查詢性能優化
1. 為什麼查詢速度會慢?
1). 如果把查詢看作是一個任務,那麼它由一系列子任務組成,每個子任務都會消耗一定的時間。如果要優化查詢,實際上要優化其子任務,要麼消除其中一些子任務,要麼減少子任務的執行次數,要麼讓子任務運行的更快。
2). 通常來說,查詢的生命周期大致可以按照順序來看:從客戶端,到服務器端,然後在服務器上進行解析,生成執行計劃,執行,並返回結果給客戶端。其中"執行"可以認為是整個生命周期中最重要的階段,這其中包括
大量為了檢索數據到存儲引擎的調用以及調用後的數據處理,包括排序、分組等。
3). 在完成這些任務的時候,查詢需要在不同的地方花費時間,包括網絡,CPU計算,生成統計信息和執行計劃、鎖等待(互斥等待)等操作,尤其是向底層存儲引擎檢索數據的調用操作,這些調用需要在內存中操作、CPU操作
和內存不足時導致的IO操作上消耗時間,根據上下文不同,可能會產生大量的上下文切換以及系統調用。
2. 慢查詢基礎:優化數據訪問
查詢性能低下最基本的原因是訪問的數據太多。某些查詢可能不可避免地需要篩選大量數據,但這並不常見。大部分性能低下的查詢都可以通過減少訪問的數量的方式進行優化。對於低效查詢,可以通過下面兩個步驟來分析:
1). 確認應用程序是否在檢索大量超過需要的數據。這通常意味著訪問了太多的行,但有時候可能是訪問了太多的列。
2). 確認MySQL服務器層是否在分析大量超過需要的數據行。
2.1 是否向數據庫請求了不需要的數據
1). 一些典型案例
a. 查詢不需要的記錄:一個常見的錯誤是常常會誤以為MySQL會只返回需要的數據,實際上MySQL卻是返回全部結果集在進行計算。最簡單有效的解決方法是在這樣的查詢後面加上LIMIT。
b. 多表關聯時返回全部列
c. 總是取出全部列:每次看到SELECT * 的時候都需要用懷疑的眼光審視,是不是真的需要返回全部列?取出全部列會讓優化器無法完成索引覆蓋掃描這類優化,還會為服務器帶來額外的網絡、IO、內存和
CPU的消耗。
d. 重復查詢相同的數據:比較好的方案是,當初次查詢的時候將這個數據緩存起來,需要的時候從緩存中取出,這樣性能會更好。
2.2 MySQL是否在掃描額外的記錄:
1). 對於MySQL,最簡單的衡量查詢開銷的三個指標如下:
a. 響應時間:響應時間是兩部分之和:服務時間和排隊時間。服務時間是指數據庫處理這個查詢真正花多長時間。排隊時間是指服務器因為等待某些資源而沒有真正執行查詢的時間--可能是等IO操作完成,也可能
是等待行鎖等等。
b. 掃描的行數和返回的行數:分析查詢時,查看該查詢掃描的行數是非常有幫助的。這在一定程度上能夠說明該查詢找到需要的數據的效率高不高。
c. 掃描的行數和訪問類型:在評估查詢開銷的時候,需要考慮一下從表中找到某一行數據的成本。MySQL有好幾種訪問方式可以查詢並返回一行結果。有些方式可能需要掃描很多行才能返回一行結果,也有些訪問
方式可能無需掃描就能返回結果。
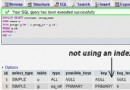
在EXPALIN語句中的type列反應了訪問類型。訪問類型有很多種,從全表掃描到索引掃描、范圍掃描、唯一索引掃描、常數引用等。這裡列的這些,速度是從慢到快,掃描的行數是從多到少。你不要記住這
些訪問類型,但需要明白掃描表、掃描索引、范圍訪問和單值訪問的概念。
2). 一般MySQL能使用如下三種方式應用WHERE條件,從好到壞依次為:
a. 在索引中使用WHERE條件來過濾不匹配的記錄。這是在存儲引擎層完成的。
b. 使用索引覆蓋掃描(在Extra列中出現Using index)來返回記錄,直接從索引中過濾不需要的記錄並返回命中的結果。這是在MySQL服務器層完成的,但無需再回表查詢記錄。
c. 從數據表中返回數據,然後過濾掉不滿足條件的記錄(在Extra列中出現Using Where)。這在MySQL服務器層完成,MySQL需要先從數據表讀取記錄然後過濾。
3). 如果發現查詢需要掃描大量的數據但只返回少數的行(使用聚合函數等),那麼通常可以嘗試下面的技巧去優化它們:
a. 使用索引覆蓋掃描,把所有需要用的列都放到索引中,這樣存儲引擎無需回表獲取對應行就可以返回結果了。
b. 改變庫表結構。例如使用單獨的匯總表。
c. 重寫這個復雜的查詢,讓MySQL優化器能夠以更優的方式執行這個查詢。
3. 重構查詢的方式:有時候,可以將查詢轉換一種寫法讓其返回一樣的結果,但性能更好。
3.1 一個復雜查詢還是多個簡單查詢
a. 設計查詢的時候一個需要考慮的重要問題是,是否需要將一個復雜的查詢分成過個簡單的查詢。在傳統實現中,總是強調需要數據庫層完成盡可能多的工作,這樣做的邏輯在於以前總是認為網絡通信、
查詢解析和優化是一件代價很高的事情。但是這樣的想法對於MySQL並不適用,MySQL從設計上讓連接和斷開連接都很輕量級,在返回一個小的查詢結果方面很高效。現代的網絡速度比以前要快的多,
無論是帶寬還是延遲。
b. MySQL內部每秒能夠掃描內存中上百萬行數據,相比之下,MySQL響應數據給客戶端就慢得多了。在其他條件都相同的時候,使用盡可能少的查詢當然是更好的。但是有時候,將一個大查詢分解成
多個小查詢也是很有必要的。
3.2 切分查詢:刪除舊數據是一個很好的例子。定期清除大量數據時,乳溝用一個大的語句一次性刪除完成的話,則可能需要一次鎖住很多數據、占滿整個事務日志、耗盡系統資源、阻塞很多小的但很重要的查詢。
同時需要注意,如果每次刪除數據後,都暫停一會再做下一次刪除,可以經服務器壓力分散到很長的時間段中。
3.3 分解關聯查詢:
分解關聯查詢的方式重構查詢有如下的優勢:
a. 讓緩存的效率更高。許多應用程序可以方便地使用緩存單表查詢對應的結果集。
b. 將查詢分解後,執行單個查詢可以減少鎖的競爭。
c. 在應用層做關聯,可以更容易對數據庫進行拆分,更容易做到高性能和可擴展性。
d. 查詢本身效率也可能會有所提升。
e. 可以減少冗余記錄的查詢。管理查詢中可能需要重復地訪問一部分數據。
f. 更進一步,這樣做相當於在應用中實現了哈希關聯,而不是使用MySQL的嵌套循環關聯。某些場景哈希關聯的效率要高很多。
4. 查詢執行的基礎:
查詢執行的過程:
1). 客戶單發送一條查詢給服務器
2). 服務器檢查查詢緩存,如果命中了緩存,則立刻返回存儲在緩存中的結果。否則進入下一階段。
3). 服務器端進行SQL解析、預處理,再由優化器生成對應的執行計劃。
4). MySQL根據優化器生成的執行計劃,調用存儲引擎的API來執行查詢。
5). 將結果返回給客戶端。