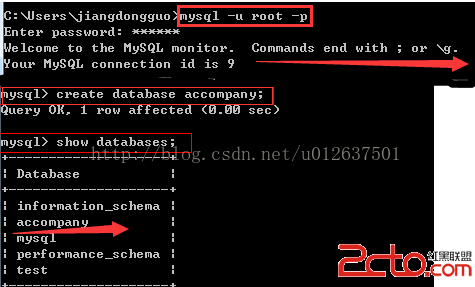
昨天去一家公司面試,被這道題難住了,哎,又失去一次好的機會。
回來 之後就再想這個問題
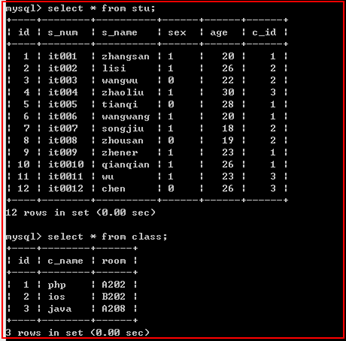
表結構及數據如下:
實現的sql語句:
剛開始的實現是
select * from student a where a.id in (SELECT b.id from student b where b.classId=a.classId ORDER BY grade DESC LIMIT 0,3) ;
看起來沒毛病,其實一大堆,第一 對於mysql來說,in(裡面不能使用limit) 有語法錯誤,第二 前三名不一定就只有3位哦
嘗試改:語句理解:也就是只要班級裡有三個學生的分數超過這個學生,那麼這個學生就不是前三名。
select * from student b
where
not EXISTS(select * from student c where c.classId=b.classId and b.grade < c.grade GROUP BY c.classId HAVING COUNT(*)>3 )
結果顯示
查詢次數統計
not exists 其實是嵌套循環。如果student有1000條數據,則會查詢1+1000次,如果還不理解,就用java代碼協助下
List<Student> students =studentService.queryAll();//查詢出全部
for(int i=0;i<students.length();i++){
//過濾前三名
//查詢是不是班級前三名
}
所以總共查詢1+n次,n表示student表的總條數
感覺不靠譜,如果有10W條數據,就查詢了10W次,真是受不了的,再想想,有好方法的朋友快來圍觀,十分感激!