要得到一組數據的中位數(例如某個地區或某家公司的收入中位數),我們首先要將這一任務細分為3個小任務:
舉例說明:
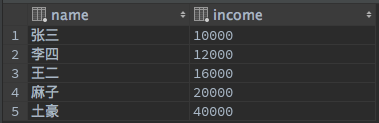
建表語句:
CREATE TABLE `income` (
`name` VARCHAR(10) NOT NULL DEFAULT '',
`income` INT(11) NOT NULL DEFAULT '0'
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO test.income (name, income) VALUES ('麻子', 20000);
INSERT INTO test.income (name, income) VALUES ('李四', 12000);
INSERT INTO test.income (name, income) VALUES ('張三', 10000);
INSERT INTO test.income (name, income) VALUES ('王二', 16000);
INSERT INTO test.income (name, income) VALUES ('土豪', 40000);
小任務1的查詢語句:
SELECT a1.name, a1.income, count(*) AS rank FROM income AS a1, income AS a2 WHERE a1.income < a2.income OR (a1.income = a2.income AND a1.name <= a2.name) GROUP BY a1.name, a1.income ORDER BY rank;
小任務2的查詢語句:
SELECT (COUNT(*) + 1) DIV 2 FROM income;
小任務3的查詢語句:
SELECT income AS median
FROM
(SELECT
a1.name,
a1.income,
count(*) AS rank
FROM income AS a1, income AS a2
WHERE a1.income < a2.income OR (a1.income = a2.income AND a1.name <= a2.name)
GROUP BY a1.name, a1.income
ORDER BY rank) a3
WHERE rank = (SELECT (COUNT(*) + 1) DIV 2
FROM income)
至此,我們就找到了如何從一組數據中獲得中位數的方法。
下面,來介紹另外一種優化排名語句的方法。
我們都知道如何給一組數據做排序操作,在本例中,實現方法如下:
SELECT name, income FROM income ORDER BY income DESC
那我們可不可以更進一步,對查詢出的結果加一列,這一列的數據為排名呢?
我們可以通過3個自定義變量的方法來實現這一目標:
SET @curr_income := 0; SET @prev_income := 0; SET @rank := 0; SELECT name, @curr_income := income AS income, @rank := if(@prev_income != @curr_income, @rank + 1, @rank) AS rank, @prev_income := @curr_income AS dummy FROM income ORDER BY income DESC
查詢結果如下:
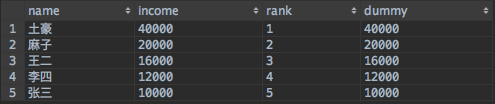
然後再找出中位數的排名數字,進一步找出收入的中位數:
SET @curr_income := 0;
SET @prev_income := 0;
SET @rank := 0;
SELECT income AS median
FROM
(SELECT
name,
@curr_income := income AS income,
@rank := if(@prev_income != @curr_income, @rank + 1, @rank) AS rank,
@prev_income := @curr_income AS dummy
FROM income
ORDER BY income DESC) AS a1
WHERE a1.rank = (SELECT (COUNT(*) + 1) DIV 2
FROM income)
至此,我們找了兩種方法來解決中位數的問題。撒花。