[TOC]
在項目過程中遇到一個看似極為基礎的問題,但是在深入思考後還是引出了不少問題,覺得有必要把這一學習過程進行記錄。
優點:
1、數據庫自動編號,速度快,而且是增量增長,聚集型主鍵按順序存放,對於檢索非常有利。
2、 數字型,占用空間小,易排序,在程序中傳遞方便。
缺點:
1、不支持水平分片架構,水平分片的設計當中,這種方法顯然不能保證全局唯一。
2、表鎖
在MySQL5.1.22之前,InnoDB自增值是通過其本身的自增長計數器來獲取值,該實現方式是通過表鎖機制來完成的(AUTO-INC LOCKING)。鎖不是在每次事務完成後釋放,而是在完成對自增長值插入的SQL語句後釋放,要等待其釋放才能進行後續操作。比如說當表裡有一個auto_increment字段的時候,innoDB會在內存裡保存一個計數器用來記錄auto_increment的值,當插入一個新行數據時,就會用一個表鎖來鎖住這個計數器,直到插入結束。如果大量的並發插入,表鎖會引起SQL堵塞。
在5.1.22之後,InnoDB為了解決自增主鍵鎖表的問題,引入了參數innodb_autoinc_lock_mode:
3、自增主鍵不連續
Create Table: CREATE TABLE `tmp_auto_inc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`talkid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=gbk
1 row in set (0.00 sec) 當插入10條記錄的時候,因為AUTO_INCREMENT=16,所以下次再插入的時候,主鍵就會不連續。
優點
1、全局唯一性、安全性、可移植性。
2、能夠保證獨立性,程序可以在不同的數據庫間遷移,效果不受影響。
3、保證生成的ID不僅是表獨立的,而且是庫獨立的,在你切分數據庫的時候尤為重要
缺點
1、針對InnoDB引擎會徒增IO壓力,InnoDB為聚集主鍵類型的引擎,數據會按照主鍵進行排序,由於UUID的無序性,InnoDB會產生巨大的IO壓力。InnoDB主鍵索引和數據存儲位置相關(簇類索引),uuid 主鍵可能會引起數據位置頻繁變動,嚴重影響性能。
2、UUID長度過長,一個UUID占用128個比特(16個字節)。主鍵索引KeyLength長度過大,而影響能夠基於內存的索引記錄數量,進而影響基於內存的索引命中率,而基於硬盤進行索引查詢性能很差。嚴重影響數據庫服務器整體的性能表現。
所謂自定義序列表,就是在庫中建一張用於生成序列的表來存儲序列信息,序列生成的策略通過程序層面來實現。如下所示,構建一張序列表:
CREATE TABLE `sequence` (
`name` varchar(50) NOT NULL,
`id` bigint(20) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`name`)
) ENGINE=InnoDB;注意區別,id字段不是自增的,也不是主鍵。在使用前,我們需要先插入一些初始化數據:
INSERT INTO `sequence` (`name`) VALUES
('users'), ('photos'), ('albums'), ('comments');接下來,我們可以通過執行下面的SQL語句來獲得新的照片ID:
UPDATE `sequence` SET `id` = LAST_INSERT_ID(`id` + 1) WHERE `name` = 'photos';
SELECT LAST_INSERT_ID();我們執行了一個更新操作,將id字段增加1,並將增加後的值傳遞到LAST_INSERT_ID函數, 從而指定了LAST_INSERT_ID的返回值。
實際上,我們不一定需要預先指定序列的名字。如果我們現在需要一種新的序列,我們可以直接執行下面的SQL語句:
INSERT INTO `sequence` (`name`) VALUES('new_business') ON DUPLICATE KEY UPDATE `id` = LAST_INSERT_ID(`id` + 1);
SELECT LAST_INSERT_ID();這種方案的問題在於序列生成的邏輯脫離了數據庫層,由應用層負責,增加了開發復雜度。當然,其實可以用spring來解決這一問題,因為在spring JDBC中已經對這種序列生成邏輯進行了簡單的封裝。
我們可以看一下spring的相關源代碼:MySQLMaxValueIncrementer.

@Override
protected synchronized long getNextKey() throws DataAccessException {
if (this.maxId == this.nextId) {
/*
* Need to use straight JDBC code because we need to make sure that the insert and select
* are performed on the same connection (otherwise we can't be sure that last_insert_id()
* returned the correct value)
*/
Connection con = DataSourceUtils.getConnection(getDataSource());
Statement stmt = null;
try {
stmt = con.createStatement();
DataSourceUtils.applyTransactionTimeout(stmt, getDataSource());
// Increment the sequence column...
String columnName = getColumnName();
stmt.executeUpdate("update "+ getIncrementerName() + " set " + columnName +
" = last_insert_id(" + columnName + " + " + getCacheSize() + ")");
// Retrieve the new max of the sequence column...
ResultSet rs = stmt.executeQuery(VALUE_SQL);
try {
if (!rs.next()) {
throw new DataAccessResourceFailureException("last_insert_id() failed after executing an update");
}
this.maxId = rs.getLong(1);
}
finally {
JdbcUtils.closeResultSet(rs);
}
this.nextId = this.maxId - getCacheSize() + 1;
}
catch (SQLException ex) {
throw new DataAccessResourceFailureException("Could not obtain last_insert_id()", ex);
}
finally {
JdbcUtils.closeStatement(stmt);
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
else {
this.nextId++;
}
return this.nextId;
}
spring的實現也就是通過update語句對incrementerName表裡的columnName 列進行遞增,並通過mysql的last_insert_id()返回最近生成的值。並保證了事務性及方法的並發支持。只是這個實現有些過於簡單,比如:一個表對應一個序列的做法在實際應用開發中顯得過於零碎,所以在實際應用中需要對其實現進行修改,實現一條記錄對應一個序列的策略。另外對水平分片的支持並不在這一實現考慮范圍內。同時,這種做法依然無法回避表鎖的機制,所以這裡通過CacheSize()的做法,實現了一次申請並緩存在內存中,以減少表鎖的發生頻率。
由於UUID出現重復的概率基本可以忽略,所以對分片是天生支持的。
單獨建立一個庫用來生成ID,在Shard中的每張表在這個ID庫中都有一個對應的表,而這個對應的表只有一個字段, 這個字段是自增的。當我們需要插入新的數據,我們首先在ID庫中的相應表中插入一條記錄,以此得到一個新的ID, 然後將這個ID作為插入到Shard中的數據的主鍵。這個方法的缺點就是需要額外的插入操作,如果ID庫變的很大, 性能也會隨之降低。所以一定要保證ID庫的數據集不要太大,一個辦法是定期清理前面的記錄
這種做法是通過聯合主鍵的策略,即通過兩個字段來生成一個唯一標識,前半部分是分片標識符,後半部分是本地生成的標識符(比如使用AUTO_INCREMENT生成)
這種做法可以基於上面提到的自定義序列表的方法的基礎上,做一些技巧性的調整。即如下:
UPDATE `sequence` SET `id` = LAST_INSERT_ID(`id` + 1) WHERE `name` = 'photos';
SELECT LAST_INSERT_ID();這裡的id初始值設定上要求不同的分片取不同的值,且必須連續。同時將每次遞增的步長設定為服務器數目。
比如有3台機器,那麼我們只要將初始值分別設置為1,2,3. 然後執行下面的語句即可:
UPDATE `sequence` SET `id` = LAST_INSERT_ID(`id` + 3) WHERE `name` = 'photos';
SELECT LAST_INSERT_ID();這就可以解決主鍵生成沖突的問題。但是如果在運行一段時間後要進行動態擴充分片數的時候,需要對序列初始值做一次調整,以確保其連續性,否則依然可能存在沖突的可能。當然這些邏輯可以封裝在數據訪問層的代碼中。
表中每一行都應該有可以唯一標識自己的一列(或一組列)。雖然並不總是都需要主鍵,但大多數數據庫設計人員都應保證他們創建的每個表有一個主鍵,以便於以後數據操縱和管理。其實即使你不建主鍵,MySQL(InnoDB引擎)也會自己建立一個隱藏6字節的ROWID作為主鍵列,詳細可以參見[這裡]
因為,InnoDB引擎使用聚集索引,數據記錄本身被存於主索引(一顆B+Tree)的葉子節點上。這就要求同一個葉子節點內(大小為一個內存頁或磁盤頁)的各條數據記錄按主鍵順序存放,因此每當有一條新的記錄插入時,MySQL 會根據其主鍵將其插入適當的節點和位置,如果頁面達到裝載因子(InnoDB默認為15/16),則開辟一個新的頁(節點)
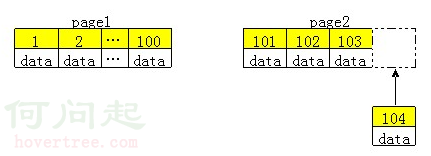
所以在使用innoDB表時要避免隨機的(不連續且值的分布范圍非常大)聚簇索引,特別是針對I/O密集型的應用。例如:從性能角度考慮,使用UUID的方案就會導致聚簇索引的插入變得完全隨機。
關於主鍵的類型選擇上最常見的爭論是用整型還是字符型的問題,關於這個問題《高性能MySQL》一書中有明確論斷:
整數通常是標識列的最好選擇,因為它很快且可以使用AUTO_INCREAMENT,如果可能,應該避免使用字符串類型作為標識列,因為很消耗空間,且通常比數字類型慢。
如果是使用MyISAM,則就更不能用字符型,因為MyISAM默認會對字符型采用壓縮引擎,從而導致查詢變得非常慢。
參考:
1、http://www.cnblogs.com/lsx1993/p/4663147.html
2、http://www.cnblogs.com/zhoujinyi/p/3433823.html
3、http://www.zolazhou.com/posts/primary-key-selection-in-database-partition-design/
4、《高性能MySQL》
5、《高可用MySQL》