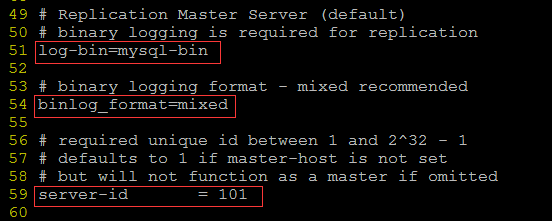
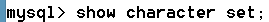文件系統
1.1.2.1層次模型
這是一種導航結構,導航結構的優點:分類管理;導航結構的缺點:如果保存不是同一類的數據,效率很低。
層次結構最大問題是失去了數據的完整性
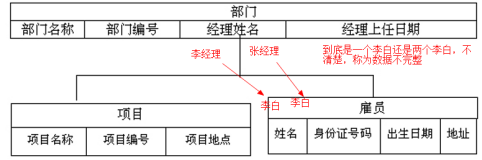
1.1.2.2網狀模型
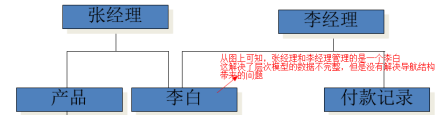
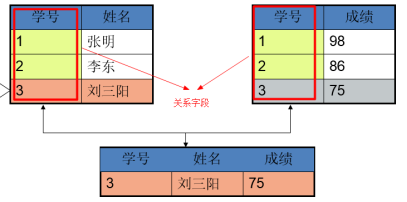
每一個存放數據的表都是獨立的,通過公共字段建立關系。
1、 優點:
a) 每個都獨立了,查詢的時候效率高
b) 對數據的約束功能強大
2、 缺點:多表查詢效率低。
多學一招:非關系型數據庫(NoSQL),這種數據庫是一種鍵值對形式的數據庫,查詢效率高,但對數據約束功能很低。(redis、mongodb)。非關系型數據庫是對關系型數據庫的一種補充。
數據庫的本質就是文件
數據庫系統(DBS)=數據庫(DB)+數據庫管理系統(DBMS)
也就是說:數據庫系統包括數據庫文件和操作數據庫文件的軟件。
SQL是Structured Query Language(結構化查詢語言)縮寫,用來操作關系型數據庫的語言。
SQL語句是一個標准SQL,可以用來操作所有的關系型數據庫。
每個公司為了更多的占有市場份額,在原來的標准SQL基礎上擴展自己獨有的東西用來吸引消費者。
數據庫
使用語言
開發公司
access
SQL
微軟
SQL Server
T-SQL
微軟
MySQL
MySQL
Oracle公司收購
Oracle
PL/SQL
甲骨文公司
問題:已知MySQL和Oracle都支持標准SQL(SQL-92),請問在MySQL上編寫的MySQL語句能否運行在Oracle上?
答:不能,因為MySQL是MySQL擴展的東西。不能運行在Oracle上。他們只能相互運行標准SQL。

多學一招:通過命令打開服務面板
打開運行面板(win+R),在面板中輸入services.msc
啟動服務:net start +服務名
關閉服務:net stop +服務名

多學一招:net start 顯示當前所有的服務列表。
安裝MySQL後,會自帶一個MySQL 5.5 Command Line Client命令行客戶端。

雙擊打開,輸入密碼,就連接上服務器了。
缺點:此客戶端只能連接本地的MySQL服務器。
1、 MySQL-Front
2、 Navicat
phpMyAdmin
運行——cmd
host主機-h
username用戶名-u
password密碼-p
port端口-P

注意:如果配置了MySQL的環境變量,執行mysql命令就不需要進入mysql.exe的目錄。
127.0.0.1表示本地地址,等價於localhost
多學一招:如果連接的是本地的MySQL服務器,-h可以省略;如果使用的是3306端口,-P也可以省略

可以通過密文來登錄

1、 exit
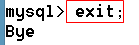
2、 quit
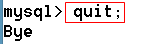
3、 \q
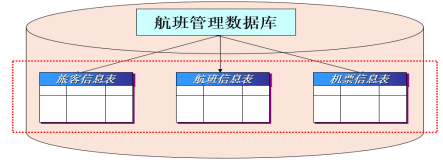
1、 數據庫和表
數據庫用來存放表,表裡面存放數據,一個數據庫可以存放多個表,一個表中存放多個數據
2、 關系:兩個表的公共字段稱為關系
3、 行:也稱為記錄,也稱為實體
4、 列:也稱為字段,也稱為屬性
在結構上稱為行和列
在數據上稱為記錄和字段
5、 數據冗余:相同的數據存儲在不同地方

腳下留心:冗余只能減少,不能杜絕。減少冗余後,表的數量就增加了。
6、 數據完整性=正確性+准確性
正確性:數據類型正確
准確性:數據的范圍准確
思考:學生年齡是int型,輸入10000歲,正確性和准確性如何?
答:正確的,但是不准確
1、語法:create database if not exists`數據庫名` charset=字符編碼

2、如果創建的數據庫已經存在,則會報錯

解決:創建時候判斷一下,數據庫是否存在,如果不存在就創建

3、如果數據庫名是關鍵字或特殊字符會報錯
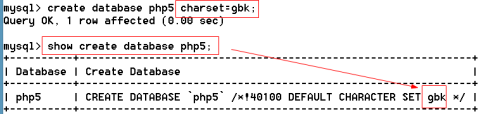
解決:是數據庫名上加上反引號



為了保證創建數據庫成功,可以在所有的數據庫名上加上反引號
4、可以給創建的數據庫指定字符編碼
1、 此目錄在安裝mysql服務器的時候選擇路徑
2、 可以在my.ini中查看並更改

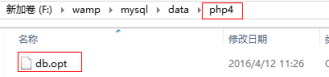
3、 創建一個數據庫就在data文件夾下創建一個與數據庫同名的文件夾,並在此文件夾下多了一個db.opt文件。db.opt文件是設置數據庫的字符集和校對集。

語法:show databases;

information_schema:存儲了mysql服務器的管理數據庫的信息。比如:數據庫名、表名、字段名、字段的數據類型、訪問權限
performance_schema:MySQL5.5新增的一個數據庫,主要用來收集數據庫服務器性能參數。
mysql:mysql系統數據庫,保存比如用戶名、密碼
test:給用戶學習測試用的數據庫
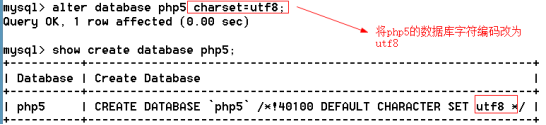
語法:show create database `數據名`

只能修改數據庫字符編碼
語法:alter database `數據庫名` charset=字符編碼
1、語法:drop database [if exists] `數據庫名`

2、如果刪除的數據庫不存在會報錯

解決:刪除之前判斷一下,存在就刪除

語法:use `數據名`
語法:
create table [if not exists] `表名`(
字段名 數據類型 [null|not null] [default] [auto_increment] [primary key] [comment],
……
)[engine=存儲引擎] [charset=字符編碼]
null|not null:是否為空
Default: 默認值
Auto_increment: 自動增長
Primary key: 主鍵
Comment: 備注
Engine:存儲引擎,不同存儲引擎表示不同的數據存儲方式
Charset:設置表的字符編碼
1、創建最簡單的表

2、創建復雜的表
一個數據庫對應一個文件夾,一個表對應一個或多個文件。
1、引擎是myisam,一個表對應三個文件


2、引擎是innodb,一個表對應是一個文件

所有的innodb的數據放在一個統一的文件中管理,路徑在data文件夾下ibdata1文件。如果數據量很多,mysql會自動的生成ibdata2,ibdata3,…文件
多學一招:myisam引擎的表相互之間獨立, Myisam的表可以隨意的拷貝粘貼。innodb引擎的表相互之間不獨立,
1、 Myisam
a) 讀取速度快
b) 對數據的約束能力低(不支持觸發器,存儲過程等等)
c) 容易產生大量碎片
2、 Innodb
a) 讀取速度沒有myisam快
b) 對數據的約束能力強(支持觸發器,存儲過程等等)
c) 不產生碎片

語法:show tables;
語法:show create table 表名[\G]
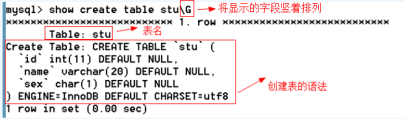
\G的作用:
\G是將顯示的字段豎著排列
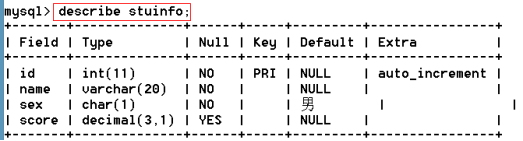
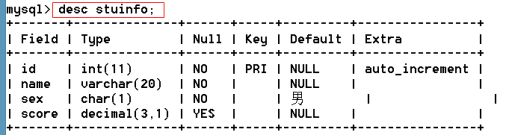
語法:describe[desc] 表名
基於現在的表創建一個新表
語法一:create table 新表 select 字段1,字段2 from 舊表

腳下留心:這種方式創建表不能從父表中復制主鍵,自動增長;但是父表中的數據被復制過來。
語法二:create table 新表 like 舊表

腳下留心:like的方法只能復制表結構,不能復制表數據。
語法:alter table 表名,可以對表添加字段,刪除字段等等操作
1、 添加字段 add [column]
1、在最後一列後面添加字段

2、將字段添加到第一列

3、將添加的字段放在指定字段之後

2、 刪除字段

不能清空所有的字段。
3、 修改字段 modify change
a) 只改字段屬性,不改字段段名(modify)
將name的屬性改為varchar(30),並將位置移動到第一列

能修改字段的所有屬性,除了字段名和默認值,備注,可以添加任意屬性,
b) 改屬性並改字段名
將name改名為myname varchar(10)並將位置放在id的後面


能修改字段的所有屬性,可以添加任意屬性,除了默認值,如果想設置
4、 修改引擎

5、 修改表名 rename to

6、將stu1表移動到data數據庫下並改名為stu.

語法:drop table [if exists] 表1,表2.表3,…
刪除多個表

刪除之前可以判斷表是否存在

可以一次判斷多個表是否存在

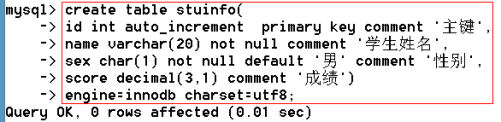
新建測試表
create table stuinfo(
id int auto_increment primary key comment '主鍵',
name varchar(20) not null comment '姓名',
sex char(1) not null default '男' comment '性別',
score int comment '成績'
)engine=innodb charset=utf8;
語法:insert into 表名 (字段名) values (值)
總結:
1、 值的個數、順序和插入字段的個數、順序必須一致。

2、 自動增長列可以手動輸入數字,也可以通過null讓MySQL自動增長

3、 插入字段和表字段順序可以不一致,但是插入的值必須和插入字段的順序一致。

4、 如果插入值的順序、個數和表字段的順序個數一致的話,插入字段可以省略

5、 插入默認值
a) 如果一個字段有默認值,此字段上沒有值的插入就會自動的插入默認值
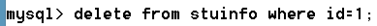
b) 通過default關鍵字插入默認值

6、 一次插入多條數據

7、 使用insert…set插入數據

語法:update 表名 set 字段名=值 [where 條件] [order by 排序] [limit 限制]
將rose的性別改成“女”,成績改成66
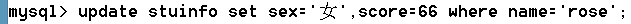
將班級的前3名同學性別改成男
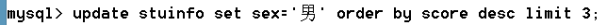
語法:delete from 表 [where條件] [order by 排序 asc|desc] [limit 數量]
--刪除學號是1的學生
--刪除第一名
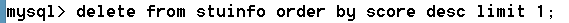
--刪除成績在80分以下的

--清空表
多學一招:清空表的方法有兩個,第一個是delete from 表名,還有一個是truncate table 表名。delete from 表名執行過程是將數據一條一條的依次刪除。truncate table執行過程是將整個表刪除同時創建一個相同的表,很顯然這種方式清空表的效率高。

Select * from 表名 刪除表的時候自增長的屬性還在,在重新加入的時候會延續自增長的鍵值。
字符集:可見字符在保存和傳輸時對應的二進制編碼集合。由概念可知,字符
集在兩個地方使用
1、 數據存儲的時候
2、 數據傳輸的時候
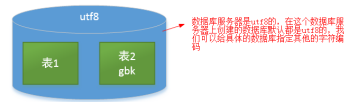
MySQL可以在服務器、數據庫、表、字段上設置字符編碼
注意:字符編碼在數據庫上設置就可以了。
場景:
1、 創建表的時候只用中文就報錯
2、 在插入數據中出現中文報錯

分析
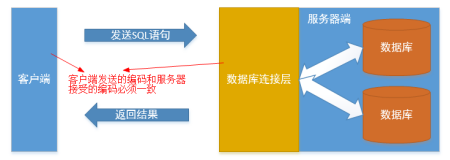
客戶端發送的編碼有客戶端決定的。我們現在用的客戶端是windows的命令行,查看命令行的編碼:客戶端右鍵——屬性——
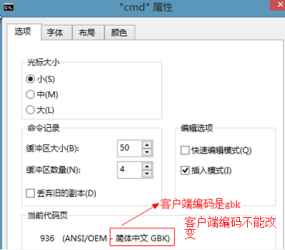
查看服務編碼
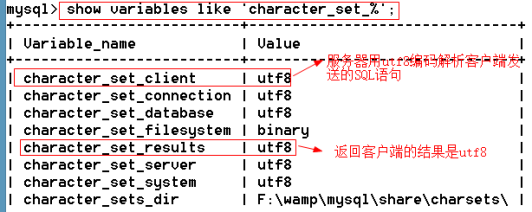
解決:告訴服務器通過gbk編碼解析發送SQL語句。語法:set 變量名=值

現在插入成功!
場景:查看插入的數據
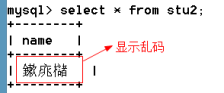
原因:返回的編碼是utf8,客戶端用gbk去解析的。
解決:將返回的結果編碼設置為gbk;

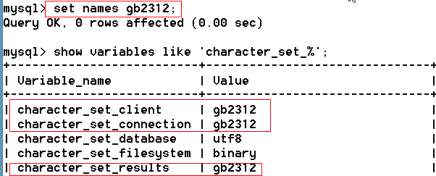
再次查詢,成功
注意:我們一般只執行set names ‘字符編碼’,因為這個SQL語句可以一次更改3個變量。
在某種字符集下,字符和字符的比較關系。比如a和B的大小關系,如果區分大小寫a>B,如果不區分大小寫a<B。這種比較的關系是有校對集決定的。
校對集依賴於字符集,不同的字符集他們的比較規則也不一樣,如果字符集發生更改,校對集也要重新定義。
不同的校對集對同一組字符比較結果不一致的。
語法:collate=校對集
定義兩個表,校對集不一樣
create table t1(
name char(1)
)charset=utf8 collate=utf8_general_ci;
create table t2(
name char(1)
)charset=utf8 collate=utf8_bin;
插入測試數據
insert into t1 values ('a'),('B');
insert into t2 values ('a'),('B');
通過排序查看結果


校對集名字規則
_bin:表示按二進制編碼進行比較
_ci:不區分大小寫
_cs:區分大小寫
中文排序規則:按照漢字的拼音來排序