我們經常會對數據表進行插入、刪除、更新及查找的工作,即我們常說的CURD。其實,當我們輸入命令時,mysql引擎會按照下圖進行操作
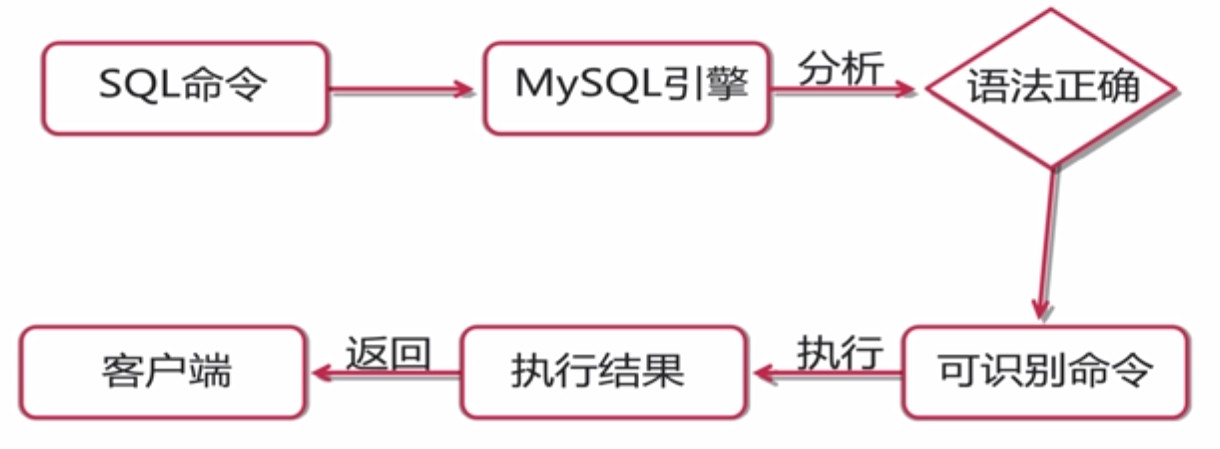
如果我們省略了分析和編譯的環節,那麼執行效率將大大提高。這就需要下面介紹的存儲來實現
存儲過程是SQL語句和控制語句的預編譯集合,以一個名稱存儲並作為一個單元處理。存儲過程存儲在數據庫內,可以由應用程序調用執行,允許用戶聲明明變量以及進行流程控制。存儲過程可以接收參數(輸入類型參數、輸出類型參數),可以存在多個返回值。所以,存儲過程的執行效率高於單一SQL命令的執行效率
優點
1、增強SQL語句的功能和靈活性
2、實現較快的執行速度。客戶端第一次調用存儲過程時,MySQL引擎會對其進行語法分析、編譯等操作,然後將編譯結果存儲到內存中,所以第一次和之前的效率一樣,然而以後會直接調用內存中的編譯結果,效率提高
3、減少網絡流量。單條SQL語句字符量較大,而通過調用存儲過程則只需要傳存儲過程的名稱及相關參數即可,提交給服務器的數據量相對較少
語法結構
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name([proc_parameter[,...]])
[characteristic ...] routine_body
proc_parameter: [ IN | OUT | INOUT ] param_name type
IN表示該參數的值必須在調用存儲過程時指定,不能返回
OUT表示該參數的值可以被存儲過程改變,並且可以返回
INOUT表示該參數在調用時指定,並且可以被改變和返回
characteristic(特性)
COMMENT 'string'
|{CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY {DEFINER | INVOKER}
COMMENT:注釋
CONTAINS SQL:包含SQL語句,但不包含讀或寫數據的語句
NO SQL:不包含SQL語句
READS SQL DATA:包含讀數據的語句
MODIFIES SQL DATA:包含寫數據的語句
SQL SECURITY {DEFINER | INVOKER}:指明誰有權限來執行
過程體
1.過程體由合法的SQL語句構成;
2.過程體可以是“任意”SQL語句(這裡的任意主要是指對記錄的增刪改查,多表連接);
3.過程體如果為復合結構,則使用BEGIN...END語句;
4.復合結構可以包含聲明,循環,控制結構
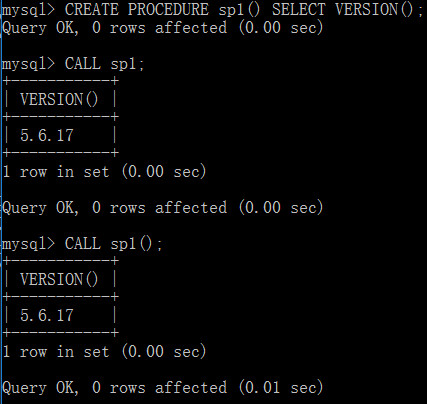
創建沒有參數的存儲過程
CREATE PROCEDURE sp1() SELECT VERSION();
調用存儲過程
方式一:CALL sp_name([parameter[,...]]) 如果存儲過程包含參數,則必須有小括號
方式二:CALL sp_name[()] 如果存儲過程不包含參數,則小括號可有可無
修改存儲過程
ALTER PROCEDURE sp_name [characteristic ...]
COMMENT 'string'
|{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
只能修改存儲過程中的注釋、當前內容的類型,並不能修改過程體。要修改過程體的話,需要先刪除存儲過程,然後重建
刪除存儲過程
DROP PROCEDURE [IF EXISTS] sp_name
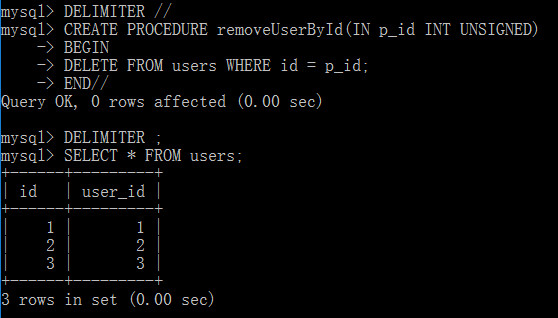
創建帶有IN類型的存儲過程
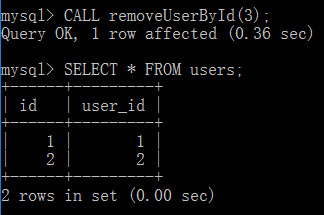
DELIMITER // CREATE PROCEDURE removeUserById(IN p_id INT UNSIGNED) BEGIN DELETE FROM users WHERE id = p_id; END// DELIMITER;
下面來調用存儲過程
創建帶有IN和OUT類型參數的存儲過程
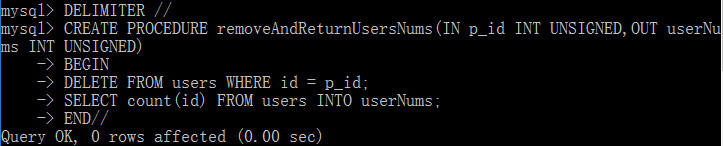
DELIMITER // CREATE PROCEDURE removeAndReturnUsersNums(IN p_id INT UNSIGNED,OUT userNums INT UNSIGNED) BEGIN DELETE FROM users WHERE id = p_id; SELECT count(id) FROM users INTO userNums; END // DELIMITER ;
mysql變量分類
1.用戶變量:以"@"開始,形式為"@變量名"
用戶變量跟mysql客戶端是綁定的,設置的變量,只對當前用戶使用的客戶端生效
SET @i = 7;
2.全局變量:定義時,以如下兩種形式出現,set GLOBAL 變量名或者set @@global.變量名
對所有客戶端生效。只有具有super權限才可以設置全局變量
3.會話變量:只對連接的客戶端有效
4.局部變量:作用范圍在begin到end語句塊之間。在該語句塊裡設置的變量
declare語句專門用於定義局部變量。set語句是設置不同類型的變量,包括會話變量和全局變量
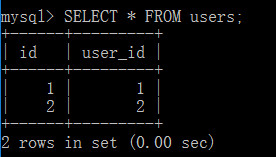
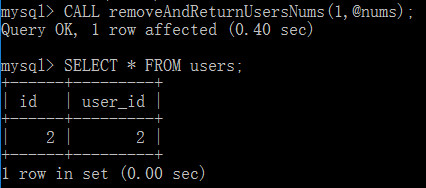
下面來調用存儲過程
CALL removeAndReturnUsersNums(1,@nums);
創建帶有多個OUT類型參數的存儲過程
DELIMITER // CREATE PROCEDURE removeUserByAgeAndReturnInfos(IN p_age SMALLINT UNSIGNED,OUT deleteUsers SMALLINT UNSIGNED, OUT userCounts SAMLLINT UNSIGNED) BEGIN DELETE FROM users WHERE age = p_age; SELECT ROW_COUNT() INTO deleteUsers; SELECT COUNT(id) FROM users INTO userCounts; END // DELIMITER ;
[注意]ROW_COUNT()函數用來得到插入、刪除以及更新的被影響的記錄總數
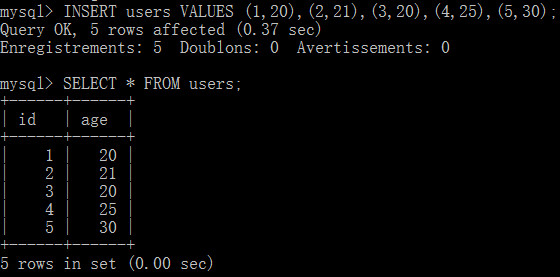
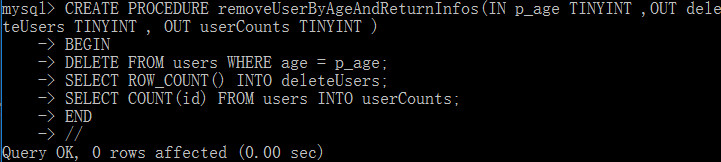
下面來調用存儲過程
CALL removeUserByAgeAndReturnInfos(20,@a,@b);
[注意]@a表示刪除的記錄數,@b表示剩余的記錄數
SELECT @a,@b;
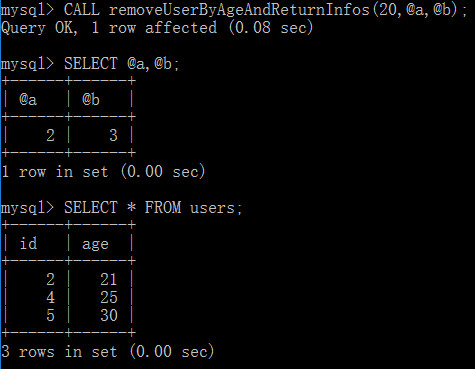
存儲過程與自定義函數的區別
1.存儲過程實現的功能要復雜一些;而函數的針對性更強
2.存儲過程可以返回多個值;函數只能有一個返回值
3.存儲過程一般獨立的來執行;而函數主要作為其他SQL語句的組成部分來出現
MySQL可以將數據以不同的技術存儲在文件(內存)中,這種技術就稱為存儲引擎。每一種存儲引擎使用不同的存儲機制、索引技巧、鎖定水平,最終提供廣泛且不同的功能
在關系型數據庫中,數據的存儲是以表的形式來實現的。所以,存儲引擎也可以稱為表類型。所以,實際上,存儲引擎就是一種存儲數據、查詢數據的技術
MySQL支持的存儲引擎包括MyISAM、InnoDB、Memory、CSV、Archive
並發控制
並發控制是指當多個連接對記錄進行修改時保證數據的一致性和完整性
例如:兩個用戶同時登錄並操作數據庫,其中一個用戶刪除某條記錄,而另一個用戶讀取該條記錄,這就需要並發控制,否則會報錯或返回無效信息
在處理並發'讀'或'寫'操作時,MySQL通過鎖系統實現並發控制,包括共享鎖和排他鎖
-共享鎖(讀鎖):在同一時間段內,多個用戶可以讀取同一個資源,讀取過程中數據不會發生任何變化
-排他鎖(寫鎖):在任何時候只能有一個用戶寫入資源,當進行寫鎖時會阻塞其他的讀鎖或者寫鎖操作
鎖顆粒(也稱為鎖力度)是指鎖定時的單位。只需要對修改的數據精確加鎖就可以,而無需對所有資源都加鎖
加鎖會增加系統開銷,所以需要通過鎖策略,在鎖開銷和系統安全之間尋找平衡。mysql鎖策略包括表鎖和行鎖兩種策略
- 表鎖,是一種開銷最小的鎖策略
- 行鎖,是一種開銷最大的鎖策略
事務處理
事務是數據庫區別於文件系統的重要特征之一,事務主要用於保證數據庫的完整性
事務特性包括:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、持久性(Durability),簡寫為ACID
索引
索引是對數據表中一列或多列的值進行排序的一種結構,使用索引可以快速訪問數據表的特定信息。索引是記錄快速定位的一種方法,類似於書的目錄
索引包括普通索引、唯一索引、全文索引、btree之索引、hash索引等
各種存儲引擎的特點
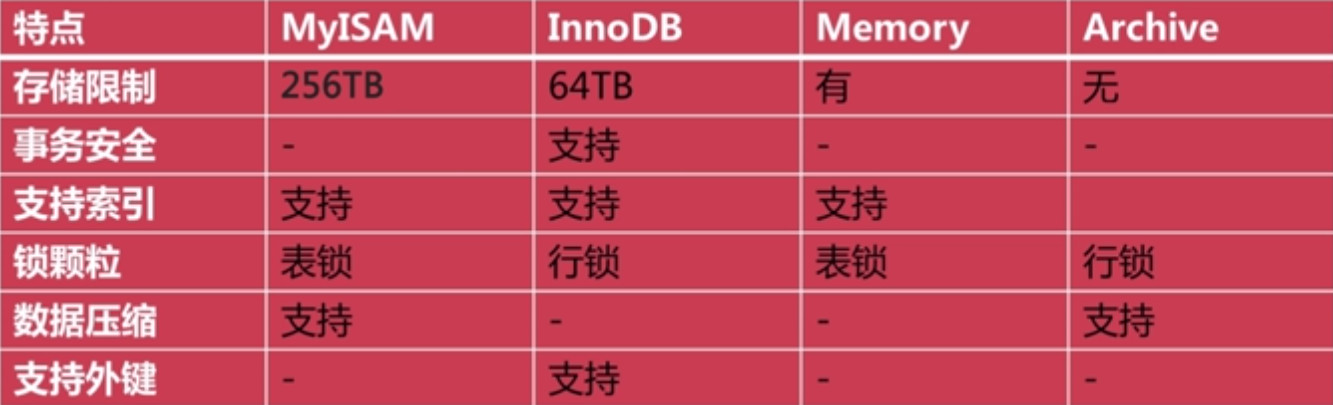
除了上面這幾種存儲引擎之外,還有下面幾種不太常見的引擎
CSV存儲引擎不支持索引,逗號分隔值(Comma-Separated Values,CSV,有時也稱為字符分隔值,因為分隔字符也可以不是逗號),其文件以純文本形式存儲表格數據(數字和文本)。純文本意味著該文件是一個字符序列,不含必須像二進制數字那樣被解讀的數據。CSV文件由任意數目的記錄組成,記錄間以某種換行符分隔
BlackHole也叫黑洞引擎,寫入的數據都會消失,一般用於做數據復制的中繼
MyISAM引擎適合於事物處理不多的情況
修改存儲引擎
1、通過修改MySQL的配置文件實現
default-storage-engine = engine
2、通過創建數據表命令實現
CREATE TABLE table_name( ... ) ENGINE = engine;
3、通過修改數據表命令實現
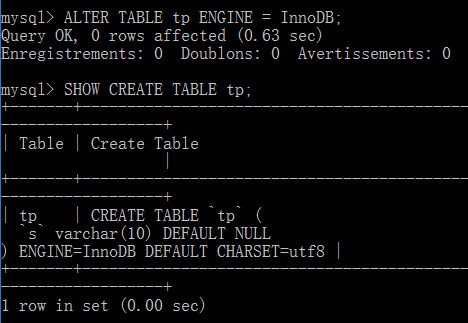
ALTER TABLE table_name ENGINE [=] engine_name;