上周在生產環境上遇到一個問題,不敢獨享,拿出來給小伙伴們做個簡單的分享。
起因 :由於IDC機房斷電(估計又是哪裡被挖掘機碰了下吧),導致所有服務器重啟,影響到了其中的MySQL數據庫。來看下這時數據庫遇到的問題:
數據庫版本 :MySQL 5.7.10
問題表現
:從機復制報如下錯誤:Slave SQL for channel ”: Slave failed to initialize relay log info structure from the repository, Error_code: 1872
用了Inside君的MySQL標准配置文件模板,怎麼沒有實現crash safe呢?其實,這主要是因為多線程復制(MTS)所引起。不知MySQL 5.7,即使MySQL 5.6也同樣會遇到問題。
在MTS場景下,可能會出現以下兩個問題:
gap事務:後執行的事務先回放(apply)了
Exec_Master_Log_Pos位置不准確:可能存在已經事務已經提交,但是位置還沒更新(單線程復制不存在此問題)
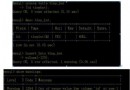
gap事務比較好理解,因為不論是基於database級別的MTS,還是基於logical_clock的MTS,都可能存在下面的這種場景:
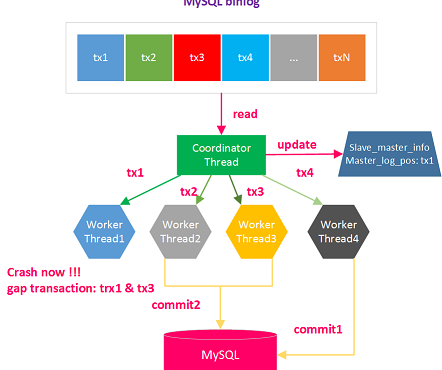
由於MTS的原因,後面的事務可能比前面的事務早執行,如上圖終可能事務tx2和tx4都已經提交了,但是事務tx1和tx3還未提交。這時就稱為存在gap事務。在基於logical_clock的MTS場景下,用戶可以通過配置 參數slave_preserve_commit_order=1 來保證提交的順序性。
另一方面,這時Exec_Master_Log_Pos也是不准確的,當發生crash時,master info中依然記錄的是tx1事務開始執行的位置(見上圖右邊的部分)。切記,即使將參數slave_preserve_commit_order設置為1,MTS場景下依然不能保證Exec_Master_Log_Pos是准確的,其稱之為 gap-free low-watermark 。因為MTS場景下對於表slave_realy_info_log的更新並不是事務的(這個需要好好體會下)。
然而,MTS場景下引入了新的事務表slave_worker_info,用以表示發生宕機時每個線程更新到的位置,其與Worker線程的回放是事務的。因此,MySQL在恢復的時候可以通過通過Exec_Master_Log_Pos與表slave_worker_info的列Master_log_pos做對比,判斷是否需要回放當前事務。
在MySQL 5.7.13版本之前,當發生宕機後需要手動執行如下操作,若直接執行CHANGE MASTER TO操作,則可能會觸發上述1872錯誤:
START SLAVE UNTIL SQL_AFTER_MTS_GAPS; START SLAVE SQL_THREAD;
由於服務器上的MySQL版本為5.7.10,而DBA試圖通過命令CHANGE MASTER TO來修復復制問題,因此導致了上述問題。而在MySQL 5.7.13版本後,上述問題將有MySQL自動修復。簡單來說,即使發生了宕機,也能准確並自動地恢復復制的運行狀態。
不過,當Inside升級到MySQL 5.7.15過程時,又遇到了一個不大不小的坑,這個就留著等下回分享吧。