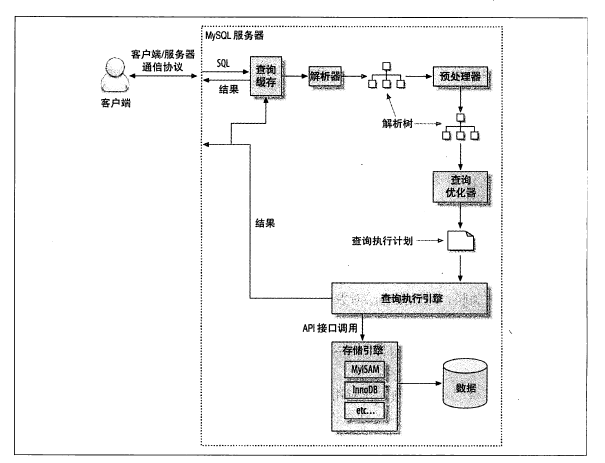
子分區其實是對每個分區表的每個分區進行再次分隔,目前只有RANGE和LIST分區的表可以再進行子分區,子分區只能是HASH或者KEY分區。子分區可以將原本的數據進行再次的分區劃分。
子分區由兩種創建方法,一種是不定義每個子分區子分區的名字和路徑由分區決定,二是定義每個子分區的分區名和各自的路徑
1.不定義每個子分區
CREATE TABLE tb_sub (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='tb_sub';

2.定義每個子分區
定義子分區可以為每個子分區定義具體的分區名和分區路徑
CREATE TABLE tb_sub_ev (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);

3.測試數據
INSERT INTO tb_sub_ev() VALUES(1,'1989-01-01'),(2,'1989-03-19'),(3,'1989-04-19');
當往裡面插入三條記錄時,其中‘1989-01-01’和‘1989-04-19’存儲在p0_s0分區中,‘1989-03-19’存儲在p0_s1當中

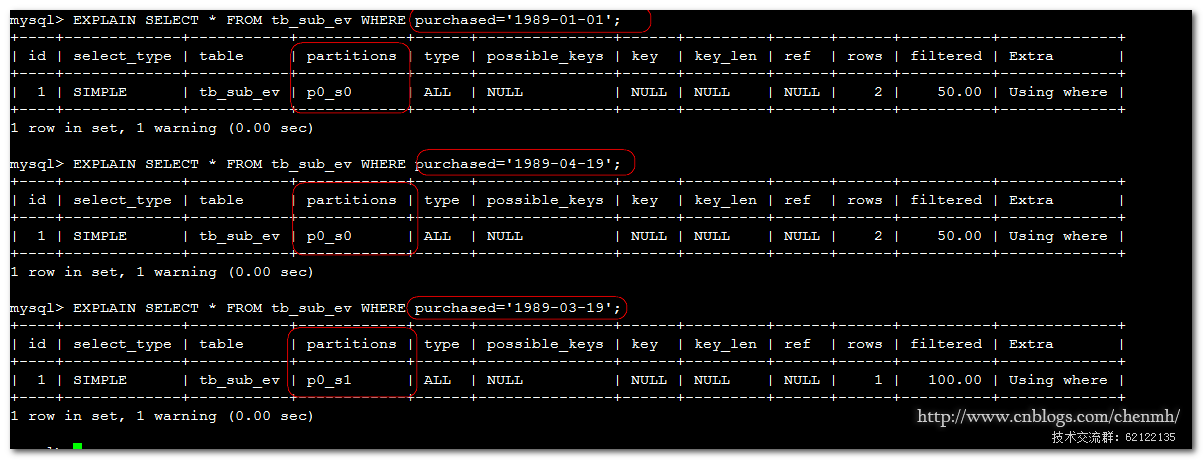
分區管理和RANGE、LIST的分區管理是一樣的
1.合並分區
將p0,p1兩個分區合並
ALTER TABLE tb_sub_ev REORGANIZE PARTITION p0,p1 INTO (
PARTITION m1 VALUES LESS THAN (2000)
( SUBPARTITION n0,
SUBPARTITION n1
)
);

注意:合並分區的子分區也必須是兩個,這點需要理解,因為必須和創建分區時每個分區只有兩個子分區保持一致,合並分區不會造成數據的丟失。
2.拆分分區
ALTER TABLE tb_sub_ev REORGANIZE PARTITION m1 INTO (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
)
);
同樣,拆分分區也必須保證每個分區是兩個子分區。
3.刪除分區
ALTER TABLE tb_sub_ev DROP PARTITION P0;
注意:由於分區是RANGE和LIST分區,所以刪除分區也是同RANGE和LIST分區一樣,這裡只能對每個分區進行刪除,不能針對每個子分區進行刪除操作,刪除分區後子分區連同數據一並被刪除。
1.要不不定義各個子分區要不就每個都需要定義
CREATE TABLE tb_sub_ev_nex (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
這裡由於分區p1沒有定義子分區,所以創建分區失敗
ALTER TABLE tablename REMOVE PARTITIONING ;
注意:使用remove移除分區是僅僅移除分區的定義,並不會刪除數據和drop PARTITION不一樣,後者會連同數據一起刪除
參考:
RANGE分區:http://www.cnblogs.com/chenmh/p/5627912.html
LIST分區:http://www.cnblogs.com/chenmh/p/5643174.html
COLUMN分區:http://www.cnblogs.com/chenmh/p/5630834.html
HASH分區:http://www.cnblogs.com/chenmh/p/5644496.html
KEY分區:http://www.cnblogs.com/chenmh/p/5647210.html
指定各分區路徑:http://www.cnblogs.com/chenmh/p/5644713.html
分區建索引:http://www.cnblogs.com/chenmh/p/5761995.html
分區介紹總結:http://www.cnblogs.com/chenmh/p/5623474.html
子分區的好處是可以對分區的數據進行再分,這樣數據就更加的分散,同時還可以對每個子分區定義各自的存儲路徑,這部分內容在指定各分區路徑的下一篇文章中單獨進行講解。
備注:
作者:pursuer.chen
博客:http://www.cnblogs.com/chenmh
本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須注明文章來源,且在文章開頭明顯處給明鏈接。
《歡迎交流討論》