- select * from play_list order by createtime; - select * from play_list order by bookedcount desc,createtime asc;order by 語句用於根據指定的列對結果集進行排序 order by 語句默認按照升序對記錄排序,使用desc則降序排序 order by 也可以多個字段排序,而desc只作用於一個字段; distinct
select distinct userid from play_list;
select distinct userid,play_name from play_list;
(userid,play_named都相同時去重)
distinct 用於去重,可以返回多列的唯一組合;
distinct 在後台做排序,所以很消耗CUP的;
group by having
場景:統計雲音樂創建歌單的用戶列表和每人創建歌單的數量
mysql> select userid,count(*) AS play_num from play_list group by userid having count(*)>=2;分組關鍵字userid,需要在查詢中出現,且一般查詢分組關鍵字後要加聚合函數; like
select * from play_list where play_name like '%男孩%';
通配符 描述 % 代替一個或多個字符 _ 替代單個字符 [charlist] 中括號中的任何單一字符 [^charlist] 或者 [!charlist] 不在中括號中的任何單一字符 大表慎用like; 除了%號在最右邊以外,會對表中所有記錄進行查詢匹配; limit offset 場景4:查詢一個月內創建的歌單(從第6行開始顯示10條記錄)
select * from play_list where (createtime between 1427701323 and 1430383307) limit 10 offset 6注意:offset 後面的值不要太大,假設offset1000,那它會掃描前1000條記錄,這樣IO開銷會很大 case when case when 實現類似編程語言的 if else 功能,可以對SQL的輸出結果進行選擇判斷; 場景5:對於未錄入的歌單(trackcount = null),輸出結果時歌曲數返回0
mysql> select play_name,case when trackcount is null then 0 else trackcount end from play_list;連接-join 用一個SQL 語句把多個表中相互關聯的數據查詢出來; 場景6:查詢收藏“老男孩”歌單的用戶列表
mysql> SELECT play_fav.userid FROM play_fav INNER JOIN play_list ON play_fav.play_id = play_list.id where play_list.play_name = '老男孩';另一種寫法:
mysql> select f.userid from play_list lst,play_fav f where lst.id = f.play_id and lst.play_name = '老男孩'
子查詢及問題
select userid from play_fav where play_id=(select id from play_list where play_name = '老男孩');別名 可以不用使用AS 關鍵字,直接空格加別名就可以了; 子查詢在性能上有一定劣勢,不利於mysql性能優化器進行優化; 因為內層表和驅動表用戶自己定死了,而聯結的驅動表和內層表 性能優化器 會根據實際情況 來定; 子查詢為什麼不利於優化: 聯結是嵌套循環查詢實現; 如select * from play_list,play_fav where play_list.id = play_fav.play_id; play_list驅動表(where等號左邊);內層表play_fav(where等號右邊); 遍歷去東北play_list.id,找到一個id後再去play_fav.play_id中找;依次循環下去; 內層表此時可以查詢一次或者幾次索引,便可以得到; 所以基本的優化就是將表量比較小的作為驅動表,這樣減少了循環的次數; union 作用:把不同表中相同的字段聚合在一個結果集中返回給用戶 場景8:老板想看創建和收藏歌單的所有用戶,查詢play_list和play_fav兩表中所有的userid;
mysql> select userid from play_list
-> union
-> select userid from play_fav;
默認的union 會對結果集進行去重處理,不想去重使用 union all;
DML進階語法
mysql> insert into a values(1,100) on duplicate key update age=100;如果id = 1存在,則鍵age 更改為100; 注意得是主鍵噢,如何表中沒有設置主鍵,則會新增加一條記錄; 而給表a增加主鍵則是:
mysql> alter table order add primary key (id);
連表update
 用B表中的age 更新到 A 表中的age :
用B表中的age 更新到 A 表中的age :
mysql> select * from a; +----+------+ | id | age | +----+------+ | 1 | 100 | | 2 | 34 | | 3 | 23 | | 4 | 29 | +----+------+ mysql> select * from b; +------+------+------+ | id | name | age | +------+------+------+ | 1 | pw | 20 | | 2 | ljb | 30 | +------+------+------+ mysql> update a,b set a.age=b.age where a.id = b.id; mysql> select * from a; +----+------+ | id | age | +----+------+ | 1 | 20 | | 2 | 30 | | 3 | 23 | | 4 | 29 | +----+------+連表delete 用B表中的條件去刪除A表中數據;

mysql> select * from a; +----+------+ | id | age | +----+------+ | 1 | 20 | | 2 | 30 | | 3 | 23 | | 4 | 29 | +----+------+ mysql> select * from b; +------+------+------+ | id | name | age | +------+------+------+ | 1 | pw | 20 | | 2 | ljb | 30 | +------+------+------+ mysql> delete a from a,b where a.id=b.id and b.name='pw'; mysql> select * from a; +----+------+ | id | age | +----+------+ | 2 | 30 | | 3 | 23 | | 4 | 29 | +----+------+
刪除語法:
DELETE FROM Customers WHERE cust_id = '1000000006';連表在delete之後還要將需要刪除的表放在delete後面; 內置函數
場景:查詢播放次數最多的歌曲
mysql> select song_name,max(playcount) from song_list; //錯誤查法 #select song_name,沒有對應 playcount; #注意聚合函數是對返回列來做處理的,此中放回列是所有歌曲; mysql> select song_name,playcount from song_list order by playcount desc limit1;//正確 子查詢方法: select song_name from song_list where playcount=(select max(playcount) from song_list);
場景:顯示每張專輯的歌曲列表。例如:

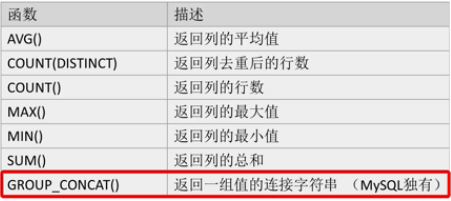
mysql> select album,group_concat(song_name) from song_list group by album; +------------------+-------------------------------------------------+ | album | group_concat(song_name) | +------------------+-------------------------------------------------+ | 1701 | 大象,定西 | | Straight Shooter | Good Lovin' Gone Bad,Weep No More,Shooting Star | | 作品李宗盛 | 風櫃來的人 | | 紅雪蓮 | 紅雪蓮 | +------------------+-------------------------------------------------+group_concat 連接的最長字符是1024,可以通過參數調整; 使用聚合函數做數據庫行列轉換:



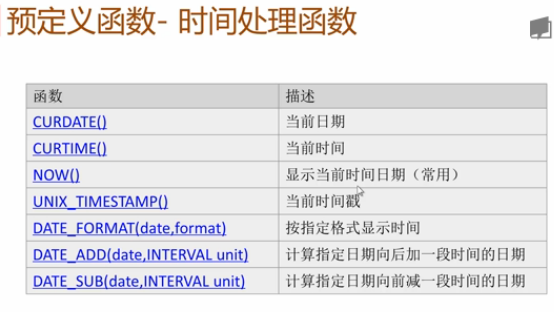
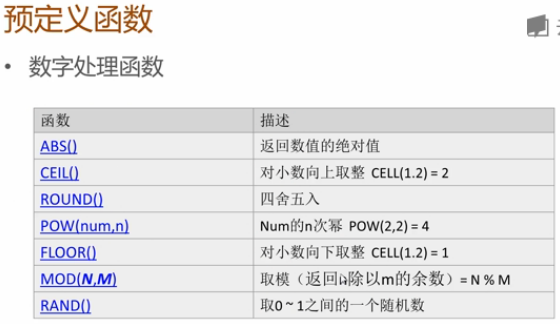
 預定義函數:
預定義函數:

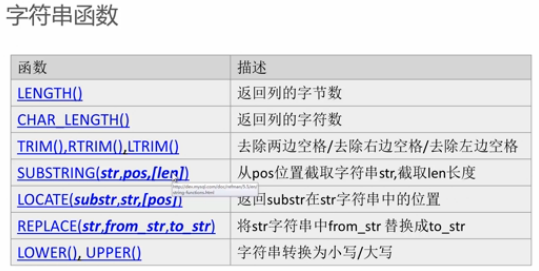



 時間處理函數:
時間處理函數:





總結