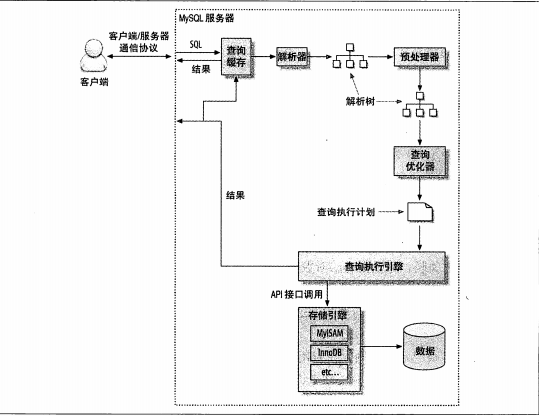
 mysql客戶端/服務器通信協議
mysql客戶端和服務器之間的通信協議是"半雙工"。任何時候只能一方發;不能同時發送;
mysql連接時線程狀態
mysql客戶端/服務器通信協議
mysql客戶端和服務器之間的通信協議是"半雙工"。任何時候只能一方發;不能同時發送;
mysql連接時線程狀態
mysql> show full processlist; +----+------+-----------+--------+---------+------+-------+------------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+-----------+--------+---------+------+-------+------------------------+ | 39 | root | localhost | sakila | Sleep | 4 | | NULL | | 40 | root | localhost | sakila | Query | 0 | NULL | show full processlist | +----+------+-----------+--------+---------+------+-------+------------------------+ 2 rows in set (0.00 sec)
查詢優化器
mysql> select count(*) from film_actor; +----------+ | count(*) | +----------+ | 5462 | +----------+ 1 row in set (0.00 sec) mysql> show status like 'last_query_cost'; +-----------------+-------------+ | Variable_name | Value | +-----------------+-------------+ | Last_query_cost | 1040.599000 | +-----------------+-------------+
這個結果表示mysql優化器認為大概需要做1040個數據頁的隨機查找才能完成上面的查詢。這是根據一系列的統計信息計算得來的:每個表或者索引的頁面個數,索引的基數(索引中不同值的數量),索引和數據行的長度,索引分布情況。 優化器在評估成本的時候並不考慮任何層面的緩存,它假設讀取任何數據都需要一次磁盤I/O。 mysql優化器選錯執行計劃的原因:
mysql> select * from film where film_id in ( select film_id from film_actor where actor_id =1) \G;
我們一般認為,mysql會首先將子查詢的actor_id=1的所有film_id都找到,然後再去做外部查詢,如
select * from film where film_id in (1,23,25,106,140);
然而,mysql不是這樣做的。 mysql會將相關的外層表壓到子查詢中,它認為這樣可以更高效率地查找數據行。 當然我們可以使用連接替代子查詢重寫這個SQL,來優化;
mysql> explain select * from film f inner join film_actor fa where f.film_id=fa.film_id and actor_id =1; +----+-------------+-------+--------+------------------------+---------+---------+-------------------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+--------+------------------------+---------+---------+-------------------+------+-------+ | 1 | SIMPLE | fa | ref | PRIMARY,idx_fk_film_id | PRIMARY | 2 | const | 19 | | | 1 | SIMPLE | f | eq_ref | PRIMARY | PRIMARY | 2 | sakila.fa.film_id | 1 | | +----+-------------+-------+--------+------------------------+---------+---------+-------------------+------+-------+ 2 rows in set (0.00 sec)
如何用好關聯子查詢,很多時候,關聯子查詢也是一種非常合理,自然,甚至是性能最好的寫法。 where in()肯定是不行的,但是 where exists()有時是可以的; 2 union的限制 有時,mysql無法將限制條件從外層"下推"到內層,這使得原本能夠限制部分返回結果的條件無法應用到內層查詢的優化上。 如果希望union的各個子句能夠根據limit只取部分結果集,或者希望能夠先拍下再合並結果集的話,就需要在union的各個子句中分別使用這些子句。 如:
(select first_name,last_name from sakila.actor order by last_name) union all (select first_name,last_name from sakila.customer order by last_name) limit 20;會將actor中200條記錄和customer中599條記錄放在一個臨時表中,然後在從臨時表中取出前20條; 而
(select first_name,last_name from sakila.actor order by last_name limit 20) union all (select first_name,last_name from sakila.customer order by last_name limit 20) limit 20;
現在中間的臨時表中只會包含40條記錄。
3 最大值和最小值優化 對於min()和max()查詢,mysql的優化做得並不好。mysql> explain select min(actor_id) from actor where first_name='PENELOPE'; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 200 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec)
因為在first_name字段上沒有索引,因此mysql將會進行一次全表掃描。 如果mysql能夠進行主鍵掃描,那麼理論上,mysql讀到第一個滿足條件的記錄的時候,就是我們需要找的最小值了,因為主鍵時嚴格按照actor_id字段的大小順序排序的。但這僅僅是如果,mysql這時只會做全表掃描。 優化min(),使用limit重寫SQL:
mysql> explain select actor_id from actor USE INDEX(PRIMARY) where first_name='PENELOPE' LIMIT 1; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 200 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec)看著實驗結果,似乎沒有使用 主鍵索引,不知道是什麼原因導致.歡迎交流。 4 在同一個表上查詢和更新 mysql不允許,對同一張表進行查詢和更新:
mysql> update tbl AS outer_tbl
set cnt = (
select count(*) from tbl AS inner_tbl
where inner_tbl.type = outer_tbl.type
);
error:you can't specify target table 'outer_tbl' for update in from clause
可以使用內連接來繞過這個限制。實際上,這執行了兩個查詢:一個是子查詢中的select語句,另一個是多表關聯update,只是關聯的表是一個臨時表。
mysql> update tbl
inner join (
select type,count(*) AS cnt
from tbl
group by type
)AS der using(type)
set tbl.cnt = der.cnt;
優化器的提示(hint)
mysql> show status like 'com%'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | Com_admin_commands | 0 | | Com_assign_to_keycache | 0 | | Com_alter_db | 0 | | Com_alter_procedure | 0 | | Com_alter_server | 0 | | Com_alter_table | 0 |com_xxx表示每個xxx語句執行的次數: com_select: 執行select操作的次數,一次查詢只累加一次; com_insert: 執行insert操作的次數,對於批量插入的insert操作,只累加一次; com_update: 執行update操作的次數 com_delete: 執行delete操作的次數 上面這些參數對於所有存儲引擎的表操作都會進行累計。下面幾個參數只是針對innodb存儲引擎,累加算法也略有不同。 innodb_rows_read: select查詢返回的行數 innodb_rows_inserted: 執行insert操作插入的行數 innodb_rows_updated: 執行update操作更新的行數 innodb_rows_deleted: 執行delete操作刪除的行數 通過以上參數,很容易了解當前數據庫的應用是以插入更新為主還是以查詢操作為主,大致的讀寫比例是多少; 可以通過com_commit 和 com_rollback 可以知道,事務回滾的比例; 如果比例過高則說明應用編寫存在問題; connections: 試圖連接mysql服務器的次數 uptime: 服務器工作時間 slow_queries: 慢查詢的次數; 2 定位低效 SQL
mysql> explain select b from t where a =1; +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | 1 | SIMPLE | t | ref | a | a | 5 | const | 1 | Using where | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ 1 row in set (0.00 sec)
當然explain也可以來查詢使用了什麼索引;
mysql> select @@have_profiling; +------------------+ | @@have_profiling | +------------------+ | YES | +------------------+查看profiling是否開啟,默認關閉:
mysql> select @@profiling; +-------------+ | @@profiling | +-------------+ | 0 | +-------------+ 1 row in set (0.00 sec)
開啟profiling:
mysql> set profiling=1; Query OK, 0 rows affected (0.00 sec)通過profile,我們能夠更清楚地了解SQL執行的過程。 如何使用:
mysql> select count(*) from payment; +----------+ | count(*) | +----------+ | 16049 | +----------+ 1 row in set (0.02 sec)
通過show profiles,找到對應SQL的 query id;
mysql> show profiles; +----------+------------+------------------------------+ | Query_ID | Duration | Query | +----------+------------+------------------------------+ | 1 | 0.01064275 | select count(*) from payment | | 2 | 0.00048225 | show databases | | 3 | 0.00015000 | show DATABASE() | | 4 | 0.00039975 | show tables | +----------+------------+------------------------------+通過show profile for query id ,分析具體的SQL; 能夠看到執行過程中線程的每個狀態和消耗的時間;
mysql> show profile for query 4; +----------------------+----------+ | Status | Duration | +----------------------+----------+ | starting | 0.000058 | | checking permissions | 0.000009 | | Opening tables | 0.000050 | | System lock | 0.000008 | | init | 0.000012 | | optimizing | 0.000005 | | statistics | 0.000012 | | preparing | 0.000010 | | executing | 0.000007 | | checking permissions | 0.000132 | | Sending data | 0.000042 | | end | 0.000007 | | query end | 0.000007 | | closing tables | 0.000005 | | removing tmp table | 0.000009 | | closing tables | 0.000006 | | freeing items | 0.000015 | | logging slow query | 0.000005 | | cleaning up | 0.000006 | +----------------------+----------+ 19 rows in set (0.00 sec)在獲取到最消耗時間的線程狀態後,mysql支持進一步選擇all,cpu,block io ,context switch,page faults等明細類型來查看mysql在使用什麼資源上耗費了過高的時間。 例如選擇查看cup的消耗時間:
mysql> show profile cpu for query 4; +----------------------+----------+----------+------------+ | Status | Duration | CPU_user | CPU_system | +----------------------+----------+----------+------------+ | starting | 0.000058 | 0.000000 | 0.000000 | | checking permissions | 0.000009 | 0.000000 | 0.000000 | | Opening tables | 0.000050 | 0.000000 | 0.000000 | | System lock | 0.000008 | 0.000000 | 0.000000 | | init | 0.000012 | 0.000000 | 0.000000 | | optimizing | 0.000005 | 0.000000 | 0.000000 | | statistics | 0.000012 | 0.000000 | 0.000000 | | preparing | 0.000010 | 0.000000 | 0.000000 | | executing | 0.000007 | 0.000000 | 0.000000 | | checking permissions | 0.000132 | 0.000000 | 0.000000 | | Sending data | 0.000042 | 0.000000 | 0.000000 | | end | 0.000007 | 0.000000 | 0.000000 | | query end | 0.000007 | 0.000000 | 0.000000 | | closing tables | 0.000005 | 0.000000 | 0.000000 | | removing tmp table | 0.000009 | 0.000000 | 0.000000 | | closing tables | 0.000006 | 0.000000 | 0.000000 | | freeing items | 0.000015 | 0.000000 | 0.000000 | | logging slow query | 0.000005 | 0.000000 | 0.000000 | | cleaning up | 0.000006 | 0.000000 | 0.000000 | +----------------------+----------+----------+------------show profile 能夠在做SQL優化時幫助我們了解時間都耗費到哪裡去了; 而mysql5.6則通過trace文件進一步向我們展示了優化器是如何選擇執行計劃的。 5 通過trace 分析優化器如何選擇執行計劃 提供了對SQL的跟蹤trace,通過trace文件能夠進一步了解為什麼優化器選擇A執行計劃而不選擇B執行計劃,幫助我們更好地理解優化器的行為。 使用方式: 首先打開trace,設置格式為json,設置trace最大能夠使用的內存大小,避免解析過程中因為默認內存過小而不能完整顯示。 然後執行select; 最後在,information_schema.optimizer_trace中查看跟蹤文件; 索引問題
mysql> show status like 'Handler_read%'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | Handler_read_first | 1 | | Handler_read_key | 6 | | Handler_read_last | 0 | | Handler_read_next | 16050 | | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 297 | +-----------------------+-------+ 7 rows in set (0.00 sec)
mysql> analyze table store; +--------------+---------+----------+----------+ | Table | Op | Msg_type | Msg_text | +--------------+---------+----------+----------+ | sakila.store | analyze | status | OK | +--------------+---------+----------+----------+ 1 row in set (0.00 sec)本語句用於分析和存儲表的關鍵字分布,分析的結果將可以使得系統得到准確的統計信息,是的SQL能夠生成正確的執行計劃。 如果用戶感覺實際執行計劃並不是預期的執行計劃,執行一次分析表可能會解決問題。 檢查表:
mysql> check table store; +--------------+-------+----------+----------+ | Table | Op | Msg_type | Msg_text | +--------------+-------+----------+----------+ | sakila.store | check | status | OK | +--------------+-------+----------+----------+ 1 row in set (0.01 sec)檢查表的作用是檢查一個或多個表是否有錯誤。 check table 也可以檢查視圖是否有錯誤,比如在視圖定義中被引用的表已經不存在; 定期優化表 優化表:
mysql> optimize table store; +--------------+----------+----------+-------------------------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +--------------+----------+----------+-------------------------------------------------------------------+ | sakila.store | optimize | note | Table does not support optimize, doing recreate + analyze instead | | sakila.store | optimize | status | OK | +--------------+----------+----------+-------------------------------------------------------------------+ 2 rows in set (0.04 sec)將表中的空間碎片進行合並,並且可以消除由於刪除或者更新造成的空間浪費; 適用於:已經刪除了表的一大部分,或者已經對含有可變長度行的表(含有varchar,blob,text)進行了很多更改,此時表中的空間會產生大量的空間碎片; 另外innodb表在刪除大量數據後: 可以使用alter table 但是不修改引擎的方式來回收不用的空間:
mysql> alter table payment engine=innodb; Query OK, 16049 rows affected (0.62 sec) Records: 16049 Duplicates: 0 Warnings: 0
常用SQL的優化
mysql> alter table customer add index idx_email_storeid (email,store_id);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select store_id,email, customer_id from customer order by email\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
type: index
possible_keys: NULL
key: idx_email_storeid
key_len: 154
ref: NULL
rows: 652
Extra: Using index
1 row in set (0.00 sec)
可以看到,此時只使用了索引順序,沒有使用filesort; 如果將索引改成:
mysql> alter table customer drop index idx_email_storeid;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table customer add index idx_storeid_email (store_id,email);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select store_id,email, customer_id from customer order by email\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
type: index
possible_keys: NULL
key: idx_storeid_email
key_len: 154
ref: NULL
rows: 652
Extra: Using index; Using filesort
1 row in set (0.00 sec)
可以看到,此時使用到了filesort 這種額外排序,這顯然會增加開銷;
可見,索引最左端原則,order by email,那麼email 這一列在索引中應該在最左端,這樣才能夠只使用索引排序,而不用使用filesort;
優化目標:
盡量減少額外的排序,通過索引直接返回有序數據。
到達這目的要求:where 條件和 order by 使用相同的索引,並且order by 的順序和索引順序相同,並且order by的字段都是升序或者降序。否則肯定需要額外的排序操作,這樣就會出現filesort;
總結:
下列SQL可以使用索引:
mysql> explain select payment_date,sum(amount) from payment group by payment_date \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: payment
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 16451
Extra: Using temporary; Using filesort
1 row in set (0.01 sec)
使用order by null優化group by
mysql> explain select payment_date,sum(amount) from payment group by payment_date ORDER BY NULL \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: payment
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 16451
Extra: Using temporary
1 row in set (0.00 sec)
5 優化嵌套查詢 子查詢可以被更有效率的連接(join)替代; 連接(join)之所以更有效率一些,因為mysql不需要在內存中創建臨時表來完成這個邏輯上需要兩個步驟的查詢工作; 6 mysql 如何優化or條件 對於含有or的查詢子句,如果要利用索引,則or之間的每個條件列都必須用到索引;如果沒有索引,則應該考慮增加索引; mysql在處理含有or子句的查詢時,實際是對or的各個字段分別查詢後的結果進行了union 操作; 但是在建有符合索引的列 company_id 和moneys上面做or操作時,卻不能用到索引; 7 優化分頁查詢 延遲關聯,它讓mysql掃描盡可能少的頁面,索取需要訪問的記錄後再根據關聯列回原表查詢需要的所有列。 考慮下面的查詢:
mysql> explain select film_id,description from film order by title limit 50,5; +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | 1 | SIMPLE | film | ALL | NULL | NULL | NULL | NULL | 1134 | Using filesort | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ 1 row in set (0.00 sec)使用"延遲關聯":
mysql> explain select film_id,description from film inner join ( select film_id from film order by title limit 50,5) AS lim using(film_id); +----+-------------+------------+--------+---------------+-----------+---------+-------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+--------+---------------+-----------+---------+-------------+------+-------------+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 5 | | | 1 | PRIMARY | film | eq_ref | PRIMARY | PRIMARY | 2 | lim.film_id | 1 | | | 2 | DERIVED | film | index | NULL | idx_title | 767 | NULL | 55 | Using index | +----+-------------+------------+--------+---------------+-----------+---------+-------------+------+-------------+ 3 rows in set (0.00 sec)首先,讓film_id使用索引,找到對應film_id,然後再回表找到對應description的數據列。這樣,是延遲了列的訪問,所以叫延遲關聯;其實是分別找出對應列的數據行; 使用書簽記錄 offset,它會導致mysql掃描大量不需要的行然後再拋棄掉。 可以使用書簽記錄上次數據的位置,那麼下次就可以直接從書簽記錄的位置開始掃描,這樣就可以避免使用offset; 首先獲得第一組結果:
mysql> select * from rental order by rental_id limit 5; +-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+ | rental_id | rental_date | inventory_id | customer_id | return_date | staff_id | last_update | +-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+ | 1 | 2005-05-24 22:53:30 | 367 | 130 | 2005-05-26 22:04:30 | 1 | 2006-02-15 21:30:53 | | 2 | 2005-05-24 22:54:33 | 1525 | 459 | 2005-05-28 19:40:33 | 1 | 2006-02-15 21:30:53 | | 3 | 2005-05-24 23:03:39 | 1711 | 408 | 2005-06-01 22:12:39 | 1 | 2006-02-15 21:30:53 | | 4 | 2005-05-24 23:04:41 | 2452 | 333 | 2005-06-03 01:43:41 | 2 | 2006-02-15 21:30:53 | | 5 | 2005-05-24 23:05:21 | 2079 | 222 | 2005-06-02 04:33:21 | 1 | 2006-02-15 21:30:53 | +-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+之後從書簽開始再找:
mysql> select * from rental where rental_id > 5 order by rental_id limit 5; +-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+ | rental_id | rental_date | inventory_id | customer_id | return_date | staff_id | last_update | +-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+ | 6 | 2005-05-24 23:08:07 | 2792 | 549 | 2005-05-27 01:32:07 | 1 | 2006-02-15 21:30:53 | | 7 | 2005-05-24 23:11:53 | 3995 | 269 | 2005-05-29 20:34:53 | 2 | 2006-02-15 21:30:53 | | 8 | 2005-05-24 23:31:46 | 2346 | 239 | 2005-05-27 23:33:46 | 2 | 2006-02-15 21:30:53 | | 9 | 2005-05-25 00:00:40 | 2580 | 126 | 2005-05-28 00:22:40 | 1 | 2006-02-15 21:30:53 | | 10 | 2005-05-25 00:02:21 | 1824 | 399 | 2005-05-31 22:44:21 | 2 | 2006-02-15 21:30:53 | +-----------+---------------------+--------------+-------------+---------------------+----------+---------------------+ 5 rows in set (0.00 sec)總結