第 18 章 高可用設計之 MySQL 監控
前言:
一個經過高可用可擴展設計的 MySQL 數據庫集群,如果沒有一個足夠精細足夠強大的監控系統,同樣可能會讓之前在高可用設計方面所做的努力功虧一篑。一個系統,無論如何設計如何維護,都無法完全避免出現異常的可能,監控系統就是根據系統的各項狀態的分析,讓我們能夠盡可能多的提前預知系統可能會出現的異常狀況。即使沒有及時發現將要發生的異常,也要在異常出現後的第一時間知道系統已經出現異常,否則之前的設計工作很可能就白費了。
18.1 監控系統設計
系統監控在很多人眼中是一個沒有多少技術含量的事情,其實並不是這樣的。且不說一個大型網站的所有設備的監控,就僅僅只是搭建一個比較完善的幾十台 MySQL 集群系統的監控,很可能就會讓很多人束手無策,或者功能不夠完善。
其實一個完善的大型集群系統的監控系統,和少數幾台主機的監控是有很大差別的。少數機台主機的監控在大多數時候可以通過幾個簡單的腳本(Shell或者Perl等),發發郵件,再高一點的報警信息發發手機短信,基本就搞定了。監控點少,發出的信息量也少。很多狀態信息甚至都可以通過維護人員登錄到主機上面來定時 Check 即可。可如果有上百台主機,仍然僅僅依靠在每台主機上面部署幾個簡單的腳本的方式來進行監控,後期的管理維護成本就會非常高了。
當 MySQL 主機達到一定規模之後,我們基本上很難通過人工到各個主機上面來定時檢查各自的狀態,不論是運行狀態還是性能狀態。甚至都不能像只有少數 MySQL 主機的時候那樣簡單的通過發送郵件的方式將相關信息發出。畢竟,量大了之後,檢查郵件的時間成本也是很大的。這時候就需要我們進行統一的監控信息采集、分析、存儲、處理系統來幫助我們過濾掉可以忽略的正常信息,並畫出相關信息的趨勢圖,以幫助判斷系統的運行狀況和發展趨勢。
所以,MySQL 分布式集群的監控系統整體架構體系應該如下圖所示:
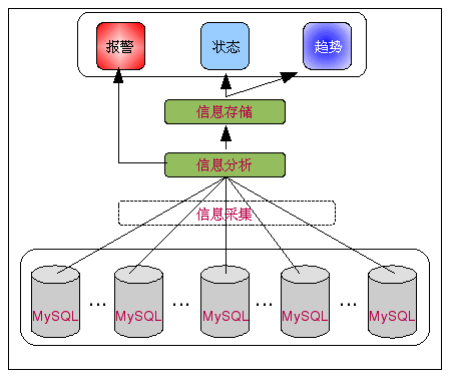
1、信息采集
信息采集可以是一個統一的模塊以主動的方式從各個 MySQL 主機上面來獲取信息然後存放到監控信息存儲中心,也可以是分布在各個 MySQL 主機上面的模塊以被動的方式來反向將相關數據推向監控信息存儲中心。
一般來說,較小規模的監控點可以采用輪詢的方式主動采集數據,但是當監控點達到一定規模以後,輪詢的主動采集方式可能就會遇到一定的性能瓶頸和信息延時問題,尤其是當需要采集的數據比較多的時候尤為突出。而如果要采用從各個 MySQL 節點進行被動的推送,則可能需要開發能夠支持網絡通信的監控程序,使采集的信息能夠順利的到達信息分析模塊以即時得到分析,成本會稍微高一些。
不論是采用主動還是被動的方式來進行數據采集,我們都需要在監控主機上面部署采集相關信息的程序或腳本,包括主機信息和數據庫信息。
2、信息分析
當前端采集模塊的監控程序獲取到 MySQL 主機當前的各種狀態信息之後,分析模塊需要實時地對數據進行分析,識別出系統是正常還是異常,如果是異常,就必須通過相關機制立即發出報警通知,並將信息發送到存儲模塊進行持久化。如果正常,則不需要進行任何處理就可以將數據傳遞到存儲模塊持久化。對信息分析模塊來講,最重要的事情就是處理及時、准確,當監控點到達一定的量之後,性能可能會成為瓶頸。
3、信息存儲
存儲監控程序采集的信息也是一件非常重要的事情,因為不論是查看當前狀態,還是繪制趨勢圖,都需要用到這些信息。此外還有一個非常重要的原因就是通過對積累下來的這些監控信息的分析挖掘,為系統的容量規劃和性能模型設計帶來非常大的幫助。
4、信息處理
最後根據采集到的各種狀態、性能信息,通過應用相應規則進行分析挖掘運算,繪制出各種狀態的趨勢圖以供維護人員查看。此外,通過對各種趨勢的分析,發掘出業務發展與數據庫負載之間的關系,以及與主機硬件的關系。這些關系數據,對於系統發展規劃的制定將是非常有意義的。
18.2 健康狀態監控
健康狀態信息一般來說還是比較簡單的,但也是非常重要的。因為對於監控來說,需要了解的健康狀態基本上也就只有“正常”或“不正常”這兩種。下面分別從主機狀態信息和數據庫狀態信息來分別介紹一下。
18.2.1 主機健康狀態監控
在數據庫運行環境,需要關注的主機狀態主要有網絡通信、系統軟硬件錯誤、磁盤空間、內存使用,進程數量等。
● 網絡通信:網絡通信基本上可以說是最容易檢測的了,基本上只需要通過網絡 ping 就可以獲知是否正常。如果還不放心,或者所屬網段內禁用了 ping,也可以從監控主機進行固定端口的 telnet 嘗試或者 ssh 登錄嘗試。由於網絡出現故障的時候被動的信息采集方式也會失效(無法與外界通信),所以網絡通信的檢測主要還是依靠主動檢測。
● 系統軟硬件錯誤:系統軟硬件錯誤,一般只能通過檢測各種日志文件的信息來實現, 如主機的系統日志中基本上都會記錄下 OS 能夠檢測到的大部分錯誤信息,如硬件錯誤,IO 錯誤等等。我們一般使用文本監控軟件,如 sec、logwatch 等日志監控專用軟件,通過配置相應的匹配規則,從日志文件中捕獲滿足條件的錯誤信息,再發送給信息分析模塊。
● 磁盤空間:對於磁盤空間的使用狀況監控,我們通過最簡單的 shell 腳本就可以輕松搞定,得出系統中各個分區的當前使用量,剩余可用空間。積累一定時間段的信息之後,很容易就能得出系統數據量增長趨勢。
● 內存使用:系統物理內存使用量的信息采集同樣非常簡單,只需要一個基本的系統命令“free”,就可以獲得當前系統內存總量,剩余使用量,以及文件系統的buffer和cache兩者使用量。而且,除了物理內存使用情況,還可以得到 swap 使用量。
通過shell腳本對這些輸出信息進行簡單的處理,即可獲得足夠的信息。當然,如果你希望獲取更多的信息,如當前系統使用內存最多的進程,可能還需要借助其他命令(如:top)才能得到。當然,不同的 OS 在輸出值的處理方面可能會稍有區別,
● 進程數量:系統進程總數,或者某個用戶下的進程數,都可以通過“ps”命令經過
簡單的處理來獲得。如獲取mysql用戶下的進程總數:
ps -ef | awk '{print $1}' | grep "mysql" | grep -v "grep" | wc -l
如要獲得更為詳細的某個或者某類進程的信息,同樣可以根據上述類似命令得到。
18.2.2 數據庫健康狀態信息
除了主機的狀態信息之外,MySQL Server 自身也有很多的狀態信息需要監控。下面就詳細介紹一下 MySQL Server 需要監控的內容以及監控方法。
● 服務端口(3306):MySQL 端口是一個必不可少的監控項,因為這直接反應了 MySQL Server 是否能夠正常為外部請求提供服務。有些時候從主機層面來檢查 MySQL 可能很正常,可外部應用卻無法通過 TCP/IP 連接上 MySQL。產生這種現象的原因可能有多種,如網絡防火牆的問題,網絡連接問題,MySQL Server 所在主機的網絡設置問題,以及 MySQL 本身問題都可能造成上述現象。
服務端口狀態的監控和主機網絡連接的監控同樣非常簡單,只需要對 3306 端口進行 telnet 嘗試即可。通過對 3306 端口的 telnet 嘗試,同時還可以完成對主機網絡狀況的監控。
● socket文件:對於有些環境來說,socket 的狀態監控可能並不如網絡服務端口的監控重要,因為很多 MySQL Server 的連接並不會通過本地 socket 進行連接。但是也有不少小型應用(或者某些特殊的應用)還是和 MySQL 數據庫處於同一台主機上,並通過本地 socket 連接。另外,不少本地被動監控的信息采集腳本也是通過本地 socket 來連接 MySQL Server。
本地 socket 的監控最好是通過本地 socket 的實際連接嘗試的方式,雖然也可以通過檢測 socket 文件是否存在來監控,但是即使 socket 文件確實存在,也並不一定就可以確保能夠通過 socket 正常登錄。畢竟,在某些異常情況下,socket 文件存在並不代表就可以正常使用。
● mysqld 和 mysqld_safe 進程:mysqld 進程是 MySQL Server最核心的進程。
mysqld 進程 crash 或者出現異常,MySQL Server 基本上也就無法正常提供服務了。當然,如果我們是通過 mysqld_safe 來啟動 MySQL Server,則 mysqld_safe 會幫助我們來監控 mysqld 進程的狀態,當 mysqld 進程crash 之後,mysqld_safe 會馬上幫助我們重啟 mysqld 進程。但前提是我們必須通過mysqld_safe 來啟動 MySQL Server,這也是 MySQL AB 強烈推薦的做法。如果我們通過 mysqld_safe 來啟動 MySQL Server,那麼我們也必須對 mysqld_safe 進程進行監控。
無論是 mysqld 還是 mysqld_safe 進程的監控,都可以通過 ps 命令來得到實現:
ps -ef | grep "mysqld_safe" | grep -v "grep" 和 ps -ef | grep "mysqld" | grep -v "mysqld_safe"| grep -v "grep"
● Error log:Error log 的監控目的主要是即時檢測 MySQL Server 運行過程中發生的各種錯誤,如連接異常,系統bug等。
Error log 的監控和系統軟硬件狀態的監控一樣,都是通過對文本文件內容的監控來實現的。同樣使用文本監控軟件,通過配置各種錯誤信息的匹配規則來捕獲日志文件中的錯誤信息。
● 復制狀態:如果我們的 MySQL 數據庫環境使用了 MySQL Replication,就必須增加對 Slave 復制狀態的監控。對Slave 的復制狀態的監控包括對 IO 線程和 SQL線程二者的運行狀態的監控。當然,如果希望能夠監控 Replication 更多的信息, 如兩個線程各自運行的進度等,同樣可以在 Slave 節點上執行相應命令輕松得到, 如下:
sky@localhost : (none) 04:30:38> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Connecting to master
Master_Host: 10.0.77.10
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 196
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB: example,abc
Replicate_Ignore_DB: mysql,test
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 196
Relay_Log_Space: 106
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
通過如上命令,我們可以獲取獲取關於 Replication 的各種信息,不論是復制的監控狀況,還是復制的進度,都可以很容易的獲取。上面輸出的各項內容中,最重要的內容就是 Slave_IO_Running 和 Slave_SQL_Running 這兩項,分別代表了 IO線程和 SQL 線程的運行狀態,如上面的輸出就表明 SQL 線程運行正常,但是 IO線程並沒有運行。其他各項的詳細解釋,請參考本書附錄。
18.3 性能狀態監控
性能狀態的監控和健康狀態的監控有一定的區別,他所反應出來的主要是系統當前提供服務的響應速度,影響的更多是客戶滿意度。性能狀態的持續惡化,則可能升級為系統不可用,也就是升級為健康狀態的異常。如系統的過度負載,可能導致系統的 crash。性能狀態的監控同樣可以分為主機和數據庫層面。
18.3.1 主機性能狀態
主機性能狀態主要表現在三個方面:CPU、IO以及網絡,可以通過以下五個監控量來監控。
● 系統 load值:系統 load 所包含的最關鍵含義是 CPU 運行等待的數量,也就是側面反應了 CPU 的繁忙程度。只不過 load 值並不直接等於等待隊列中的進程數量。
load 值的監控也非常簡單,通過運行 uptime 命令即可獲得當前時間之前1秒、5秒和15秒的 load 平均值。
sky@sky:~$ uptime 17:27:44 up 4:12, 3 users, load average: 0.87, 0.66, 0.61
如上面輸出內容中的“load average: 0.87, 0.66, 0.61”中的三個數字,分別代表了1秒、5秒和15秒的load平均值。
一般來說,load值在不超過系統物理 cpu數目(或者cpu總核數)之前,系統不會有太大問題。
● CPU 使用率:CPU 使用率和系統 load 值一樣,從另一個角度反應出 CPU 的總體繁忙程度,只不過可以反應出更為詳細的信息,如當前空閒 的CPU 比率,系統占用的 CPU比率,用戶進程占用的 CPU 比率,處於 IO 等待的 CPU 比率等。
CPU 使用率可以通過多種方法來獲取,最為常用的方法是使用命令 top 和 vmstat來獲取 。當然,不同的 OS 系統上的 top 和 vmstat 的輸出可能有些許不同,且輸出格式也可能各不一樣,如 Linux 下的 top 包含 IO 等待的 CPU 占用律,但是 Solaris 下的 top 就不包含,各位讀者朋友請根據自己的 OS 環境進行相應的處理。
● 磁盤 IO 量:磁盤 IO 量直接反應出了系統磁盤繁忙程度,對於數據庫這種以 IO操作為主的系統來說,IO 的負載將直接影響到系統的整體響應速度。
磁盤 IO 量同樣也可以通過 vmstat 來獲取,當然,我們還可以通過iostat 來獲得更為詳細的系統 IO 信息。包括各個磁盤設備的 iops,每秒吞吐量等。
● swap 進出量:swap 的使用主要表現了系統在物理內存不夠的情況下使用虛擬內存的情況。當然,有些時候即使系統還有足夠物理內存的時候,也可能出現使用 swap的情況,這主要是由系統內核中的內存管理部分來決定。如果希望系統完全不使用swap,最直接的辦法就是關閉 swap。當然,前提條件是我們必須要有足夠的物理內存,否則很可能會出現內存不足的錯誤,嚴重的時候可能會造成系統 crash。
swap 使用量的總體情況可以通過 free 命令獲得,但 free 命令只能獲得當前系統 swap 的總體使用量。如果希望獲得實時的 swap 使用變化,還是得依賴 vmstat來得到。vmstat 輸出信息中包含了每秒 swap 的進出量,當然,不同的 OS 輸出可能存在一定的差異。
● 網絡流量:作為數據庫系統,網絡流量也是一個不容忽視的監控點。畢竟數據庫系統的數據進出比普通服務器的量還是要大很多的。不論是總體吞吐量還是網絡iops,都需要給予一定的關注。當然,一般非數據倉庫類型的數據庫,網絡流量成為瓶頸的可能性還是比較小的。
網絡流量的監控很少有系統自帶的命令可以直接完成,而需要自行編寫腳本或者通過一些第三方軟件來獲取數據。當然,通過對網絡交換機的監控,也可以獲得非常詳細的網絡流量信息。自行編寫腳本可以通過調用 ifconfig 命令來計算出基本准確的網絡流量信息。第三方軟件如 ifstat、iftop和nload 等則是需要另外安裝的監控 linux 下網絡流量第三方軟件,三者各有特點,讀者朋友可以根據三款軟件官方介紹的功能特點自行選擇。
18.3.2 數據庫性能狀態
MySQL 數據庫的性能狀態監控點非常之多,其中很多量都是我們不能忽視的必須監控的量,且 90% 以上的內容可以在連接上 MySQL Server 後執行“SHOW /*!50000 GLOBAL */ STATUS” 以及 “SHOW /*!50000 GLOBAL */ VARIABLES” 的輸出值獲得。需要注意的是上述命令所獲得狀態值實際上是累計值,所以如果要計算(單位/某個)時間段內的變化量還需要稍加處理,可以在附錄中找到兩個命令輸出值的詳細說明。下面看看幾項需要重點關注的性能狀態:
● QPS(每秒Query 量):這裡的 QPS 實際上是指 MySQL Server 每秒執行的 Query 總量,在 MySQL 5.1.30 及以下版本可以通過 Questions 狀態值每秒內的變化量來近似表示,而從 MySQL 5.1.31 開始,則可以通過 Queries 來表示。Queries 是在 MySQL 5.1.31 才新增的狀態變量。主要解決的問題就是 Questions 狀態變量並沒有記錄存儲過程中所執行的 Query(當然,在無存儲過程的老版本 MySQL 中則不存在這個區別),而 Queries 狀態變量則會記錄。二者獲取方式:
QPS = Questions(or Queries) / Seconds
獲取所需狀態變量值:
SHOW /*!50000 GLOBAL */ STATUS LIKE 'Questions'
SHOW /*!50000 GLOBAL */ STATUS LIKE 'Queries'
這裡的 Seconds 是指累計出上述兩個狀態變量值的時間長度,後面用到的地方也代表同樣的意思。
● TPS(每秒事務量): 在 MySQL Server 中並沒有直接事務計數器,我們只能通過回滾和提交計數器來計算出系統的事務量。所以,我們需要通過以下方式來得到客戶端應用程序所請求的 TPS 值:
TPS = (Com_commit + Com_rollback) / Seconds
如果我們還使用了分布式事務,那麼還需要將 Com_xa_commit 和Com_xa_rollback 兩個狀態變量的值加上。
● Key Buffer 命中率:Key Buffer 命中率代表了 MyISAM 類型表的索引的 Cache 命中率。該命中率的大小將直接影響 MyISAM 類型表的讀寫性能。Key Buffer 命中率實際上包括讀命中率和寫命中率兩種,MySQL 中並沒有直接給出這兩個命中率的值,但是可以通過如下方式計算出來:
key_buffer_read_hits = (1 - Key_reads / Key_read_requests) * 100%
key_buffer_write_hits= (1 - Key_writes / Key_write_requests) * 100%
獲取所需狀態變量值:
sky@localhost : (none) 07:44:10> SHOW /*!50000 GLOBAL */ STATUS
-> LIKE 'Key%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
... ...
| Key_read_requests | 10 |
| Key_reads | 4 |
| Key_write_requests | 0 |
| Key_writes | 0 |
+------------------------+-------+
通過這兩個計算公式,我們很容易就可以得出系統當前 Key Buffer 的使用情況
● Innodb Buffer 命中率:這裡 Innodb Buffer 所指的是innodb_buffer_pool,也就是用來緩存 Innodb類型表的數據和索引的內存空間。類似 Key buffer,我們同樣可以根據 MySQL Server 提供的相應狀態值計算出其命中率:
innodb_buffer_read_hits=(1- Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests)* 100%
獲取所需狀態變量值:
sky@localhost : (none) 08:25:14> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Innodb_buffer_pool_read%';
+-----------------------------------+-------+
| Variable_name | Value |
+-----------------------------------+-------+
... ...
| Innodb_buffer_pool_read_requests | 5367 |
| Innodb_buffer_pool_reads | 507 |
+-----------------------------------+-------+
● Query Cache 命中率:如果我們使用了 Query Cache,那麼對 Query Cache 命中率進行監控也是有必要的,因為他可能告訴我們是否在正確的使用Query Cache。
Query Cache 命中率的計算方式如下:
Query_cache_hits= (Qcache_hits / (Qcache_hits + Qcache_inserts)) * 100%
獲取所需狀態變量值:
sky@localhost : (none) 08:32:01> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Qcache%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
... ...
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
... ...
+-------------------------+-------+
● Table Cache 狀態量:Table Cache 的當前狀態量可以幫助我們判斷系統參數table_open_cache 的設置是否合理。如果狀態變量 Open_tables 與Opened_tables 之間的比率過低,則代表 Table Cache 設置過小,個人認為該值處於 80% 左右比較合適。注意,這個值並不是准確的 Table Cache 命中率。
獲取所需狀態變量值:
sky@localhost : (none) 08:52:00> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Open%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
... ...
| Open_tables | 51 |
... ...
| Opened_tables | 61 |
+--------------------------+-------+
● Thread Cache 命中率:Thread Cache 命中率能夠直接反應出我們的系統參數thread_cache_size 設置的是否合理。一個合理的 thread_cache_size 參數能夠節約大量創建新連接時所需要消耗的資源。Thread Cache 命中率計算方式如下:
Thread_cache_hits = (1 - Threads_created / Connections) * 100%
獲取所需狀態變量值:
sky@localhost : (none) 08:57:16> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Thread%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
... ...
| Threads_created | 3 |
... ...
+-------------------+-------+
4 rows in set (0.01 sec)
sky@localhost : (none) 09:01:33> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Connections';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Connections | 11 |
+---------------+-------+
正常來說,Thread Cache 命中率要在 90% 以上才算比較合理。
● 鎖定狀態:鎖定狀態包括表鎖和行鎖兩種,我們可以通過系統狀態變量獲得鎖定總次數,鎖定造成其他線程等待的次數,以及鎖定等待時間信息。
sky@localhost : (none) 09:01:44> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE '%lock%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
... ...
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
| Innodb_row_lock_waits | 0 |
... ...
| Table_locks_immediate | 44 |
| Table_locks_waited | 0 |
+-------------------------------+-------+
通過上述系統變量,我們可以得出表鎖總次數,其中造成其他現線程等待的次數。同時還可以得到非常詳細的行鎖信息,如行鎖總次數,行鎖總時間,每次行鎖等待時間,行鎖造成最大等待時間以及當前等待行鎖的線程數。通過對這些量的監控,我們可以清晰的了解到系統整體的鎖定是否嚴重。如當 Table_locks_waited 與 Table_locks_immediate 的比值較大,則說明我們的表鎖造成的阻塞比較嚴重,可能需要調整 Query語句,或者更改存儲引擎,亦或者需要調整業務邏輯。當然,具體改善方式必須根據實際場景來判斷。而 Innodb_row_lock_waits 較大,則說明 Innodb 的行鎖也比較嚴重,且影響了其他線程的正常處理。同樣需要查找出原因並解決。造成 Innodb 行鎖嚴重的原因可能是 Query 語句所利用的索引不夠合理(Innodb 行鎖是基於索引來鎖定的),造成間隙鎖過大。也可能是系統本身處理能力有限,則需要從其他方面(如硬件設備)來考慮解決。
● 復制延時量:復制延時量將直接影響了 Slave 數據庫處於不一致狀態的時間長短。
如果我們是通過 Slave 來提供讀服務,就不得不重視這個延時量。我們可以通過在 Slave 節點上執行“SHOW SLAVE STATUS”命令,取 Seconds_Behind_Master 項的值來了解 Slave 當前的延時量(單位:秒)。當然,該值的准確性依賴於復制是否處於正常狀態。每個環境下的 Slave 所允許的延時長短與具體環境有關,所以復制延時多長時間是合理的,只能由讀者朋友根據各自實際的應用環境來判斷。
● Tmp table 狀況:Tmp Table 的狀況主要是用於監控 MySQL 使用臨時表的量是否過多,是否有臨時表過大而不得不從內存中換出到磁盤文件上。臨時表使用狀態信息可以通過如下方式獲得:
sky@localhost : (none) 09:27:28> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Created_tmp%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 1 |
... ...
| Created_tmp_tables | 46 |
+-------------------------+-------+
從上面的狀態信息可以了解到系統使用了46次臨時表,其中有1次臨時表比較大, 無法在內存中完成,而不得不使用到磁盤文件。如果 Created_tmp_tables 非常大,則可能是系統中排序操作過多,或者是表連接方式不是很優化。而如果是Created_tmp_disk_tables 與 Created_tmp_tables 的比率過高,如超過 10%,則我們需要考慮是否 tmp_table_size 這個系統參數所設置的足夠大。當然,如果系統內存有限,也就沒有太多好的解決辦法了。
● Binlog Cache 使用狀況:Binlog Cache 用於存放還未寫入磁盤的 Binlog 信息。
相關狀態變量如下:
sky@localhost : (none) 09:40:38> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Binlog_cache%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Binlog_cache_disk_use | 0 |
| Binlog_cache_use | 0 |
+-----------------------+-------+
如果 Binlog_cache_disk_use 值不為0,則說明 Binlog Cache 大小可能不夠, 建議增加 binlog_cache_size 系統參數大小。
● Innodb_log_waits 量:Innodb_log_waits 狀態變量直接反應出 Innodb Log Buffer 空間不足造成等待的次數。
sky@localhost : (none) 09:43:53> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE 'Innodb_log_waits';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_log_waits | 0 |
+------------------+-------+
該變量值發生的頻率將直接影響系統的寫入性能,所以當該值達到每秒1次時就該增加 系統參數innodb_log_buffer_size的值,畢竟這是一個系統共用的緩存,適當增加並不會造成內存不足的問題。
上面這些監控量只是我個人認為比較重要的一些 MySQL 性能監控量,各位讀者朋友還可以根據各自的需要,通過 MySQL 所提供的系統狀態變量增加其他監控內容。
18.4 常用開源監控軟件
前面已經介紹過了監控系統的設計思路,也分析了我們需要關注的部分健康狀態和性能狀態監控點,這一節再介紹幾種常用的第三方監控軟件,為大家提供一點搭建監控系統的思路。當然,推薦原則仍然是以開源(或免費)產品為主。當然,前提是我們暫時沒有自行開發一套監控系統的打算,而希望通過一些開源的軟件工具來實現。
在介紹監控軟件之前,有一個軟件是我不得不提的:RRDTool。RRDTool全稱為 Round
Robin Database Tool,也就是環狀循環數據庫工具,在多種監控軟件中充當非常重要的數據存儲角色。所謂環狀循環數據庫,就是數據的存儲方式類似於在一個環形空間中,沒有確切的起始位置和結束位置。當寫完一圈之後,新的數據會覆蓋老數據。當然,由於環狀循環數據庫所存放的數據大多都是存放用於統計方面的數據,而且可以通過一些加和平均之類的統計算法通過老數據得出相應的統計結果。當老數據需要被覆蓋的時候,他早已失去實際價
值了。所以,RRDTool 在很多監控工具中都被用來存放各種性能數據,然後根據這些數據畫出相應的趨勢圖,以及不同時間段內的平均值曲線。如果有哪位讀者朋友有興趣自行開發一個監控工具,RRDTool 同樣可以作為您用來存放相關數據非常合適的選擇。不過,這裡有一點需要注意的是他只能存放數字。
1、Nagios
Nagois 是一個非常著名的運行在 Linux/Unix 上的對IT設備或服務的運行狀態進行監控的軟件。實際上,我個人覺得稱其為一個監控平台可能更為合適,因為它不僅僅自帶了豐富的監控工具,同時還支持用戶自己編寫各種各樣的監控腳本以插件形式嵌入其中。
Nagios 自帶的監控功能不僅包含與主機資源相關的 CPU 負載,磁盤使用等,還包括了網絡相關的服務,如SMTP、POP3、HTTP、NNTP、PING 等。當然,Nagios 流行的另外一個重要原因是其簡單的插件設計允許用戶可以非擦方便地開發自己需要的服務檢查。
對於大多數的監控場景來說,Nagios 的現有功能都能夠滿足。不論是主動檢測,還是被動監控,都可以很好的實現。對於不同重要級別的監控點,可以分別設置不同的數據采集頻率。對於異常的處理,可以設定為郵件、Web以及其他自定義的異常通知機制(如手機短信或者 IM 工具通知)。不僅如此,Nagios 還可以設置報警前的異常出現次數,如連續多少次訪問超時之後再發出警告信息。而當我們需要進行正常維護的時候,還可以通過設置一個暫時忽略異常的 DownTime 時間段。
Nagios 分為客戶端與服務器端兩部分,客戶端實際上就是大量的 Nagios 監控插件,負責采集監控點的各種數據,而服務器端則是配置管理、數據分析、告警發送、用戶自助管理以及相關信息展示等功能。服務器端的Web展示界面的功能也非常強大,可以非常准且的展示出當前各個監控點的狀態,上一次檢測時間等信息。同時還能根據監控點追溯一定的歷史記錄信息。
當然,Nagios 也有一個缺點,那就是目前他僅僅支持健康狀態數據的采集分析,而不支持通過采集性能數據來繪制性能趨勢曲線圖。當然,這可以結合其他的軟件工具共同完成這一工作。
如需更為詳細的 Nagios 的搭建使用手冊,請各位讀者朋友前往其官方網站獲取更為權威的信息:http://www.nagios.org/docs
2、MRTG
MRTG 應該算是一款比較老牌的監控軟件了,功能比較簡單,最初是為了監控網絡鏈路流量而產生的。但是經過原開發者的不斷改造,以及網友們的集體智慧,其應用場景已經遠遠超出了網絡鏈路流量監控。
MRTG 的實現原理其實很簡單,他通過 snmp 協議,調用監控設備上面相應的腳本,獲取需要的返回值,然後通過 RRDTool 保存起來。然後再通過 RRDTool 將保存的數據進行相應的統計平均計算,最後畫成圖片,通過 html 的形式展現給前端浏覽者。
對於 MRTG 來說,它不需要知道我們監控的到底是什麼數據,只需要告訴他到底什麼時候該調用什麼腳本來取得監控返回值,同時配置好存放位置,即可完成一個監控項的監控配置。對於我們來說,最為重要的是寫好取得監控值的腳本,設定好 MRTG 的采集頻率,然後就是查看各種監控數據的曲線圖了。
更為詳細的 MRTG 使用及搭建方法,請至官方網站(http://oss.oetiker.ch/mrtg) 上查找相應文檔。
3、 Cacti
Cacti 和 Nagios 最大的區別在於前者具有非常強大的數據采集、存儲以及展現功能, 但在告警管理這一塊稍弱於後者。其開發語言是PHP,配置存儲在 MySQL 數據庫中,數據采集同樣利用了 SNMP 協議,采集數據的存儲則利用了本節最前面介紹的 RRDTool。
在數據的繪圖展現方面,相對於其他有些監控軟件來說,也有一定的優勢,如單個圖上面可以有無限多個數據項共存,而不像 MRTG 每張圖片上只能有兩個數據項的曲線。
除了非常強大的數據灰土展現功能之外,Cacti另外一個比較有吸引力的功能就是可以通過用戶管理,設定多種權限角色,讓更多的用戶自行定義維護各自的監控配置項。這個特性對於監控設備(或服務)涉及到多個部門的很多人的應用場景下,是非常有用的。
當然,除了上面的這幾個比較有特點特性之外,Cacti 還存在很多很多其他的特性。大家可以從Cacti官方文檔獲得更詳細的信息:http://www.cacti.net/documentation.php。
不同的監控需求,可以采用不同的監控軟件來實現,如我個人的很多環境就同時使用了Nagios 來實現健康狀況的監控和告警。而性能數據的采集與繪圖則利用了MRTG和 RRDTool來實現。各位讀者朋友完全可以根據自己的需求來決定如何搭建一個更為合適的監控系統,來幫助大家更進一步提高系統的可用性。
18.4 小結
系統的監控在很多環境中都沒有得到足夠的重視,可其實際意義卻非常大。雖然監控系統本身並不能讓系統運行的更好,卻能夠給在系統出現問題之後的第一時間通知我們,縮短了發現問題的時間,也間接提高了系統的可用性。甚至可以根據監控所收集的各種性能數據,讓我們提前發現系統的性能問題,防范於未然。本章通過對 MySQL 數據庫環境的健康狀態、性能狀態以及相應的監控方式的分析,完成了搭建一個高可用數據庫環境的最後一步,希望能夠對各位讀者朋友有一點幫助。
摘自:《MySQL性能調優與架構設計》簡朝陽
轉載請注明出處:
作者:JesseLZJ
出處:http://jesselzj.cnblogs.com