explain對我們優化sql語句是非常有幫助的。可以通過explain+sql語句的方式分析當前sql語句。
EXPLAIN SELECT dt,method,url FROM app_log WHERE id=11789

table
顯示這一行數據屬於哪張表,若在查詢中為select起了別名,則顯示別名。
EXPLAIN SELECT dt,method,url FROM app_log AS temp WHERE id=11789

type
在表裡查到結果所用的方式。包括(性能有差——>高): All | index | range | ref | eq_ref | const,system | null |
all:全表掃描,MySQL 從頭到尾掃描整張表查找行。
EXPLAIN SELECT dt,method,url FROM app_log AS temp LIMIT 100

注意:這裡雖然使用limit但並不能改變全表掃描。
index:按索引掃描表,雖然還是全表掃描,但優點是索引是有序的。
EXPLAIN SELECT id FROM app_log AS temp LIMIT 100

range:以范圍的方式掃描索引。比較運算符,以及in的type都是range。
EXPLAIN SELECT * FROM app_log AS temp WHERE id>100 LIMIT 199

ref:非唯一性索引訪問
EXPLAIN SELECT * FROM app_log AS temp WHERE dt='2015-01-02' LIMIT 199

eq_ref:使用唯一性索引查找(主鍵或唯一索引)
EXPLAIN SELECT * FROM app_log JOIN app_details_log USING(id)

先全表掃描了app_details_log表,然後在對app_log進行eq_ref查找。因為app_log的id字段是主鍵。如果此時刪除app_log的id為主鍵,則都會進行全表掃描。
const:常量,在整個查詢過程中這個表最多只會有一條匹配的行,比如主鍵 id=1 就肯定只有一行,只需讀取一次表數據便能取得所需的結果,且表數據在分解執行計劃時讀取。
EXPLAIN SELECT * FROM app_log WHERE id=11790

注意:system 是 const 類型的特例,當表只有一行時就會出現 system 。
null:在優化的過程已經得到結果,不再需要訪問表或索引。例如表中並不存在id=1000的記錄。
EXPLAIN SELECT * FROM app_log WHERE id=1000

possible_keys
可能被用到的索引。
EXPLAIN SELECT * FROM app_log WHERE id>100 LIMIT 100 ;

Key
查詢過程中實際用到的索引,例子如上圖,實際用的索引列為主鍵列。
key_len
索引字段最大可能使用的長度。例如上圖中,Key_len:4,因為主鍵是int類型,長度為4.
ref
指出對key列所選擇的索引的查找方式,常見的有const,func,null,具體字段名。當key列為null,即不使用索引時,此值也為null.
rows
mysql估計需要掃描的行數,只是一個估算。
Extra
這個顯示其他的一些信息,但對優化sql也非常的重要。
using Index:此查詢使用了覆蓋索引(Convering Index),即通過索引就能返回結果,無需訪問表。弱沒顯示“Using Index”表示讀取了表數據。
EXPLAIN SELECT id FROM app_log;

因為 id 為主鍵索引,索引中直接包含了 id 的值,所以無需訪問表,直接查找索引就能返回結果。
using where:mysql從存儲引擎收到行後再進行“後過濾(Post-filter)”。後過濾:先讀取整行數據,再檢查慈航是否符合where的條件,符合就留下,不符合便丟棄。檢測是在讀取行後進行的,所以叫後過濾。
EXPLAIN SELECT id FROM app_log WHERE id>100 LIMIT 100;

using temporary:使用到臨時表,在使用臨時表的時候,Extra為這個值。
using filesort:若查詢所需的排序與使用的索引的排序一直,因為索引已排序,因此按索引的順序讀取結果返回,否則,在取到結果後,還需要按查詢所需的順序對結果進行排序,這時就會出現using filesort。
EXPLAIN SELECT id FROM app_log WHERE id>100 GROUP BY dt;
![]()
我需要對app_log的表按時間進行分組,顯示每個小時的人數。
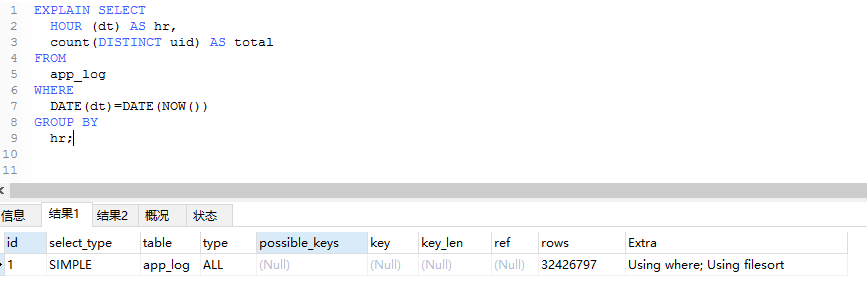
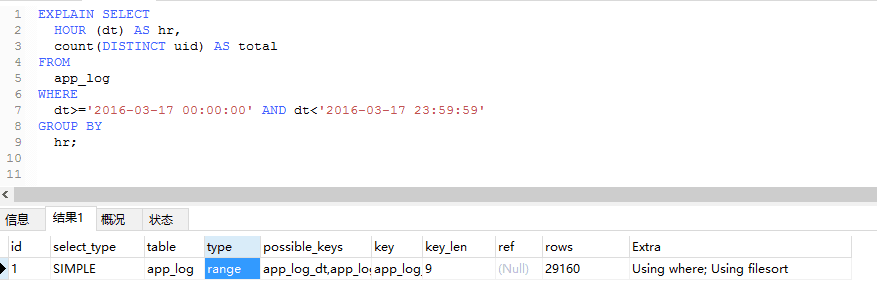
通過上面你可以看到type一個為all,一個為range。為all的查詢需要23+s,而下面的則只需要0.3s。通過rows也能看出優化後,表掃描的行數變化。
參考資料
《高性能 Mysql》(第三版)