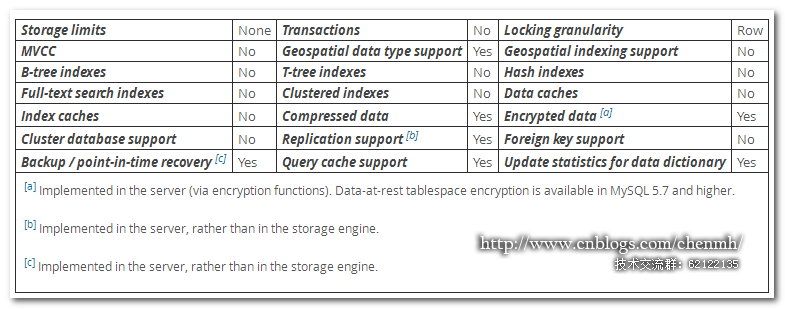
從archive單詞的解釋我們大概可以明白這個存儲引擎的用途,這個存儲引擎基本上用於數據歸檔;它的壓縮比非常的高,存儲空間大概是innodb的10-15分之一所以它用來存儲歷史數據非常的適合,由於它不支持索引同時也不能緩存索引和數據,所以它不適合作為並發訪問表的存儲引擎。Archivec存儲引擎使用行鎖來實現高並發插入操作,但是它不支持事務,其設計目標只是提供高速的插入和壓縮功能。
每個archive表在磁盤上存在兩個文件
.frm(存儲表定義)
.arz(存儲數據)
1.archive存儲引擎支持insert、replace和select操作,但是不支持update和delete。
2.archive存儲引擎支持blob、text等大字段類型。支持auto_increment自增列同時自增列可以不是唯一索引。
3.archive支持auto_increment列,但是不支持往auto_increment列插入一個小於當前最大的值的值。
4.archive不支持索引所以無法在archive表上創建主鍵、唯一索引、和一般的索引。
往archive表插入的數據會經過壓縮,archive使用zlib進行數據壓縮,archive支持optimize table、 check table操作。
一個insert語句僅僅往壓縮緩存中插入數據,插入的數據在壓縮緩存中被鎖定,當select操作時會觸發壓縮緩存中的數據進行刷新。insert delay除外。
對於一個bulk insert操作只有當它完全執行完才能看到記錄,除非在同一時刻還有其它的inserts操作,在這種情況下可以看到部分記錄,select從不刷新bulk insert除非在它加載時存在一般的Insert操作。
對於檢索請求返回的行不會壓縮,且不會進行數據緩存;一個select查詢會執行完整的表掃描;當一個select查詢發生時它查找當前表所有有效的行,select執行一致性讀操作,注意,過多的select查詢語句會導致壓縮插入性能變的惡化,除非使用bulk insert或delay insert,可以使用OPTIMIZE TABLE 或REPAIR TABLE來獲取更好的壓縮,可以使用SHOW TABLES STATUS查看ARCHIVE表的記錄行。
Archive存儲引擎支持分區
create table tb_archive(id int not null , name varchar(30), address varchar(300), mark text)engine=archive;
ALTER TABLE tb_archive
PARTITION BY RANGE(id) PARTITIONS 3( PARTITION part0 VALUES LESS THAN (5), PARTITION part1 VALUES LESS THAN (10), PARTITION part2 VALUES LESS THAN (MAXVALUE)) ;
ALTER TABLE tb_archive
PARTITION BY LIST COLUMNS (name) (
PARTITION a VALUES IN ('A','B'),
PARTITION b VALUES IN ('C'),
PARTITION c VALUES IN ('D')
);
ALTER TABLE tb_archive
PARTITION BY KEY(address)
PARTITIONS 3;

參考來自:http://dev.mysql.com/doc/refman/5.6/en/archive-storage-engine.html
由於高壓縮和快速插入的特點Archive非常適合作為日志表的存儲引擎,但是前提是不經常對該表進行查詢操作。
備注:
作者:pursuer.chen
博客:http://www.cnblogs.com/chenmh
本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須注明文章來源,且在文章開頭明顯處給明鏈接。
《歡迎交流討論》