create table course(
id INT auto_increment,
title TEXT NOT NULL,
period INT,
description TEXT,
primary key(id)
) ENGINE=INNODB CHARSET=utf8;
id字段為自增長,可以不給值:
INSERT INTO course(title,period,description)
VALUES('經濟基礎學', 320, '沒啥用,愛學不學');
沒有給出具體字段,所以values裡要逐個寫,包括id:
INSERT INTO course VALUE(2, '馬克思主義哲學', 330, '這個考試能忽悠就行');
字段順序也是可以顛倒的:
INSERT INTO course(period, description, title) VALUE(340, '這個考試難啊', '高等數學');
如果沒有給某一字段設置值,而且也沒有指定默認值的話,那麼數據庫會將其值設置為null:
INSERT INTO course(title,period)
VALUE('必修課', 350);
語法:
DELETE FROM table_name WHERE 條件表達式
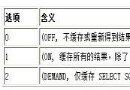
條件表達式如下表:
操作符 描述 針對表course的舉例 = 等於 title=’高等數學’ <> 不等於 period<>30 > 大於 period>300 < 小於 period<300 >= 大於等於 period>=320 <= 小於等於 period<=320 between 在兩個數之間 period between 200 and 400 like 模糊匹配 title like ‘大學’ in 是否在集合中 title in (‘經濟基礎學’, ‘馬克思主義哲學’) is null 判斷是否為空 description is null and 並,用於連接多個條件表達式 period>300 and description like ‘%必修課%’ or 或,用於連接多個條件表達式 title=’高等數學’ or title=’經濟基礎學’多條件表達式的優先級:
and運算的優先級高於or, 即先運算and再運算or。 也可以用括號來指定優先級,括號裡的表達式先運算。
刪除id為1的課程:
DELETE FROM course WHERE id=1;
刪除名字以’經濟’開頭且學時小於200的課程, 同時刪除學時大於600的課程:
DELETE FROM course WHERE title like '經濟%' and period<200 or period>600;
刪除名字以‘經濟’開頭,且學時小於200或者大於600的課程:
DELETE FROM course WHERE title like '經濟%' and (period<200 or period>600);
語法:
UPDATE table_name SET 字段名1=新值1, 字段名2=新值2 ... WHERE 條件表達式
修改所有學生的年齡為18:
注意,這個操作在實際應用中是非常危險的,所以實際中我們必須對其指定條件;
UPDATE student SET age=18;
將所有parent為null的學生年齡加1, 並將parent設置為 ‘未知’:
UPDATE student SET age=age+1 WHERE parent IS NULL;
語法:
top用於指定返回的最大行數,distinct只用於在只返回一列時指明排除重復項
SELECT [distinct|top] 字段名1, 字段名2..... FROM table_name [WHERE 條件表達式] [GROUP BY 分組列 [HAVING 分組篩選表達式] ] [ORDER BY 字段名1 [ASC|DESC],字段名2 [ASC|DESC]
查詢course表中所有記錄:
SELECT * FROM course;
查詢所有課時,並且排除重復的數字:
SELECT distinct period FROM course;
查詢課時大於200的課程,最多返回2個課程:
SELECT top 2 * FROM course WHERE period>200;
注意:top語法在postgreSQL中存在;在mysql中是沒有top語法的, MySQL中可以使用limit:
SELECT * FROM course WHERE period>200 LIMIT 1,2;
GROUP BY用於對數據進行分組以便匯總計算,HAVING是GROUP BY的可選項,用於對匯總結果進行篩選;匯總計算是指統計個數,計算平均值等,
統計所有課程的平均課時:
SELECT AVG(period) FROM course;
按課時period進行分組,統計每個課時的課程個數,並且只返回課程個數大於3的課時:
SELECT period, COUNT(*) FROM course GROUP BY period HAVING count(*) >3;
常用的聚集函數:
聚集函數 描述 COUNT(*) 統計記錄個數 AVG(column) 計算某列的平均值 MAX(column) 找出某列的最大值 MIN(column) 找出某列的最小值 VAR(column) 計算某列方差 FIRST(column) 返回某列的第1個值 LAST(column) 返回某列的最後1個值ORDER BY 用於指定返回的結果按照某個或幾個字段值大小排序, ASC升序默認, DESC降序:
SELECT * FROM course ORDER BY id desc;
先多創建幾張表:
create table student(
id INT auto_increment,
name TEXT NOT NULL,
age INT,
parent TEXT,
primary key(id)
) ENGINE=INNODB CHARSET=utf8;
create table enroll(
student_id INT,
course_id INT,
primary key(student_id, course_id),
CONSTRAINT FOREIGN KEY(student_id) REFERENCES student(id),
CONSTRAINT FOREIGN KEY(course_id) REFERENCES course(id)
);
create table teacher(
id INT auto_increment,
name TEXT NOT NULL,
gender BOOLEAN,
address TEXT,
course_id INT,
primary key(id),
CONSTRAINT FOREIGN KEY(course_id) REFERENCES course(id)
);
因為整個系統的數據是分布在不同的表中,所以很多時候為了得到完整的結果,開發者需要從兩個或多個表中查詢數據,這時需要在FROM子句中用JOIN關鍵字連接多個表,相關語法為:
SELECT 列名1, 列名2... FROM table_name1 JOIN table_name2 ON 連接條件表達式 WHERE ...
JOIN本身有多種類型,見下表:
關鍵字 含義 INNER JOIN 獲取兩個表中滿足查詢關鍵字的連接記錄 LEFT JOIN 在INNER JOIN返回記錄的基礎上, 返回 所有左表未被連接記錄到的記錄 RIGHT JOIN 在INNER JOIN返回記錄的基礎上, 返回 所有右表未被連接記錄到的記錄 FULL JOIN 返回INNER JOIN, LEFT JOIN, RIGHT JOIN結果的合集雖然一個JOIN只能連接兩個表,但可以同時使用多個JOIN以達到連接多個表的目的:
查詢所有教’高等數學’的男老師:
SELECT teacher.* FROM teacher INNER JOIN course on teacher.course_id = course.id WHERE teacher.gender = True and course.title='高等數學'
查詢所有18歲的學生選擇的課程
SELECT distinct course.title
FROM course INNER JOIN enroll ON course.id=enroll.course_id
INNER JOIN student ON enroll.student_id=student.id
WHERE student.age=18;
前面提到在update數據時,如果沒有指定where條件,那是很危險的事情,因為這它會將整個表所有記錄的值都改掉,為了防止此事件發生,我們可以在啟動mysql時使用-U參數