本文以MySQL數據庫為研究對象,討論與數據庫索引相關的一些話題。特別需要說明的是,MySQL支持諸多存儲引擎,而各種存儲引擎對索引的支持也各不相同,因此MySQL數據庫支持多種索引類型,如BTree索引,哈希索引,全文索引等等。為了避免混亂,本文將只關注於BTree索引,因為這是平常使用MySQL時主要打交道的索引,至於哈希索引和全文索引本文暫不討論。
文章主要內容分為三個部分。
第一部分主要從數據結構及算法理論層面討論MySQL數據庫索引的數理基礎。
第二部分結合MySQL數據庫中MyISAM和InnoDB數據存儲引擎中索引的架構實現討論聚集索引、非聚集索引及覆蓋索引等話題。
第三部分根據上面的理論基礎,討論MySQL中高性能使用索引的策略。
看一個例子:
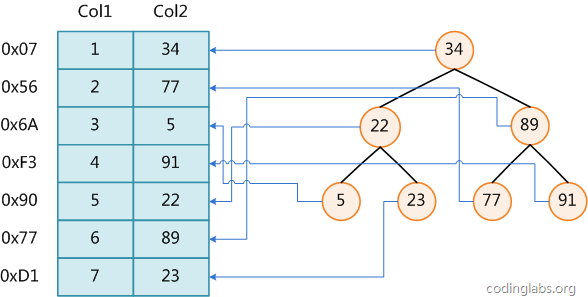
圖1
圖1展示了一種可能的索引方式。左邊是數據表,一共有兩列七條記錄,最左邊的是數據記錄的物理地址(注意邏輯上相鄰的記錄在磁盤上也並不是一定物理相鄰的)。為了加快Col2的查找,可以維護一個右邊所示的二叉查找樹,每個節點分別包含索引鍵值和一個指向對應數據記錄物理地址的指針,這樣就可以運用二叉查找在O(log2n)O(log2n)的復雜度內獲取到相應數據。
雖然這是一個貨真價實的索引,但是實際的數據庫系統幾乎沒有使用二叉查找樹或其進化品種紅黑樹(red-black tree)實現的,原因會在下文介紹。