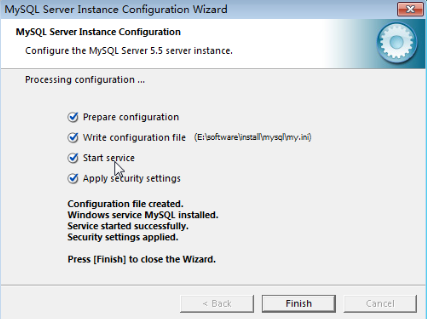
本文列舉了史上八大MySQL宕機事件原因、影響以及人們從中學到的經驗,文中用地震級數來類比宕機事件的嚴重性和後果,排在最嚴重層級前兩位的是由於亞馬遜AWS宕機故障(相當於地震十級和九級)。
一、Percona網站宕機事件
震級:3
發生時長:2011年7月11日
持續時長:數日
地點:加州Pleasanton(幸福屯)
宕機原因:Percona網站主服務器上的3塊硬盤損壞,同時因為人員變更,導致未能如預期地恢復,多個網站資產因此下線數小時到數天不等,影響其軟件下載及交易。
經驗:備份不一定永遠正常,不應該對其抱有過多期待。
二、GitHub服務中斷
震級:4
發生時間:2012年9月10-11日
持續時長:1:46小時
地點:加州聖弗朗西斯科
宕機原因:GitHub將一對古老的、基於DRBD的MySQL服務器替換成一個擁有3個節點的集群。在合並到新系統時,“活動的”數據庫自動出現了多個故障轉移(failover),同時又因為集群管理軟件的錯誤操作導致性能下降,最終造成網站宕機。
經驗:GitHub修改了Pacemaker配置來保證故障轉移僅僅可以被運維人員控制。
三、Journal Space所有數據丟失及網站關閉
震級:5
發生時間:2009年1月5日
持續時長:無限期
宕機原因:Journal Space是一個擁有6年歷史的博客平台,基於MySQL開發,其唯一的數據庫備份機器由RAID系統維護。最終網站的數據因前員工的報復行為被重寫,最終導致所有用戶數據丟失以及網站關閉。
經驗:永遠不要把驅動器鏡像當做備份——它能防范物理故障帶來的問題,但是不提供時間點恢復功能。
四、PHPFog共享數據庫運行中斷
震級:6
發生時間:2012年10月8日
持續時長:8小時
地點:俄勒岡州波特蘭
宕機原因:PHPFog將用戶數據合並到一個新的共享數據庫服務上,但是在合並過程中遭受過多的堆疊連接,最終共享數據庫停止響應,因此在共享數據庫從快照中恢復前一直處於服務不穩定狀態。從問題發生到解決一共歷時8小時。
經驗:這一事件後,PHPFog加速Amazon RDS用戶遷移活動。
五、Couch Surfing因MySQL數據庫故障導致服務關閉
震級:7
發生時間:2006年6月
地點:加州聖弗朗西斯科
持續時長:1個月
宕機原因:流行社交網站Couch Surfing曾擁有90000名用戶,在2006年遭遇了一場嚴重的硬盤問題,在試圖恢復數據時發現數據庫增值備份遭遇問題。其MySQL數據庫以及應用關鍵部分丟失,因此創始人最終關閉了這項服務,隨後用戶社區又將它重啟。
經驗:任何MySQL系統必須有一個以上備份服務器;每天都必須驗證MySQL備份進程。
六、magnolia因丟失主數據庫和備份導致最終無法完全恢復
震級:7
發生時間:2009年1月30日
地點:加州聖弗朗西斯科
持續時長:無限期
宕機原因:Magnolia和Delicious一樣,是一個流行的書簽服務,基於MySQL數據庫。該服務在由於硬盤損壞以及備份系統的錯誤,丟失了主數據庫和備份,最終無法完全恢復。
經驗:確保硬件的可靠性非常重要;備份系統是否可行必須得到充分的驗證。
七、Amazon RDS宕機事件
震級:9
發生時間:2012年6月29日
持續時長:3小時
地點:弗吉尼亞州北部
用戶影響:亞馬遜EC2雲計算服務以及包括Netflix公司、Heroku、Pinterest、 Quora、HootSuite和Instagram等。
宕機原因:一個被稱為derecho的強雷暴天氣系統通過弗吉尼亞州北部,使得亞馬遜在該地區的設施失去了動力,發電機不能正常運行,消耗應急電源的不間斷電源(電源)系統,從而導致運行在Amazon RDS上的大概上千個MySQL數據庫宕機。
經驗:擴大7*24小時工程師支持團隊規模,發生電源系統故障、UPS啟動之前完全支持手動操作開啟發電機開關。
八、Amazon RDS宕機事件
震級:10
發生時間:2011年4月21日
持續時長:48小時
地點:弗吉尼亞州北部
用戶影響:導致使用AWS平台的Reddit、Foursquare、Hootsuite、Quora以及其他多家社交網絡服務商成為“受害者” 。
宕機原因:亞馬遜修改網絡設置,同時在對主網絡升級擴容過程中,工程師不慎將主網數據全部切換到從網,由於從網帶寬較小,而它的設計目的並非用於主網容災或備份,因此導致網絡堵塞,所有EBS(Elastic Block Store)節點通信全部中斷,導致存儲著數據和日志的MySQL數據庫宕機,其中運行在一個可用區域裡41%的MySQL數據庫宕機24小時,14.6%宕機48小時。