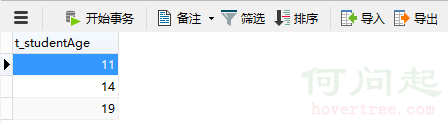
用於執行數據庫實例服務檢測的表結構和UPDATE操作SQL為:
● MySQL5.0及以下版本的UPDATE操作SQL
● MySQL5.1及以上版本的UPDATE操作SQL
備注:
對於支持MIXED、ROW復制模式的版本,必須規避MySQL雙主復制過程中,可能出現主從執行更新操作SQL語句的被修改數據不一致的問題,從而導致復制中斷,為此我們對數據庫實例服務檢測的更新操作不記錄到二進制日志文件中,也即不會復制到其各自的從服務器。
另外,建議大家把monitor_db表創建到test數據庫,或者類似test功能的數據庫中,存儲引擎建議一定要是:InnoDB,對於檢測頻率可以根據自己對數據安全性要求,而調整為自己能接受的。
若mysqld服務出現hang住的時候,正常關閉mysqld服務的辦法都無效,只有對mysqld服務進程進行操作系統級別的kill -9 操作,然後再啟動mysqld服務實例,等待其自動進行回滾操作結束,才算啟動成功,建議大家別用mysql5.0.82及前後版本,存在一些BUG,很容易導致出現hang的情況。