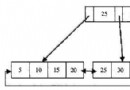
基於給定的分區個數,將數據分配到不同的分區,HASH分區只能針對整數進行HASH,對於非整形的字段只能通過表達式將其轉換成整數。表達式可以是mysql中任意有效的函數或者表達式,對於非整形的HASH往表插入數據的過程中會多一步表達式的計算操作,所以不建議使用復雜的表達式這樣會影響性能。
MYSQL支持兩種HASH分區,常規HASH(HASH)和線性HASH(LINEAR HASH) 。
一、常規HASH
常規hash是基於分區個數的取模(%)運算。根據余數插入到指定的分區
CREATE TABLE tbhash (
id INT NOT NULL,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4
;
ALTER TABLE tbhash ADD INDEX ix_store_id(store_id);
INSERT INTO tbhash() VALUES(1,100),(1,101),(2,102),(3,103),(4,104);
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='tbhash';

其中100,104對4取模是0所以這兩條數據被分配到了p0分區。

2.時間類型字段
CREATE TABLE employees (
id INT NOT NULL,
hired DATE NOT NULL DEFAULT '1970-01-01',
)
PARTITION BY HASH( YEAR(hired) )
PARTITIONS 4;
常規hash的分區非常的簡便,通過取模的方式可以讓數據非常平均的分布每一個分區,但是由於分區在創建表的時候已經固定了。如果新增或者收縮分區的數據遷移比較大。
二、線性HASH(LINEAR HASH)
LINEAR HASH和HASH的唯一區別就是PARTITION BY LINEAR HASH
CREATE TABLE tblinhash (
id INT NOT NULL,
hired DATE NOT NULL DEFAULT '1970-01-01'
)
PARTITION BY LINEAR HASH( YEAR(hired) )
PARTITIONS 6;
線性HASH的計算原理如下:
假設分區個數num=6,N表示數據最終存儲的分區
sep1:V = POWER(2, CEILING(LOG(2, num))),LOG()是計算NUM以2為底的對數,CEILING()是向上取整,POWER()是取2的次方值;如果num的值是2的倍數那麼這個表達式計算出來的結果不變。
V=POWER(2,CEILING(LOG(2,6)))
V=POWER(2,3)
V=8
sep2:N=values&(V-1);&位與運算,將兩個值都轉換成2進行求與運算,當都為1才為1;當num是2的倍數時由於V計算出來的結果不變,這時values&(V-1)=MOD(values/num)和時間HASH取模算出的結果是一致的,這時特殊情況只有當分區是2的倍數才是這種 情況。values是YEAR(hired)的值
sep3:while N>=num
sep3-1:N = N & (CEIL(V / 2) - 1)
例如:
1.當插入的值是'2003-04-14'時
V = POWER(2, CEILING( LOG(2,6) )) = 8 N = YEAR('2003-04-14') & (8 - 1)
= 2003 & 7
=3
(3 >= 6 is FALSE: record stored in partition #3),N不大於num所以存儲在第3分區,注意這裡的3指的是P3,分區號是從P0開始。
2.當插入的值是‘1998-10-19’
V = POWER(2, CEILING( LOG(2,6) )) = 8
N = YEAR('1998-10-19') & (8-1)
= 1998 & 7
= 6
(6 >= 6 is TRUE: additional step required),由於N>=num所以要進行第三步操作
N=N&(CEILING(8/2)-1)
=6&3
=2
(2>=6is FALSE:recored in partition #2),由於2不大於6所以存儲在第2個分區,注意這裡的3指的是P2,分區號是從P0開始。
INSERT INTO tblinhash() VALUES(1,'2003-04-14'),(2,'1998-10-19'); SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='tblinhash';

EXPLAIN SELECT * FROM tblinhash WHERE hired='2003-04-14';

三、分區管理
常規HASH和線性HASH的增加收縮分區的原理是一樣的。增加和收縮分區後原來的數據會根據現有的分區數量重新分布。HASH分區不能刪除分區,所以不能使用DROP PARTITION操作進行分區刪除操作;
只能通過ALTER TABLE ... COALESCE PARTITION num來合並分區,這裡的num是減去的分區數量;
可以通過ALTER TABLE ... ADD PARTITION PARTITIONS num來增加分區,這裡是null是在原先基礎上再增加的分區數量。
1.合並分區
減去3個分區
ALTER TABLE tblinhash COALESCE PARTITION 3;
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='tblinhash';

注意:減去兩個分區後,數據根據現有的分區進行了重新的分布,以'2003-04-14'為例:POWER(2, CEILING( LOG(2,3) ))=4,2003&(4-1)=3,3>=3,3&(CEILING(3/2)-1)=1,所以現在的'2003-04-14'這條記錄由原來的p3變成了p1

2.增加分區
增加4個分區
ALTER TABLE tblinhash add PARTITION partitions 4;
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='tblinhash';

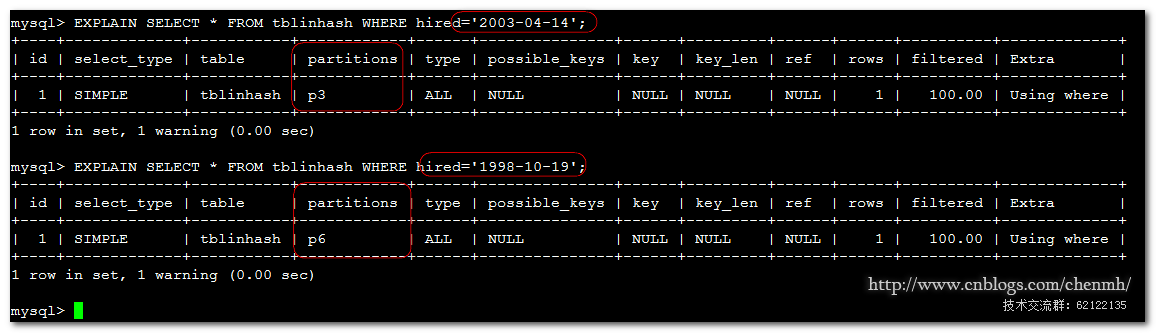
當在3個分區的基礎上增加4個分區後,‘2003-04-14’由原來的p1變成了p3,而另一條記錄由原來的p2變成了p6
四、移除表的分區
ALTER TABLE tablename REMOVE PARTITIONING ;
注意:使用remove移除分區是僅僅移除分區的定義,並不會刪除數據和drop PARTITION不一樣,後者會連同數據一起刪除
參考:
RANGE分區:http://www.cnblogs.com/chenmh/p/5627912.html
LIST分區:http://www.cnblogs.com/chenmh/p/5643174.html
COLUMN分區:http://www.cnblogs.com/chenmh/p/5630834.html
KEY分區:http://www.cnblogs.com/chenmh/p/5647210.html
子分區:http://www.cnblogs.com/chenmh/p/5649447.html
指定各分區路徑:http://www.cnblogs.com/chenmh/p/5644713.html
分區建索引:http://www.cnblogs.com/chenmh/p/5761995.html
分區介紹總結:http://www.cnblogs.com/chenmh/p/5623474.html
常規HASH的數據分布更加均勻一些,也便於理解;目前還沒有徹底理解為什麼線性HASH在收縮和增加分區時處理的速度會更快,同時線性HASH的數據分布不均勻。
備注:
作者:pursuer.chen
博客:http://www.cnblogs.com/chenmh
本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須注明文章來源,且在文章開頭明顯處給明鏈接。
《歡迎交流討論》