mysql> SHOW CHARACTER SET ; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 | | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
新增字符集:
在編譯mysql時用--with-charset=gbk 來新增字符集
 字符集與字符序(字符排序的規則)
charset 和 collation
字符集與字符序是一對多的關系,但一個字符集至少有一個字符序
collation:字符序,字符的排序與比較規則,每個字符集都有對應的多套字符序。
不同的字符序決定了字符串在比較排序中的精度和性能不同。
查看字符序
字符集與字符序(字符排序的規則)
charset 和 collation
字符集與字符序是一對多的關系,但一個字符集至少有一個字符序
collation:字符序,字符的排序與比較規則,每個字符集都有對應的多套字符序。
不同的字符序決定了字符串在比較排序中的精度和性能不同。
查看字符序
mysql> SHOW COLLATION ;mysql的字符序遵從命名慣例:
create database db_name character set latin1 collate latin1_swedish_ci;-character_set_database:當前選中數據庫的默認字符集 主要影響load data 等語句的默認字符集;create database的字符集如果不設置,默認使用character_set_server的字符集。 表級
mysql>create table tbl(...) default charset=utf-8 default collate=utf8_bin
數據存儲字符集使用規則:
mysql> SHOW VARIABLES LIKE '%CHARACTER%'; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec) mysql> SHOW VARIABLES LIKE '%collation%'; +----------------------+-------------------+ | Variable_name | Value | +----------------------+-------------------+ | collation_connection | utf8_general_ci | | collation_database | latin1_swedish_ci | | collation_server | latin1_swedish_ci | +----------------------+-------------------+修改字符集 修改服務器級字符集
set global character_set_server=utf8; (全局)修改表級字符集 alter table tbl convert to character set XXX;(表)
mysql> alter table stu convert to character set utf8;
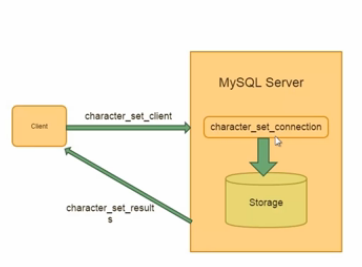
客戶端連接與字符集 連接與字符集 -character_set_client:客戶端來源數據使用的字符集(客戶端程序發過來的SQL用什麼來編碼的) -character_set_conection:連接層字符集(做中間層轉換) -character_set_results:查詢結果字符集(返回給客戶端程序用的字符集) 一般可以統一設置(推薦):
msyql>set names utf8;也可以統一叫做連接字符集; 在配置文件中: default-character-set = utf8 客戶端連接字符集

常見亂碼原因:
aiapple@ubuntu:~$ file test.t test.t: UTF-8 Unicode text aiapple@ubuntu:~$ cat test.t 你好 mysql> show variables like '%char%'; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | gbk | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec) mysql>load data infile '/home/aiapple/test.t' into table t;
此時會出現亂碼,即告知數據庫的character_set_database 的字符集與程序使用的文件test.t 不一樣;
更改set character_set_database = utf8 則能正常顯示; 這裡與 普通告知mysql字符集 set names xxx 區別開來,畢竟是導入表到一個數據庫當中,應該使數據庫的字符集與文件的字符集相同 客戶端連接與字符集 使用建議:
三要素: 1.程序驅動或客戶端的字符集(在客戶端設置) 2.告知mysql的字符集(set names xxx) 3.數據存儲的字符集(表結構的字符集alter table tbl convert to character set xxx) 前兩個必須一致才不會出現亂碼,推薦三個都設置成一致 需求:在系統運行了一段時間,有了一定的數據,後發現字符集不能滿足要求需要重新修改,又不想丟棄這段時間的數據。 alter database character set xxx 或者alter table tablename character set xxx;這兩條命令只對想創建的表或者記錄生效 方法:先將數據導出,經過適當的調整重新導入才可完成。 以下模擬的是將latin1字符集的數據庫修改成GBK字符集的數據庫的過程 1)導出表結構
mysqldump -uroot -p --default-character-set=gbk -d WY_yun >createtab.sq--default-character-set表示設置以什麼字符集連接;-d表示只導出表結構,不導出數據 2)手動修改creatatab.sql中表結構定義中的字符集為新的字符集 3)確保記錄不在更新,導出所有記錄
mysqldump -uroot -p --quick --no-create-info --extended-insert --default-character-set=latin1 WY_yun > data.sql-quick:該選項用於轉存儲大的表。它強制mysqldump 從服務器一次一行地檢索表中的行,而不是檢索所有的行,並在輸出前將它緩存到內存中。 --no-create-info:不寫重新創建麼個轉存儲表的create table 語句 --extended-insert:使用包括幾個VALUES列表的多行insert語法。這樣使轉存儲文件更小,重載文件時可以加速插入 --default-character-set=latin1:按照原有的字符集導出所有數據,這樣導出的文件中,所有中文都是可見的,不會保存成亂碼 4)修改數據的字符集為新字符集---打開data.sql,將set names latin1 修改成 set names gbk 5)使用新得字符集創建新的數據庫
mysql> create database na default charset gbk;6)將新字符集的表結構導入新庫;創建表,執行createtab.sql
mysql -uroot -p na <createtab.sql7) 將新字符集的數據文件導入新庫;導入數據,執行data.sql
mysql -uroot -p na < data.sql似乎實驗沒有成功可以去提問?
總結