###11數據表中的數據類型
* A:MySQL中的我們常使用的數據類型如下
詳細的數據類型如下(不建議詳細閱讀!)
分類 類型名稱 說明
整數類型
tinyInt 很小的整數
smallint 小的整數
mediumint 中等大小的整數
int(integer) 普通大小的整數
小數類型
float 單精度浮點數
double 雙精度浮點數
decimal(m,d) 壓縮嚴格的定點數
日期類型
year YYYY 1901~2155
time HH:MM:SS -838:59:59~838:59:59
date YYYY-MM-DD 1000-01-01~9999-12-3
datetime YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59
timestamp YYYY-MM-DD HH:MM:SS 1970~01~01 00:00:01 UTC~2038-01-19 03:14:07UTC
文本、二進制類型
CHAR(M) M為0~255之間的整數
VARCHAR(M) M為0~65535之間的整數
TINYBLOB 允許長度0~255字節
BLOB 允許長度0~65535字節
MEDIUMBLOB 允許長度0~167772150字節
LONGBLOB 允許長度0~4294967295字節
TINYTEXT 允許長度0~255字節
TEXT 允許長度0~65535字節
MEDIUMTEXT 允許長度0~167772150字節
LONGTEXT 允許長度0~4294967295字節
VARBINARY(M) 允許長度0~M個字節的變長字節字符串
BINARY(M) 允許長度0~M個字節的定長字節字符串
###12創建數據庫操作
* A: 創建數據庫
格式:
* create database 數據庫名;
* create database 數據庫名 character set 字符集;
例如:
#創建數據庫 數據庫中數據的編碼采用的是安裝數據庫時指定的默認編碼 utf8
CREATE DATABASE day21_1;
#創建數據庫 並指定數據庫中數據的編碼
CREATE DATABASE day21_2 CHARACTER SET utf8;
* B: 查看數據庫
查看數據庫MySQL服務器中的所有的數據庫:
show databases;
查看某個數據庫的定義的信息:
show create database 數據庫名;
例如:
show create database day21_1;
* C: 刪除數據庫
drop database 數據庫名稱;
例如:
drop database day21_2;
* D: 其他的數據庫操作命令
切換數據庫:
use 數據庫名;
例如:
use day21_1;
* E: 查看正在使用的數據庫:
select database();
###13創建數據表格式
* A:格式:
create table 表名(
字段名 類型(長度) 約束,
字段名 類型(長度) 約束
);
例如:
###創建分類表
CREATE TABLE sort (
sid INT, #分類ID
sname VARCHAR(100) #分類名稱
);
======================================================================================
###14約束
* A: 約束的作用:
create table 表名(
列名 類型(長度) 約束,
列名 類型(長度) 約束
);
限制每一列能寫什麼數據,不能寫什麼數據。
* B: 哪些約束:
主鍵約束
非空約束
唯一約束
外鍵約束
###15SQL代碼的保存
* A: 當sql語句執行了,就已經對數據庫進行操作了,一般不用保存操作
在SQLyog 中Ctrl + S 保存的是寫sql語句。
###16創建用戶表
* A: 創建用戶表:
需求:創建用戶表,用戶編號,姓名,用戶的地址
* B: SQL語句
CREAT TABLE users (
uid INT,
uname VARCHAR(20),
uaddress VARCHAR(200)
);
###17主鍵約束
* A: 主鍵是用於標識當前記錄的字段。它的特點是非空,唯一。
在開發中一般情況下主鍵是不具備任何含義,只是用於標識當前記錄。
* B: 格式:
1.在創建表時創建主鍵,在字段後面加上 primary key.
create table tablename(
id int primary key,
.......
)
2. 在創建表時創建主鍵,在表創建的最後來指定主鍵
create table tablename(
id int,
.......,
primary key(id)
)
3.刪除主鍵:alter table 表名 drop primary key;
alter table sort drop primary key;
4.主鍵自動增長:一般主鍵是自增長的字段,不需要指定。
實現添加自增長語句,主鍵字段後加auto_increment(只適用MySQL)
###18常見表的操作
* A: 查看數據庫中的所有表:
格式:show tables;
查看表結構:
格式:desc 表名;
例如:desc sort;
* B: 格式:drop table 表名;
例如:drop table sort;
刪除表
###19修改表結構
* A: 修改表添加列
alter table 表名 add 列名 類型(長度) 約束;
例如:
#1,為分類表添加一個新的字段為 分類描述 varchar(20)
ALTER TABLE sort ADD sdesc VARCHAR(20);
* B: 修改表修改列的類型長度及約束
alter table 表名 modify 列名 類型(長度) 約束;
例如:
#2, 為分類表的分類名稱字段進行修改,類型varchar(50) 添加約束 not null
ALTER TABLE sort MODIFY sname VARCHAR(50) NOT NULL;
* C: 修改表修改列名
alter table 表名 change 舊列名 新列名 類型(長度) 約束;
例如:
#3, 為分類表的分類名稱字段進行更換 更換為 snamesname varchar(30)
ALTER TABLE sort CHANGE sname snamename VARCHAR(30);
* D: 修改表刪除列
alter table 表名 drop 列名;
例如:
#4, 刪除分類表中snamename這列
ALTER TABLE sort DROP snamename;
* E: 修改表名
rename table 表名 to 新表名;
例如:
#5, 為分類表sort 改名成 category
RENAME TABLE sort TO category;
* F: 修改表的字符集
salter table 表名 character set 字符集;
例如:
#6, 為分類表 category 的編碼表進行修改,修改成 gbk
ALTER TABLE category CHARACTER SET gbk;
--------------------------------
PM:
--------------------------------
###20數據表添加數據_1
* A: 語法:
insert into 表 (列名1,列名2,列名3..) values (值1,值2,值3..); -- 向表中插入某些列
* 舉例:
INSERT INTO product (id,pname,price) VALUES (1,'筆記本',5555.99);
INSERT INTO product (id,pname,price) VALUES (2,'智能手機',9999);
* 注意:
列表,表名問題
對應問題,個數,數據類型
###21數據表添加數據_2
* A: 添加數據格式,不考慮主鍵
insert into 表名 (列名) values (值)
* 舉例:
INSERT INTO product (pname,price) VALUE('洗衣機',800);
* B: 添加數據格式,所有值全給出
格式
insert into 表名 values (值1,值2,值3..); --向表中插入所有列
INSERT INOT product VALUES (4,'微波爐',300.25)
* C: 添加數據格式,批量寫入
格式:
insert into 表名 (列名1,列名2,列名3) values (值1,值2,值3),(值1,值2,值3)
舉例:
INSERT INTO product (pname,price) VALUES
('智能機器人',25999.22),
('彩色電視',1250.36),
('沙發',58899.02)
###22更新數據
* A: 用來修改指定條件的數據,將滿足條件的記錄指定列修改為指定值
語法:
update 表名 set 字段名=值,字段名=值;
update 表名 set 字段名=值,字段名=值 where 條件;
* B: 注意:
列名的類型與修改的值要一致.
修改值得時候不能超過最大長度.
值如果是字符串或者日期需要加’’.
* C: 例如:
#1,將指定的sname字段中的值 修改成 日用品
UPDATE sort SET sname='日用品';
#2, 將sid為s002的記錄中的sname改成 日用品
UPDATE sort SET sname='日用品' WHERE sid='s002';
UPDATE product SET price=800 WHERE pid=1 OR pid=2;
======================================================================================
###23刪除數據
* A: 語法:
delete from 表名 [where 條件];
或者
truncate table 表名;
* B: 面試題:
刪除表中所有記錄使用delete from 表名; 還是用truncate table 表名;
刪除方式:delete 一條一條刪除,不清空auto_increment記錄數。
truncate 直接將表刪除,重新建表,auto_increment將置為零,從新開始。
* C: 例如:
DELETE FROM product WHERE pid=4;
#表數據清空
DELETE FROM product;
###24命令行亂碼問題
A: 問題
我們在dos命令行操作中文時,會報錯
insert into user(username,password) values(‘張三’,’123’);
ERROR 1366 (HY000): Incorrect string value: '\xD5\xC5\xC8\xFD' for column 'username' at row 1
B: 原因:因為mysql的客戶端編碼的問題我們的是utf8,而系統的cmd窗口編碼是gbk
解決方案(臨時解決方案):修改mysql客戶端編碼。
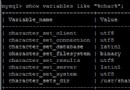
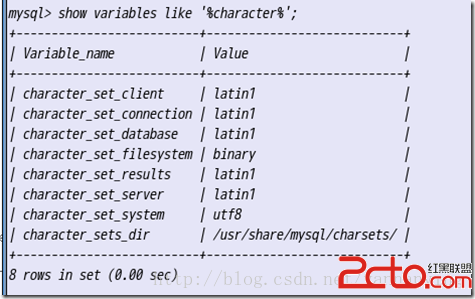
show variables like 'character%'; 查看所有mysql的編碼
client connetion result 和客戶端相關
database server system 和服務器端相關
將客戶端編碼修改為gbk.
set character_set_results=gbk;
set names gbk;
以上操作,只針對當前窗口有效果,如果關閉了服務器便失效。如果想要永久修改,通過以下方式:
在mysql安裝目錄下有my.ini文件
default-character-set=gbk 客戶端編碼設置
character-set-server=utf8 服務器端編碼設置
注意:修改完成配置文件,重啟服務
###25數據表和測試數據准備
* A: 查詢語句,在開發中使用的次數最多,此處使用“zhangwu” 賬務表。
創建賬務表:
CREATE TABLE zhangwu (
id INT PRIMARY KEY AUTO_INCREMENT, -- 賬務ID
zname VARCHAR(200), -- 賬務名稱
zmoney DOUBLE -- 金額
);
* B: 插入表記錄:
INSERT INTO zhangwu(id,zname,zmoney) VALUES (1,'吃飯支出',247);
INSERT INTO zhangwu(id,zname,zmoney) VALUES (2,'工資收入',12345);
INSERT INTO zhangwu(id,zname,zmoney) VALUES (3,'服裝支出',1000);
INSERT INTO zhangwu(id,zname,zmoney) VALUES (4,'吃飯支出',325);
INSERT INTO zhangwu(id,zname,zmoney) VALUES (5,'股票收入',8000);
INSERT INTO zhangwu(id,zname,zmoney) VALUES (6,'打麻將支出',8000);
INSERT INTO zhangwu(id,zname,zmoney) VALUES (7,null,5000);
###26數據的基本查詢
* A: 查詢指定字段信息
select 字段1,字段2,...from 表名;
例如:
select id,name from zhangwu;
* B: 查詢表中所有字段
select * from 表名;
例如:
select * from zhangwu;
注意:使用"*"在練習、學習過程中可以使用,在實際開發中,不推薦使用。
原因,要查詢的字段信息不明確,若字段數量很多,會導致查詢速度很慢。
* C: distinct用於去除重復記錄
select distinct 字段 from 表名;
例如:
select distinct money from zhangwu;
* D: 別名查詢,使用的as關鍵字,as可以省略的.
別名可以給表中的字段,表設置別名。 當查詢語句復雜時,使用別名可以極大的簡便操作。
表別名格式:
select * from 表名 as 別名;
或
select * from 表名 別名;
列別名格式:
select 字段名 as 別名 from 表名;
或
select 字段名 別名 from 表名;
例如
表別名:
select * from zhangwu as zw;
列別名:
select money as m from zhangwu;
或
select money m from zhangwu;
我們在sql語句的操作中,可以直接對列進行運算。
例如:將所有賬務的金額+10000元進行顯示.
select pname,price+10000 from product;
###27數據的條件查詢_1
* A:條件查詢
where語句表條件過濾。滿足條件操作,不滿足不操作,多用於數據的查詢與修改。
* B : 格式 :
select 字段 from 表名 where 條件;
* C: while條件的種類如下:
比較運算符
> < <= >= = <> ---------- 大於、小於、大於(小於)等於、不等於
BETWEEN ...AND... ----------- 顯示在某一區間的值(含頭含尾)
IN(set) -----------顯示在in列表中的值,例:in(100,200)
LIKE 通配符 -----------模糊查詢,Like語句中有兩個通配符:
% 用來匹配多個字符;例first_name like ‘a%’;
_ 用來匹配一個字符。例first_name like ‘a_’;
IS NULL 判斷是否為空
------------is null; 判斷為空
is not null; 判斷不為空
* D 邏輯運算符
and ------------ 多個條件同時成立
or ------------ 多個條件任一成立
not ------------ 不成立,例:where not(salary>100);
* E: 例如:
查詢所有吃飯支出記錄
SELECT * FROM zhangwu WHERE name = '吃飯支出';
查詢出金額大於1000的信息
SELECT * FROM zhangwu WHERE money >1000;
查詢出金額在2000-5000之間的賬務信息
SELECT * FROM zhangwu WHERE money >=2000 AND money <=5000;
或
SELECT * FROM zhangwu WHERE money BETWEEN 2000 AND 5000;
查詢出金額是1000或5000或3500的商品信息
SELECT * FROM zhangwu WHERE money =1000 OR money =5000 OR money =3500;
或
SELECT * FROM zhangwu WHERE money IN(1000,5000,3500);
SELECT * FROM zhangwu WHERE money NOT IN(1000,5000,3500);
###28數據的條件查詢_2
* A 模糊查詢
查詢出賬務名稱包含”支出”的賬務信息。
SELECT * FROM zhangwu WHERE name LIKE "%支出%";
* B 查詢出賬務名稱中是五個字的賬務信息
SELECT * FROM gjp_ledger WHERE ldesc LIKE "_____"; -- 五個下劃線_
* C 查詢出賬務名稱不為null賬務信息
SELECT * FROM zhangwu WHERE name IS NOT NULL;
SELECT * FROM zhangwu WHERE NOT (name IS NULL);
* D 查詢名稱為null的信息
SELECT * FROM zhangwu WHERE zname IS NULL;
======================================================================================
###29排序查詢
* A: 排序查詢
使用格式
* 通過order by語句,可以將查詢出的結果進行排序。放置在select語句的最後。
* SELECT * FROM 表名 ORDER BY 字段ASC;
* ASC 升序 (默認)
* DESC 降序
* B: 案例代碼
/*
查詢,對結果集進行排序
升序,降序,對指定列排序
order by 列名 [desc][asc]
desc 降序
asc 升序排列,可以不寫
*/
-- 查詢賬務表,價格進行升序
SELECT * FROM zhangwu ORDER BY zmoney ASC
-- 查詢賬務表,價格進行降序
SELECT * FROM zhangwu ORDER BY zmoney DESC
-- 查詢賬務表,查詢所有的支出,對金額降序排列
-- 先過濾條件 where 查詢的結果再排序
SELECT * FROM zhangwu WHERE zname LIKE'%支出%' ORDER BY zmoney DESC
###30聚合函數
* A: 聚合函數
* B: 函數介紹
* 之前我們做的查詢都是橫向查詢,它們都是根據條件一行一行的進行判斷,而使用聚合函數查詢是縱向查詢,
它是對一列的值進行計算,然後返回一個單一的值;另外聚合函數會忽略空值。
* count:統計指定列不為NULL的記錄行數;
* sum:計算指定列的數值和,如果指定列;
* max:計算指定列的最大值,如果指定列是字符串類型,那麼使用字符串類型不是數值類型,那麼計算結果為0排0序運算;
* min:計算指定列的最小值,如果指定列是字符串類型,那麼使用字符串排序運算;
* avg:計算指定列的平均值,如果指定列類型不是數值類型,那麼計算結果為0;
* C: 案例代碼
/*
使用聚合函數查詢計算
*/
-- count 求和,對表中的數據的個數求和 count(列名)
-- 查詢統計賬務表中,一共有多少條數據
SELECT COUNT(*)AS'count' FROM zhangwu
-- sum求和,對一列中數據進行求和計算 sum(列名)
-- 對賬務表查詢,對所有的金額求和計算
SELECT SUM(zmoney) FROM zhangwu
-- 求和,統計所有支出的總金額
SELECT SUM(zmoney) FROM zhangwu WHERE zname LIKE'%收入%'
INSERT INTO zhangwu (zname) VALUES ('彩票收入')
-- max 函數,對某列數據,獲取最大值
SELECT MAX(zmoney) FROM zhangwu
-- avg 函數,計算一個列所有數據的平均數
SELECT AVG(zmoney)FROM zhangwu
###31分組查詢
* A: 分組查詢
* a: 使用格式
* 分組查詢是指使用group by字句對查詢信息進行分組,例如:我們要統計出zhanguw表中所有分類賬務的總數量,這時就需要使用group by 來對zhangwu表中的賬務信息根據parent進行分組操作。
* SELECT 字段1,字段2… FROM 表名 GROUP BY 字段 HAVING 條件;
* 分組操作中的having子語句,是用於在分組後對數據進行過濾的,作用類似於where條件。
* b: having與where的區別
* having是在分組後對數據進行過濾.
* where是在分組前對數據進行過濾
* having後面可以使用分組函數(統計函數)
* where後面不可以使用分組函數。
* B: 案例代碼
/*
查詢所有的數據
吃飯支出 共計多少
工資收入 共計多少
服裝支出 共計多少
股票收入 共計多少
打麻將支出 共計多少錢
分組查詢: group by 被分組的列名
必須跟隨聚合函數
select 查詢的時候,被分組的列,要出現在select 選擇列的後面
*/
SELECT SUM(zmoney),zname FROM zhangwu GROUP BY zname
-- 對zname內容進行分組查詢求和,但是只要支出
SELECT SUM(zmoney)AS 'getsum',zname FROM zhangwu WHERE zname LIKE'%支出%'
GROUP BY zname
ORDER BY getsum DESC
-- 對zname內容進行分組查詢求和,但是只要支出, 顯示金額大於5000
-- 結果集是分組查詢後,再次進行篩選,不能使用where, 分組後再次過濾,關鍵字 having
SELECT SUM(zmoney)AS 'getsum',zname FROM zhangwu WHERE zname LIKE'%支出%'
GROUP BY zname HAVING getsum>5000