1. 【事件起因】
今天在做項目的時候,發現提供給客戶端的接口時間很慢,達到了2秒多,我第一時間,抓了接口,看了運行的sql,發現就是 2個sql慢,分別占了1秒多。
一個sql是 鏈接了5個表同時使用了 2個 order by和 1個limit的分頁 sql。
一個sql是上一個sql的count(*),即鏈接了5個表,當然沒有limit了(取總數)。
2. 【著手優化】
1)【優化思路】
第一條是 做client調用 service層的數據緩存
第二條就是 優化sql本身。
這裡著重講一下 優化sql本身
2)【使用expain】
使用 explain語句,查看該語句,
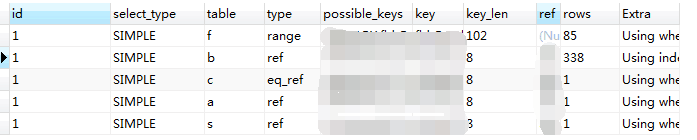 看著沒有啥毛病啊,使用到了索引,掃描的行數也多,一個 85行,一個338多行,其他的也都是 1行。
3)【使用子查詢優化】
使用子查詢進行優化,效果差不多,只能想別的辦法
4)【去掉order by排序】
和同事討論時,覺得原來的5張表該加的索引都加了,為什麼速度慢呢,我說裡面還做了排序處理。
說者無心,聽者有意。他說 你去掉排序試試,果然,去掉排序後,時間降到了 0.002秒,快了很多。
但是order by排序為什麼很慢呢,因為 order by的那個字段也是 有索引的。
5)【創建聯合索引】
後來查詢了下面這篇文章(mysql中提高Order by語句查詢效率的兩個思路分析)才知道, 如果查詢出來的數據量很大的時候,order by字段,必須和前面的where語句中的字段建立 聯合索引才行,同事建立的索引順序還得是 先是 where語句中的字段最後是 order by中的字段。
6)【最終方案】
明白了道理,但是鑒於還得麻煩 DBA創建索引為 特定項目建立特定的索引也不劃算。這部分數據一遍不經常變動,可以做成緩存的形式,就作罷了,但是 分析問題的思路和優化 sql order的過程還是有收獲的
3. 【參考資料】
看著沒有啥毛病啊,使用到了索引,掃描的行數也多,一個 85行,一個338多行,其他的也都是 1行。
3)【使用子查詢優化】
使用子查詢進行優化,效果差不多,只能想別的辦法
4)【去掉order by排序】
和同事討論時,覺得原來的5張表該加的索引都加了,為什麼速度慢呢,我說裡面還做了排序處理。
說者無心,聽者有意。他說 你去掉排序試試,果然,去掉排序後,時間降到了 0.002秒,快了很多。
但是order by排序為什麼很慢呢,因為 order by的那個字段也是 有索引的。
5)【創建聯合索引】
後來查詢了下面這篇文章(mysql中提高Order by語句查詢效率的兩個思路分析)才知道, 如果查詢出來的數據量很大的時候,order by字段,必須和前面的where語句中的字段建立 聯合索引才行,同事建立的索引順序還得是 先是 where語句中的字段最後是 order by中的字段。
6)【最終方案】
明白了道理,但是鑒於還得麻煩 DBA創建索引為 特定項目建立特定的索引也不劃算。這部分數據一遍不經常變動,可以做成緩存的形式,就作罷了,但是 分析問題的思路和優化 sql order的過程還是有收獲的
3. 【參考資料】1)mysql中提高Order by語句查詢效率的兩個思路分析
2)【夯實Mysql基礎】mysql中提高Order by語句查詢效率的兩個思路分析