MySQL 執行計劃
在SQL優化時,查看執行計劃,是一個有效的途徑。
EXPLAIN SELECT …… 變體: 1. EXPLAIN EXTENDED SELECT …… 將執行計劃“反編譯”成SELECT語句,運行SHOW WARNINGS 可得到被MySQL優化器優化後的查詢語句 2. EXPLAIN PARTITIONS SELECT …… 用於分區表的EXPLAIN
在mysql中,一個執行通常包括面的列:

下面的列說明中,會使用這個例子進行說明。
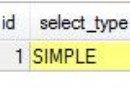
通過Id,可以看到sql的執行順序。
默認情況下,一個簡單的select的id是1。如果包括子查詢,id會遞增。
也就是說,執行順序是id 大的優先。如果id相同,則是從上到下。
例如上面的例子中, id列從上到下看,分別是1,1,3,3。那麼兩個id=3的sql子查詢會優先執行。Id=3的sql執行完畢後,才執行上面兩個id=1的。在執行id=3時,先執行上面那個,再執行下面那個。Id=1時,同理。
這個值代表了,該行對於的SQL,是簡單的SQL查詢還是復雜的SQL查詢。
這個可以取值有:simple,subquery,derived,union,union result。其中後面的4項都認為是復雜的查詢。
·simple
如果select中不包括任何的子查詢(from子句,where子句中的都不包括),union等。如果有子查詢,從外面看,第一個select不會被標記有simple了,而是被標記為primary了。
·subquery
如果子查詢不在from子句中,用這個表示。
·derived
(派生的)在from子句中的子查詢中的select,mysql會遞歸執行並將結果放到一個臨時表中。在服務器內部,稱之為派生表。
·union
如果一個sql中包括union,則第一個select稱為primary,在union中的第二個和隨後的都會被稱為union。
例如:select id from a union select id from b。union左邊的select是primary,右面的是union。
·union result
如果union後面的是一個匿名的臨時表時。則union後面的用union result來表示。
這個值用於表明這一行的sql執行時根據哪個表進行的查詢操作。
如上面例子中,
第一個id=3的查詢是從表t_m_agent中查詢的。
第二個id=3的查詢是從表t_m_metric中查詢的。
第一個id=1的查詢是從表t_m_agent中查詢的。
第二個id=1的查詢是從表之前的兩個id=3的結果(一個臨時表,在from中,所以也是派生表)中查詢的。
並且這個列表中,有兩個primary,說明是進行了join查詢(可能是外連接)。
2.4 partition 分區表
從table列,可以看出是從哪個表進行查詢。那麼是如何從table中進行查詢?
·ALL
代表了全表掃描。通常情況下,這個是最差勁的查詢方式了。
·index
它也是全表掃描,它是按照index的順序對表進行全掃描。與ALL的區別是少了一個排序的過程。如果index是散亂分布(例如使用hash)的話,開銷會非常大。
它與extra列中的using index,不是一個意思,這是要注意的一點。
·range
范圍掃描。只掃描部分index。所以要比全索引掃描好一些了。譬如between, > <等。
·ref
這是一種參照index訪問,它返回匹配某個值的所有行。常見的有下列情況 :
1)針對非唯一索引查找時:譬如一個表中,index是(a,b,c)。在where子句中只根據某個索引列查詢。例如使用了where a= ‘xx’。
2)對唯一索引進行前綴查找時:譬如一個表有index 是(a),只包括列a。在where子句中使用前綴查詢,例如 where a like ‘hello%’。
·eq_ref
使用這種索引查找,mysql知道最多只返回一條符合條件的記錄。這種方式可以在mysql中使用主鍵或者唯一索引查找時看到。
·const, system
當MySQL能夠對查詢的某部分進行優化並將其轉換成一個常量時。
·NULL
這種表示MySQL執行時,會分解查詢語句,或者根本不需要訪問表。
可能會用到哪些index。
值包括索引、主鍵。
實際用到了哪個索引。這個值不一定會在possible_keys中出現。
值包括索引、主鍵。
該列顯示了mysql在索引裡使用的字節數。
在type 為ref時,使用索引掃描或者查找時,到底使用了哪個索引。
有多少行是匹配的。
額外信息。
常見的重要的信息有:
·Using index
它表示使用了覆蓋索引,不用去掃描真實表。不要與type=index搞混了。Type=index表示根據index中的順序去對真實表進行全表掃描。
·Using where
表示 mysql將在檢索行後,再進行行的過濾。並非所有的有where子句的查詢都有這個。
·Using tempoary
表示MySQL對查詢結果排序時,會使用一個臨時表。
·Using filesort
表示MySQL在進行排序時,無法使用索引來排序,而是使用文件排序。
所以上面的例子中執行順序是 :
1)第一個id=3時,從t_m_agent 表使用全表掃描的方式查詢,排序時使用了file sort,查到了24行。
2)第二個id=3時,從t_a_metric 表采用ref 參照索引 t_m_agent.id方式查找,查到了3841行。
3)第一個id=1時,從t_m_agent 表根據index順序進行並使用了覆蓋index查找方式。
4)第二個id=1時,從兩個id=3產生的派生表參照了t_m_agent.id,const進行查找。
上面例子中的查詢,在表中有520+ 萬條數據情況下,查詢用了190s。所以需要進行優化。
進行優化後的查詢,用了0.82 s,查詢計劃是: