1.在查詢結果中不顯示重復記錄
查詢時不顯示重復記錄主要應用了 DISTINCT 關鍵字,該關鍵字用於刪除重復記錄。
在實現查詢操作時,如果查詢的選擇列表中包含一個表的主鍵,那麼每個查詢中的記錄都將是唯一的(因為主鍵在每一條記錄中有一個不同的值);如果主鍵不包含在查詢結果中,就可能出現重復記錄。使用 DISTINCT 關鍵字以後即可刪除重復記錄。
DISTINCT 的語法如下:
SELECT DISTINCT select_list;
注意:DISTINCT 關鍵字並不是指某一行,而是指不重復 SELECT 輸出的所有列。這一點十分重要,其作用是防止相同的行出現在一個查詢結果的輸出中。
例如:
select distinct name,price,date,address,quality from tb;
2.使用 NOT 查詢不滿足條件的記錄
使用 NOT 與謂詞進行組合所形成的條件進行查詢。
NOT 與謂詞進行組合所形成的表達式分別是 [NOT] BETWEEN、IS [NOT] NULL 和 [NOT] IN 。
(1)[NOT] BETWEEN
該條件指定值的包含范圍,使用 AND 將開始值和結束值分開。
其語法如下:
test_expression [NOT] BETWEEN begin_expression AND end_expression
結果類型為 boolean ,返回值為:如果 test_expression 的值小於等於 begin_expression 的值或者大於等於 end_expression 的值,則 NOT BETWEEN 返回 true。
注意:若要指定排除范圍,還可以使用大於(>)和小於(<)運算符代替 BETWEEN。
(2)IS [NOT] NULL
根據所使用的關鍵字指定對空值或非空值進行查詢,如果有任何操作數是 null, 表達式取值為 null 。
(3)[NOT] IN
根據所使用的關鍵字是包含在列表內還是排除在列表外,指定對表達式進行查詢。查詢表達式可以使用常亮或列名,而列表可以是一組常亮或者子查詢(更多的情況下)。如果列表為一組常量,則應該放置在一對圓括號內。
其語法如下:
test_expression [NOT] in( subquery expression[,...n] )
參數說明:
①test_expression:SQL 表達式
②subquery:包含某列結果集的子查詢,該列必須與 test_expression 具有相同的數據類型。
③expression[,...n]:一個表達式列表,用來測試是否匹配。所有的表達式必須和 test_expression j具有相同的數據類型。
例如:
select * from tb where selldate not between '2016-10-30' and '2016-12-12';
3.將子查詢作為表達式
將子查詢應用在 SELECT 子句中,其查詢結構就可以以表達式的形式出現。在應用子查詢有一些控制規則,了解這些規則有助於更好的掌握子查詢的應用。
①由比較運算符引入的內層查詢 SELECT 列表或 IN 只包括一個表達式或列名。在外層語句的 WHERE 子句中命名的列必須能與查詢 SELECT 列表中命名的列連接兼容。
②由不可更改的比較運算符引入的子查詢 (比較運算符後面不跟關鍵字ANY 和 ALL)不能包括 GROUP BY 子句或 HAVING 子句,除非預先確定了組或單個的值。
③由 EXISTS 引入的SELECT 列表一般都由星號(*)組成,而不必指定具體的列名,也可以嵌套子查詢 WHERE 子句中限定行。
④子查詢不能在內部處理它們的結果,也就是說,子查詢不能包括 ORDER BY 子句。可選擇的 DISTINCT 關鍵字可有效的對子查詢結果進行排序,因為一些系統會通過首先將結果排序來消除重復記錄。
例如:顯示全部學生總成績及學生總成績與全校平均總成績之差。
select stuId , stuName, (Math+Language+English) Total , round((select avg(Math+Language+English) from tb),0) Averages, round(((Math+Language+English)-(select avg(Math+Language+English) from tb)),0) Average from tb;
4.用子查詢作為派生表
在實際 應用中,經常使用子查詢作為派生表,就是將查詢的結果集作為一個表使用。
子查詢是一個用於處理多表操作的附加方法。語法結構如下:
(SELECT [ALL|DISTINCT]<select item list> From <table list> [WHERE <search condition>] [GROUP BY<group item list> [HAVING <group by search condition>]] )
例如:
將銷售單按商品名稱統計分組後查詢銷售數量大於14的商品(將分組統計數據作為派生表)
select * from (select proname ,COUNT(*) as sl from td GROUP BY proname) WHERE (sl > 14) ;
對商品銷售表中銷售數量前100名進行分組統計(將過濾數據作為派生表)
select sl,count(*) from ( select * from tb ORDER BY zdbh LIMIT 0,100) GROUP BY sl;
統計客戶關系表中未結賬客戶的欠款金額(將過濾數據作為派生表)
select name,sum(xsje) from (select * from tb where NOT pay) GROUP BY name;
查詢所有戰士訓練信息和查詢第三次射擊成績大於8環的戰士信息(將一個查詢結果作為另一個查詢所操作的表)
select T.soldId, T.soldName, T.FrirstGun, T.SecondGun, T.ArtideGun from (select * from tb where ArtideGun>8) as T;
備注:必須為派生表起別名。
5.通過子查詢關聯數據
利用 EXISTS 謂詞引入子查詢。在某些情況下,只要子查詢返回一個真值或假值,只考慮是否滿足謂詞條件,數據內容本身並不重要。此時可以使用 EXISTS 謂詞來定義子查詢。如果子查詢返回一行或多行,EXISTS 謂詞為真,否則為假。要使 EXISTS 謂詞起作用,應該在子查詢中建立查詢條件以匹配子查詢連接起來的兩個表中的值。
語法如下:
EXISTS subquery
參數說明:
subquery:一個受限的 SQL 語句(不允許有 COMPUTE 子句和 INTO 關鍵字) 。
例如:獲取英語成績大於90分的學生信息
select name,college,address from tb_Stu where exists (select name from tb_grades M where M.name=I.name and English>90) ;
備注:EXISTS 謂詞子查詢中的 SELECT 子句中可使用任何列名,也可以使用任何多個列。這種謂詞值只注重是否返回行,而不注重行的內容,用戶可以指定列名或者只使用一個“*”。
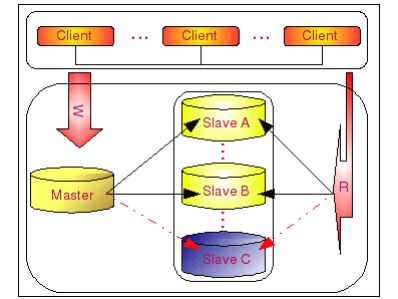
6.實現笛卡爾乘積查詢
笛卡爾乘積查詢實現了兩張表之間的交叉連接,在查詢語句中沒有 WHERE 查詢條件,返回到結果集中的數據行數等於第一個表中符合查詢條件的數據行數乘以第二個表中符合條件的數據行數。
笛卡爾乘積的關鍵字是 CROSS JOIN 。例如,用戶信息表中有2條數據,職工信息表中有4條數據,當這兩張表應用笛卡爾乘積進行查詢時,查詢的結果就是2×4=8條。
例如:
select EmpId,EmpName,Depatment,JobTitle,Wages from tb_employees a cross join tb_position b;
備注:在進行多表查詢時需要主注意,由於多表可能會出現相同的字段,因此在指定查詢字段時,最好為重復的字段起別名,以方便區分。
7.使用 UNION 並運算
UINON 指的是並運算,即從兩個或多個類似的結果集中選擇行,並將其組合在一起形成一個單獨的結果集。
UINON 運算符主要用於將兩個或更多查詢結果組合為單個結果集,該結果集包含聯合查詢中所有查詢的全部行。在使用 UNION 運算符時應遵循以下准則:
①在使用 UNION 運算符組合的語句中,所有選擇列表的表達式數目必須相同(列名、算術表達式、聚集函數等)。
②在使用 UNION 運算符組合的結果集中的相應列或個別查詢中使用的任意列的子集必須具有相同的數據類型,並且兩者數據類型之間必須存在可能的隱性轉換或提供了顯式轉換。
③利用 UNION 運算符組合的各語句中對應的結果集列出現的順序必須相同,因為 UNION 運算符是按照各個查詢給定的順序逐個比較各列。
④ UNION 運算符組合不同的數據類型時,這些數據類型將使用數據類型優先級的規則進行轉換。
⑤通過 UNION 運算符生產的表中列名來自 UNION 語句中的第一個單獨的查詢。若要用新名稱引用結果集中的某列,必須按第一個 SELECT 語句中的方式引用該列。
例如:
select filenumuber,name,juior,address from tb union select filenumuber,name,senior,address from tk;
8.內外連接查詢
1)內聯接(典型的聯接運算,使用像 = 或 <> 之類的比較運算符)。包括相等聯接和自然聯接。
內聯接使用比較運算符根據每個表共有的列的值匹配兩個表中的行。例如,檢索 students和courses表中學生標識號相同的所有行。
內連接可以分為等值連接、自然連接和不等值連接。
等值連接使用等號運算符比較被連接列的值,在查詢結果中將列出連接表中的所有列,包括重復列。等值連接返回所有連接表中具有匹配值的行。
等值連接查詢的語法如下:
select fildList from table1 inner join table2 on table1.column = table2.column;
參數說明:
fildList:要查詢的字段列表。
2)外聯接。外聯接可以是左向外聯接、右向外聯接或完整外部聯接。
在 FROM子句中指定外聯接時,可以由下列幾組關鍵字中的一組指定:
1)LEFT JOIN或LEFT OUTER JOIN
左向外聯接的結果集包括 LEFT OUTER子句中指定的左表的所有行,而不僅僅是聯接列所匹配的行。如果左表的某行在右表中沒有匹配行,則在相關聯的結果集行中右表的所有選擇列表列均為空值。
2)RIGHT JOIN 或 RIGHT OUTER JOIN
右向外聯接是左向外聯接的反向聯接。將返回右表的所有行。如果右表的某行在左表中沒有匹配行,則將為左表返回空值。例如 ,表 A 右外連接表 B,結果為公共部分 C 加表 B 的結果集。如果表 A 中沒有與表 B 匹配的項,就是用 NULL 進行連接。
3)FULL JOIN 或 FULL OUTER JOIN
完整外部聯接返回左表和右表中的所有行。當某行在另一個表中沒有匹配行時,則另一個表的選擇列表列包含空值。如果表之間有匹配行,則整個結果集行包含基表的數據值。
3)交叉聯接
交叉聯接返回左表中的所有行,左表中的每一行與右表中的所有行組合。交叉聯接也稱作笛卡爾積。
FROM 子句中的表或視圖可通過內聯接或完整外部聯接按任意順序指定;但是,用左或右向外聯接指定表或視圖時,表或視圖的順序很重要。有關使用左或右向外聯接排列表的更多信息,請參見使用外聯接。
例子:
-------------------------------------------------
a表 id name b表 id job parent_id
1 張3 1 23 1
2 李四 2 34 2
3 王武 3 34 4
a.id同parent_id 存在關系
--------------------------------------------------
1) 內連接
select a.*,b.* from a inner join b on a.id=b.parent_id 結果是 : 1 張3 1 23 1 2 李四 2 34 2
-------------------------------------------------
2)左連接
select a.*,b.* from a left join b on a.id=b.parent_id 結果是 1 張3 1 23 1 2 李四 2 34 2 3 王武 null
-------------------------------------------------
3) 右連接
select a.*,b.* from a right join b on a.id=b.parent_id 結果是 1 張3 1 23 1 2 李四 2 34 2 null 3 34 4
-------------------------------------------------
4) 完全連接
select a.*,b.* from a full join b on a.id=b.parent_id
結果是
1 張3 1 23 1
2 李四 2 34 2
null 3 34 4
3 王武 nul
-------------------------------------------------
備注:內連接與外連接區別?
內連接只返回兩張表相匹配的數據;而外連接是對內連接的擴展,可以使查詢更具完整性,不會丟失數據。下面舉例說明兩者區別。
假設有兩張表,分別為表A 與 表B,兩張表公共部分為 C 。
內連接的連接結果是兩個表都存在記錄,可以說 A 內連 B 得到的是 C。
表 A 左外連接B,那麼A不受影響,查詢結果為公共部分C 加表A的記錄集。
表A右外連接B,那麼B不受影響,查詢結果為公共部分C加表B的記錄集。
全外連接表示兩張表都不加限制。
////end