一、配置文件說明
my-small.cnf
my-medium.cnf
my-large.cnf
my-huge.cnf
my-innodb-heavy-4G.cnf
二、詳解 my-innodb-heavy-4G.cnf
三、配置文件優化
注:環境說明,CentO5.5 x86_64+MySQL-5.5.32 相關軟件下載:http://yunpan.cn/QtaCuLHLRKzRq
一、配置文件說明
Mysql-5.5.49是Mysql5.5系列中最後一個版本,也是最後一個有配置文件的版本,為什麼這麼說呢,用過5.6的博友都知道,在mysql5.6中已經不提供配置文件選擇,只有一個默認的配置文件,好了,我們今天說的是5.5.49這個版,就不和大家說5.6了,下面我們來具體說一下,mysql5.5.49中,提供可選的幾個配置文件,
my-small.cnf
my-medium.cnf
my-large.cnf
my-huge.cnf
my-innodb-heavy-4G.cnf
下面我們就來分別的看一下^_^……
1.my-small.cnf
[root@mysql support-files]# vim my-small.cnf # Example MySQL config file for small systems. # This is for a system with little memory (<= 64M) where MySQL is only used # from time to time and it's important that the mysqld daemon # doesn't use much resources.
這是my-small.cnf配置文件中開頭的簡介,它說明了,這個配置文件是在內存小於等於64M時使用的,小型數據庫系統,目的是不占更多的系統資源!
2.my-medium.cnf
[root@mysql support-files]# vim my-medium.cnf # Example MySQL config file for medium systems. # This is for a system with little memory (32M - 64M) where MySQL plays # an important part, or systems up to 128M where MySQL is used together with # other programs (such as a web server)
這個配置文件是中型數據系統使用,內存在128M左右!
3.my-large.cnf
[root@mysql support-files]# vim my-large.cnf # Example MySQL config file for large systems. # This is for a large system with memory = 512M where the system runs mainly # MySQL.
這個配置文件是大型數據庫系統使用,內存在512M左右!
4.my-huge.cnf
[root@mysql support-files]# vim my-huge.cnf # Example MySQL config file for very large systems. # This is for a large system with memory of 1G-2G where the system runs mainly # MySQL.
這個配置文件是巨型數據庫系統使用,內存在1G-2G左右!
5.my-innodb-heavy-4G.cnf
[root@mysql support-files]# vim my-innodb-heavy-4G.cnf #BEGIN CONFIG INFO #DESCR: 4GB RAM, InnoDB only, ACID, few connections, heavy queries #TYPE: SYSTEM #END CONFIG INFO # This is a MySQL example config file for systems with 4GB of memory # running mostly MySQL using InnoDB only tables and performing complex # queries with few connections.
這個配置文件主要作用是,支持4G內存,支持InnoDB引擎,支持事務(ACID)等特性所使用!
說明:ACID,指數據庫事務正確執行的四個基本要素的縮寫。包含:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、持久性(Durability)!
6.總結
從上面的說明我們可以出,基本是通過內存大小來選擇mysql的配置文件的,那有博友會說了,現在的服務器動不動就是32G內存或者64G內存,甚至更大的內存,你那個配置文件最大只支持4G內存是不是有點小了,確認會有這樣的問題,從mysql5.6以後,為了更大的發揮mysql的性能,已經去除了配置文件選擇,只有一個默認的配置文件,裡面只有一些基本配置,所有設置管理員都可以根據自己實際的需求進行自行設置,好了說了這麼多,我們就來說一說,在企業的用的最多的my-innodb-heavy-4G.cnf配置文件!
二、詳解 my-innodb-heavy-4G.cnf
1.詳細說明
注:下面是my-innodb-heavy-4G.cnf默認配置我沒有做任何修改,下面我們就來詳細的說一說!
[root@mysql support-files]# vim my-innodb-heavy-4G.cnf
#BEGIN CONFIG INFO
#DESCR: 4GB RAM, InnoDB only, ACID, few connections, heavy queries
#TYPE: SYSTEM
#END CONFIG INFO
#
# This is a MySQL example config file for systems with 4GB of memory
# running mostly MySQL using InnoDB only tables and performing complex
# queries with few connections.
#
# MySQL programs look for option files in a set of
# locations which depend on the deployment platform.
# You can copy this option file to one of those
# locations. For information about these locations, see:
# http://dev.mysql.com/doc/mysql/en/option-files.html
#
# In this file, you can use all long options that a program supports.
# If you want to know which options a program supports, run the program
# with the "--help" option.
#
# More detailed information about the individual options can also be
# found in the manual.
#
#
# The following options will be read by MySQL client applications.
# Note that only client applications shipped by MySQL are guaranteed
# to read this section. If you want your own MySQL client program to
# honor these values, you need to specify it as an option during the
# MySQL client library initialization.
#
# 以下選項會被MySQL客戶端應用讀取, 注意只有MySQL附帶的客戶端應用程序保證可以讀取這段內容,如果你想你自己的MySQL應用程序獲取這些值,需要在MySQL客戶端庫初始化的時候指定這些選項
[client]
#password = [your_password] #mysql客戶端連接mysql時的密碼
port = 3306 #mysql客戶端連接時的默認端口
socket = /tmp/mysql.sock #與mysql服務器本地通信所使用的socket文件路徑
# *** Application-specific options follow here ***
#
# The MySQL server
#
[mysqld]
# generic configuration options #一般配置選項
port = 3306 #mysql服務器監聽的默認端口
socket = /tmp/mysql.sock #socket本地通信文件路徑
# back_log is the number of connections the operating system can keep in
# the listen queue, before the MySQL connection manager thread has
# processed them. If you have a very high connection rate and experience
# "connection refused" errors, you might need to increase this value.
# Check your OS documentation for the maximum value of this parameter.
# Attempting to set back_log higher than your operating system limit
# will have no effect.
# back_log 是操作系統在監聽隊列中所能保持的連接數,
# 隊列保存了在MySQL連接管理器線程處理之前的連接.
# 如果你有非常高的連接率並且出現“connection refused”報錯,
# 你就應該增加此處的值.
# 檢查你的操作系統能打開文件數來獲取這個變量的最大值.
# 如果將back_log設定到比你操作系統限制更高的值,將會沒有效果
back_log = 50
# Don't listen on a TCP/IP port at all. This can be a security
# enhancement, if all processes that need to connect to mysqld run
# on the same host. All interaction with mysqld must be made via Unix
# sockets or named pipes.
# Note that using this option without enabling named pipes on Windows
# (via the "enable-named-pipe" option) will render mysqld useless!
# 不在TCP/IP端口上進行監聽.
# 如果所有的進程都是在同一台服務器連接到本地的mysqld,
# 這樣設置將是增強安全的方法
# 所有mysqld的連接都是通過Unix sockets 或者命名管道進行的.
# 注意在windows下如果沒有打開命名管道選項而只是用此項
# (通過 “enable-named-pipe” 選項) 將會導致mysql服務沒有任何作用!
#skip-networking #默認是沒有開啟的
# The maximum amount of concurrent sessions the MySQL server will
# allow. One of these connections will be reserved for a user with
# SUPER privileges to allow the administrator to login even if the
# connection limit has been reached.
# MySQL 服務器所允許的同時會話數的上限
# 其中一個連接將被SUPER權限保留作為管理員登錄.
# 即便已經達到了連接數的上限.
max_connections = 100
# Maximum amount of errors allowed per host. If this limit is reached,
# the host will be blocked from connecting to the MySQL server until
# "FLUSH HOSTS" has been run or the server was restarted. Invalid
# passwords and other errors during the connect phase result in
# increasing this value. See the "Aborted_connects" status variable for
# global counter.
# 每個客戶端連接最大的錯誤允許數量,如果達到了此限制.
# 這個客戶端將會被MySQL服務阻止直到執行了”FLUSH HOSTS” 或者服務重啟
# 非法的密碼以及其他在鏈接時的錯誤會增加此值.
# 查看 “Aborted_connects” 狀態來獲取全局計數器.
max_connect_errors = 10
# The number of open tables for all threads. Increasing this value
# increases the number of file descriptors that mysqld requires.
# Therefore you have to make sure to set the amount of open files
# allowed to at least 4096 in the variable "open-files-limit" in
# section [mysqld_safe]
# 所有線程所打開表的數量.
# 增加此值就增加了mysqld所需要的文件描述符的數量
# 這樣你需要確認在[mysqld_safe]中 “open-files-limit” 變量設置打開文件數量允許至少2048
table_open_cache = 2048
# Enable external file level locking. Enabled file locking will have a
# negative impact on performance, so only use it in case you have
# multiple database instances running on the same files (note some
# restrictions still apply!) or if you use other software relying on
# locking MyISAM tables on file level.
# 允許外部文件級別的鎖. 打開文件鎖會對性能造成負面影響
# 所以只有在你在同樣的文件上運行多個數據庫實例時才使用此選項(注意仍會有其他約束!)
# 或者你在文件層面上使用了其他一些軟件依賴來鎖定MyISAM表
#external-locking #默認是沒有開啟的
# The maximum size of a query packet the server can handle as well as
# maximum query size server can process (Important when working with
# large BLOBs). enlarged dynamically, for each connection.
# 服務所能處理的請求包的最大大小以及服務所能處理的最大的請求大小(當與大的BLOB字段一起工作時相當必要)
# 每個連接獨立的大小.大小動態增加
max_allowed_packet = 16M
# The size of the cache to hold the SQL statements for the binary log
# during a transaction. If you often use big, multi-statement
# transactions you can increase this value to get more performance. All
# statements from transactions are buffered in the binary log cache and
# are being written to the binary log at once after the COMMIT. If the
# transaction is larger than this value, temporary file on disk is used
# instead. This buffer is allocated per connection on first update
# statement in transaction
# 在一個事務中binlog為了記錄SQL狀態所持有的cache大小
# 如果你經常使用大的,多聲明的事務,你可以增加此值來獲取更大的性能.
# 所有從事務來的狀態都將被緩沖在binlog緩沖中然後在提交後一次性寫入到binlog中
# 如果事務比此值大, 會使用磁盤上的臨時文件來替代.
# 此緩沖在每個連接的事務第一次更新狀態時被創建
binlog_cache_size = 1M
# Maximum allowed size for a single HEAP (in memory) table. This option
# is a protection against the accidential creation of a very large HEAP
# table which could otherwise use up all memory resources.
# 獨立的內存表所允許的最大容量.
# 此選項為了防止意外創建一個超大的內存表導致永盡所有的內存資源.
max_heap_table_size = 64M
# Size of the buffer used for doing full table scans.
# Allocated per thread, if a full scan is needed.
#MySql讀入緩沖區大小。對表進行順序掃描的請求將分配一個讀入緩沖區,MySql會為它分#配一段內存緩沖區。read_buffer_size變量控制這一緩沖區的大小。如果對表的順序掃描請求非常頻繁,#並且你認為頻繁掃描進行得太慢,可以通過增加該變量值以及內存緩沖區大小提高其性能。
read_buffer_size = 2M
# When reading rows in sorted order after a sort, the rows are read
# through this buffer to avoid disk seeks. You can improve ORDER BY
# performance a lot, if set this to a high value.
# Allocated per thread, when needed.
#是MySql的隨機讀緩沖區大小。當按任意順序讀取行時(例如,按照排序順序),將分配一個隨機讀緩存區。進行排序查詢時,MySql會首先掃描一遍該緩沖,以避免磁盤搜索,提高查詢速度,如果需#要排序大量數據,可適當調高該值。但MySql會為每個客戶連接發放該緩沖空間,所以應盡量適當設置該值,以避免內存開銷過大。
read_rnd_buffer_size = 16M
# Sort buffer is used to perform sorts for some ORDER BY and GROUP BY
# queries. If sorted data does not fit into the sort buffer, a disk
# based merge sort is used instead - See the "Sort_merge_passes"
# status variable. Allocated per thread if sort is needed.
# 排序緩沖被用來處理類似ORDER BY以及GROUP BY隊列所引起的排序
# 如果排序後的數據無法放入排序緩沖,
# 一個用來替代的基於磁盤的合並分類會被使用
# 查看 “Sort_merge_passes” 狀態變量.
# 在排序發生時由每個線程分配
sort_buffer_size = 8M
# This buffer is used for the optimization of full JOINs (JOINs without
# indexes). Such JOINs are very bad for performance in most cases
# anyway, but setting this variable to a large value reduces the
# performance impact. See the "Select_full_join" status variable for a
# count of full JOINs. Allocated per thread if full join is found
# 此緩沖被使用來優化全聯合(full JOINs 不帶索引的聯合).
# 類似的聯合在極大多數情況下有非常糟糕的性能表現,
# 但是將此值設大能夠減輕性能影響.
# 通過 “Select_full_join” 狀態變量查看全聯合的數量
# 當全聯合發生時,在每個線程中分配
join_buffer_size = 8M
# How many threads we should keep in a cache for reuse. When a client
# disconnects, the client's threads are put in the cache if there aren't
# more than thread_cache_size threads from before. This greatly reduces
# the amount of thread creations needed if you have a lot of new
# connections. (Normally this doesn't give a notable performance
# improvement if you have a good thread implementation.)
# 我們在cache中保留多少線程用於重用
# 當一個客戶端斷開連接後,如果cache中的線程還少於thread_cache_size,
# 則客戶端線程被放入cache中.
# 這可以在你需要大量新連接的時候極大的減少線程創建的開銷
# (一般來說如果你有好的線程模型的話,這不會有明顯的性能提升.)
thread_cache_size = 8
# This permits the application to give the threads system a hint for the
# desired number of threads that should be run at the same time. This
# value only makes sense on systems that support the thread_concurrency()
# function call (Sun Solaris, for example).
# You should try [number of CPUs]*(2..4) for thread_concurrency
# 此允許應用程序給予線程系統一個提示在同一時間給予渴望被運行的線程的數量.
# 此值只對於支持 thread_concurrency() 函數的系統有意義( 例如Sun Solaris).
# 你可可以嘗試使用 [CPU數量]*(2..4) 來作為thread_concurrency的值
thread_concurrency = 8
# Query cache is used to cache SELECT results and later return them
# without actual executing the same query once again. Having the query
# cache enabled may result in significant speed improvements, if your
# have a lot of identical queries and rarely changing tables. See the
# "Qcache_lowmem_prunes" status variable to check if the current value
# is high enough for your load.
# Note: In case your tables change very often or if your queries are
# textually different every time, the query cache may result in a
# slowdown instead of a performance improvement.
# 查詢緩沖常被用來緩沖 SELECT 的結果並且在下一次同樣查詢的時候不再執行直接返回結果.
# 打開查詢緩沖可以極大的提高服務器速度, 如果你有大量的相同的查詢並且很少修改表.
# 查看 “Qcache_lowmem_prunes” 狀態變量來檢查是否當前值對於你的負載來說是否足夠高.
# 注意: 在你表經常變化的情況下或者如果你的查詢原文每次都不同,
# 查詢緩沖也許引起性能下降而不是性能提升.
query_cache_size = 64M
# Only cache result sets that are smaller than this limit. This is to
# protect the query cache of a very large result set overwriting all
# other query results.
# 只有小於此設定值的結果才會被緩沖
# 此設置用來保護查詢緩沖,防止一個極大的結果集將其他所有的查詢結果都覆蓋.
query_cache_limit = 2M
# Minimum word length to be indexed by the full text search index.
# You might wish to decrease it if you need to search for shorter words.
# Note that you need to rebuild your FULLTEXT index, after you have
# modified this value.
# 被全文檢索索引的最小的字長.
# 你也許希望減少它,如果你需要搜索更短字的時候.
# 注意在你修改此值之後,
# 你需要重建你的 FULLTEXT 索引
ft_min_word_len = 4
# If your system supports the memlock() function call, you might want to
# enable this option while running MySQL to keep it locked in memory and
# to avoid potential swapping out in case of high memory pressure. Good
# for performance.
# 如果你的系統支持 memlock() 函數,你也許希望打開此選項用以讓運行中的mysql在在內存高度緊張的時候,數據在內存中保持鎖定並且防止可能被swapping out
# 此選項對於性能有益
#memlock
# Table type which is used by default when creating new tables, if not
# specified differently during the CREATE TABLE statement.
# 當創建新表時作為默認使用的表類型,
# 如果在創建表示沒有特別執行表類型,將會使用此值
default-storage-engine = MYISAM
# Thread stack size to use. This amount of memory is always reserved at
# connection time. MySQL itself usually needs no more than 64K of
# memory, while if you use your own stack hungry UDF functions or your
# OS requires more stack for some operations, you might need to set this
# to a higher value.
# 線程使用的堆大小. 此容量的內存在每次連接時被預留.
# MySQL 本身常不會需要超過64K的內存
# 如果你使用你自己的需要大量堆的UDF函數
# 或者你的操作系統對於某些操作需要更多的堆,
# 你也許需要將其設置的更高一點.
thread_stack = 192K
# Set the default transaction isolation level. Levels available are:
# 設定默認的事務隔離級別.可用的級別如下:
# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE
transaction_isolation = REPEATABLE-READ
# Maximum size for internal (in-memory) temporary tables. If a table
# grows larger than this value, it is automatically converted to disk
# based table This limitation is for a single table. There can be many
# of them.
# 內部(內存中)臨時表的最大大小
# 如果一個表增長到比此值更大,將會自動轉換為基於磁盤的表.
# 此限制是針對單個表的,而不是總和.
tmp_table_size = 64M
# Enable binary logging. This is required for acting as a MASTER in a
# replication configuration. You also need the binary log if you need
# the ability to do point in time recovery from your latest backup.
# 打開二進制日志功能.
# 在復制(replication)配置中,作為MASTER主服務器必須打開此項
# 如果你需要從你最後的備份中做基於時間點的恢復,你也同樣需要二進制日志.
log-bin=mysql-bin
# binary logging format - mixed recommended
#設定記錄二進制日志的格式,有三種格式,基於語句 statement、 基於行 row、 混合方式 mixed
binlog_format=mixed
# If you're using replication with chained slaves (A->B->C), you need to
# enable this option on server B. It enables logging of updates done by
# the slave thread into the slave's binary log.
# 如果你在使用鏈式從服務器結構的復制模式 (A->B->C),
# 你需要在服務器B上打開此項.
# 此選項打開在從線程上重做過的更新的日志,
# 並將其寫入從服務器的二進制日志.
#log_slave_updates
# Enable the full query log. Every query (even ones with incorrect
# syntax) that the server receives will be logged. This is useful for
# debugging, it is usually disabled in production use.
# 打開查詢日志. 所有的由服務器接收到的查詢 (甚至對於一個錯誤語法的查詢)
# 都會被記錄下來. 這對於調試非常有用, 在生產環境中常常關閉此項.
#log #默認是沒有開啟的,會影響服務器性能
# Print warnings to the error log file. If you have any problem with
# MySQL you should enable logging of warnings and examine the error log
# for possible explanations.
# 將警告打印輸出到錯誤log文件. 如果你對於MySQL有任何問題
# 你應該打開警告log並且仔細審查錯誤日志,查出可能的原因.
#log_warnings
# Log slow queries. Slow queries are queries which take more than the
# amount of time defined in "long_query_time" or which do not use
# indexes well, if log_short_format is not enabled. It is normally good idea
# to have this turned on if you frequently add new queries to the
# system.
# 記錄慢速查詢. 慢速查詢是指消耗了比 “long_query_time” 定義的更多時間的查詢.
# 如果 log_long_format 被打開,那些沒有使用索引的查詢也會被記錄.
# 如果你經常增加新查詢到已有的系統內的話. 一般來說這是一個好主意
slow_query_log
# All queries taking more than this amount of time (in seconds) will be
# trated as slow. Do not use "1" as a value here, as this will result in
# even very fast queries being logged from time to time (as MySQL
# currently measures time with second accuracy only).
# 所有的使用了比這個時間(以秒為單位)更多的查詢會被認為是慢速查詢.
# 不要在這裡使用”1″, 否則會導致所有的查詢,甚至非常快的查詢頁被記錄下來(由於MySQL 目前時間的精確度只能達到秒的級別).
long_query_time = 2
# *** Replication related settings # *** 主從復制相關的設置
# Unique server identification number between 1 and 2^32-1. This value
# is required for both master and slave hosts. It defaults to 1 if
# "master-host" is not set, but will MySQL will not function as a master
# if it is omitted.
# 唯一的服務辨識號,數值位於 1 到 2^32-1之間.
# 此值在master和slave上都需要設置.
# 如果 “master-host” 沒有被設置,則默認為1, 但是如果忽略此選項,MySQL不會作為master生效.
server-id = 1
# Replication Slave (comment out master section to use this) #復制的Slave (去掉master段的注釋來使其生效)
#
# To configure this host as a replication slave, you can choose between
# two methods : #為了配置此主機作為復制的slave服務器,你可以選擇兩種方法:
#
# 1) Use the CHANGE MASTER TO command (fully described in our manual) -
# the syntax is: #使用 CHANGE MASTER TO 命令 (在我們的手冊中有完整描述) -
# 語法如下:
#
# CHANGE MASTER TO MASTER_HOST=<host>, MASTER_PORT=<port>,
# MASTER_USER=<user>, MASTER_PASSWORD=<password> ;
#
# where you replace <host>, <user>, <password> by quoted strings and
# <port> by the master's port number (3306 by default).
# 你需要替換掉 , , 等被尖括號包圍的字段以及使用master的端口號替換 (默認3306).
# Example: 案例
#
# CHANGE MASTER TO MASTER_HOST='125.564.12.1', MASTER_PORT=3306,
# MASTER_USER='joe', MASTER_PASSWORD='secret';
#
# OR 或者
#
# 2) Set the variables below. However, in case you choose this method, then
# start replication for the first time (even unsuccessfully, for example
# if you mistyped the password in master-password and the slave fails to
# connect), the slave will create a master.info file, and any later
# changes in this file to the variable values below will be ignored and
# overridden by the content of the master.info file, unless you shutdown
# the slave server, delete master.info and restart the slaver server.
# For that reason, you may want to leave the lines below untouched
# (commented) and instead use CHANGE MASTER TO (see above)
#
#設置以下的變量. 不論如何, 在你選擇這種方法的情況下, 然後第一次啟動復制(甚至不成功的情況下,
# 例如如果你輸入錯密碼在master-password字段並且slave無法連接),
# slave會創建一個 master.info 文件,並且之後任何對於包含在此文件內的參數的變化都會被忽略
# 並且由 master.info 文件內的內容覆蓋, 除非你關閉slave服務, 刪除 master.info 並且重啟slave 服務.
# 由於這個原因,你也許不想碰一下的配置(注釋掉的) 並且使用 CHANGE MASTER TO (查看上面) 來代替
# required unique id between 2 and 2^32 - 1
# (and different from the master)
# defaults to 2 if master-host is set
# but will not function as a slave if omitted
# 所需要的唯一id號位於 2 和 2^32 – 1之間
# (並且和master不同)
# 如果master-host被設置了.則默認值是2
# 但是如果省略,則不會生效
#server-id = 2
#
# The replication master for this slave – required
# 復制結構中的master – 必須
#master-host = <hostname>
#
# The username the slave will use for authentication when connecting
# to the master – required
# 當連接到master上時slave所用來認證的用戶名 – 必須
#master-user = <username>
#
# The password the slave will authenticate with when connecting to
# the master – required
# 當連接到master上時slave所用來認證的密碼 – 必須
#master-password = <password>
#
# The port the master is listening on.
# optional - defaults to 3306
# master監聽的端口.
# 可選 – 默認是3306
#master-port = <port>
# Make the slave read-only. Only users with the SUPER privilege and the
# replication slave thread will be able to modify data on it. You can
# use this to ensure that no applications will accidently modify data on
# the slave instead of the master
# 使得slave只讀.只有用戶擁有SUPER權限和在上面的slave線程能夠修改數據.
# 你可以使用此項去保證沒有應用程序會意外的修改slave而不是master上的數據
#read_only
#*** MyISAM Specific options
#*** MyISAM 相關選項
# Size of the Key Buffer, used to cache index blocks for MyISAM tables.
# Do not set it larger than 30% of your available memory, as some memory
# is also required by the OS to cache rows. Even if you're not using
# MyISAM tables, you should still set it to 8-64M as it will also be
# used for internal temporary disk tables.
# 關鍵詞緩沖的大小, 一般用來緩沖MyISAM表的索引塊.
# 不要將其設置大於你可用內存的30%,
# 因為一部分內存同樣被OS用來緩沖行數據
# 甚至在你並不使用MyISAM 表的情況下, 你也需要仍舊設置起 8-64M 內存由於它同樣會被內部臨時磁盤表使用.
key_buffer_size = 32M
# MyISAM uses special tree-like cache to make bulk inserts (that is,
# INSERT ... SELECT, INSERT ... VALUES (...), (...), ..., and LOAD DATA
# INFILE) faster. This variable limits the size of the cache tree in
# bytes per thread. Setting it to 0 will disable this optimisation. Do
# not set it larger than "key_buffer_size" for optimal performance.
# This buffer is allocated when a bulk insert is detected.
# MyISAM 使用特殊的類似樹的cache來使得突發插入
# (這些插入是,INSERT … SELECT, INSERT … VALUES (…), (…), …, 以及 LOAD DATA
# INFILE) 更快. 此變量限制每個進程中緩沖樹的字節數.
# 設置為 0 會關閉此優化.
# 為了最優化不要將此值設置大於 “key_buffer_size”.
# 當突發插入被檢測到時此緩沖將被分配.
bulk_insert_buffer_size = 64M
# This buffer is allocated when MySQL needs to rebuild the index in
# REPAIR, OPTIMIZE, ALTER table statements as well as in LOAD DATA INFILE
# into an empty table. It is allocated per thread so be careful with
# large settings.
# 此緩沖當MySQL需要在 REPAIR, OPTIMIZE, ALTER 以及 LOAD DATA INFILE 到一個空表中引起重建索引時被分配.
# 這在每個線程中被分配.所以在設置大值時需要小心.
myisam_sort_buffer_size = 128M
# The maximum size of the temporary file MySQL is allowed to use while
# recreating the index (during REPAIR, ALTER TABLE or LOAD DATA INFILE.
# If the file-size would be bigger than this, the index will be created
# through the key cache (which is slower).
# MySQL重建索引時所允許的最大臨時文件的大小 (當 REPAIR, ALTER TABLE 或者 LOAD DATA INFILE).
# 如果文件大小比此值更大,索引會通過鍵值緩沖創建(更慢)
myisam_max_sort_file_size = 10G
# If a table has more than one index, MyISAM can use more than one
# thread to repair them by sorting in parallel. This makes sense if you
# have multiple CPUs and plenty of memory.
# 如果一個表擁有超過一個索引, MyISAM 可以通過並行排序使用超過一個線程去修復他們.
# 這對於擁有多個CPU以及大量內存情況的用戶,是一個很好的選擇.
myisam_repair_threads = 1
# Automatically check and repair not properly closed MyISAM tables.
# 自動檢查和修復沒有適當關閉的 MyISAM 表.
myisam_recover
# *** INNODB Specific options ***
# *** INNODB 相關選項 ***
# Use this option if you have a MySQL server with InnoDB support enabled
# but you do not plan to use it. This will save memory and disk space
# and speed up some things.
# 如果你的MySQL服務包含InnoDB支持但是並不打算使用的話,
# 使用此選項會節省內存以及磁盤空間,並且加速某些部分
#skip-innodb
# Additional memory pool that is used by InnoDB to store metadata
# information. If InnoDB requires more memory for this purpose it will
# start to allocate it from the OS. As this is fast enough on most
# recent operating systems, you normally do not need to change this
# value. SHOW INNODB STATUS will display the current amount used.
# 附加的內存池被InnoDB用來保存 metadata 信息
# 如果InnoDB為此目的需要更多的內存,它會開始從OS這裡申請內存.
# 由於這個操作在大多數現代操作系統上已經足夠快, 你一般不需要修改此值.
# SHOW INNODB STATUS 命令會顯示當先使用的數量.
innodb_additional_mem_pool_size = 16M
# InnoDB, unlike MyISAM, uses a buffer pool to cache both indexes and
# row data. The bigger you set this the less disk I/O is needed to
# access data in tables. On a dedicated database server you may set this
# parameter up to 80% of the machine physical memory size. Do not set it
# too large, though, because competition of the physical memory may
# cause paging in the operating system. Note that on 32bit systems you
# might be limited to 2-3.5G of user level memory per process, so do not
# set it too high.
# InnoDB使用一個緩沖池來保存索引和原始數據, 不像 MyISAM.
# 這裡你設置越大,你在存取表裡面數據時所需要的磁盤I/O越少.
# 在一個獨立使用的數據庫服務器上,你可以設置這個變量到服務器物理內存大小的80%
# 不要設置過大,否則,由於物理內存的競爭可能導致操作系統的換頁顛簸.
# 注意在32位系統上你每個進程可能被限制在 2-3.5G 用戶層面內存限制,
# 所以不要設置的太高.
innodb_buffer_pool_size = 2G
# InnoDB stores data in one or more data files forming the tablespace.
# If you have a single logical drive for your data, a single
# autoextending file would be good enough. In other cases, a single file
# per device is often a good choice. You can configure InnoDB to use raw
# disk partitions as well - please refer to the manual for more info
# about this.
# InnoDB 將數據保存在一個或者多個數據文件中成為表空間.
# 如果你只有單個邏輯驅動保存你的數據,一個單個的自增文件就足夠好了.
# 其他情況下.每個設備一個文件一般都是個好的選擇.
# 你也可以配置InnoDB來使用裸盤分區 – 請參考手冊來獲取更多相關內容
innodb_data_file_path = ibdata1:10M:autoextend
# Set this option if you would like the InnoDB tablespace files to be
# stored in another location. By default this is the MySQL datadir.
# 設置此選項如果你希望InnoDB表空間文件被保存在其他分區.
# 默認保存在MySQL的datadir中.
#innodb_data_home_dir = <directory>
# Number of IO threads to use for async IO operations. This value is
# hardcoded to 8 on Unix, but on Windows disk I/O may benefit from a
# larger number.
# 用來同步IO操作的IO線程的數量. This value is
# 此值在Unix下被硬編碼為8,但是在Windows磁盤I/O可能在一個大數值下表現的更好.
innodb_write_io_threads = 8
innodb_read_io_threads = 8
# If you run into InnoDB tablespace corruption, setting this to a nonzero
# value will likely help you to dump your tables. Start from value 1 and
# increase it until you're able to dump the table successfully.
# 如果你發現InnoDB表空間損壞, 設置此值為一個非零值可能幫助你導出你的表.
# 從1開始並且增加此值知道你能夠成功的導出表.
#innodb_force_recovery=1
# Number of threads allowed inside the InnoDB kernel. The optimal value
# depends highly on the application, hardware as well as the OS
# scheduler properties. A too high value may lead to thread thrashing.
# 在InnoDb核心內的允許線程數量.
# 最優值依賴於應用程序,硬件以及操作系統的調度方式.
# 過高的值可能導致線程的互斥顛簸.
innodb_thread_concurrency = 16
# If set to 1, InnoDB will flush (fsync) the transaction logs to the
# disk at each commit, which offers full ACID behavior. If you are
# willing to compromise this safety, and you are running small
# transactions, you may set this to 0 or 2 to reduce disk I/O to the
# logs. Value 0 means that the log is only written to the log file and
# the log file flushed to disk approximately once per second. Value 2
# means the log is written to the log file at each commit, but the log
# file is only flushed to disk approximately once per second.
# 如果設置為1 ,InnoDB會在每次提交後刷新(fsync)事務日志到磁盤上,
# 這提供了完整的ACID行為.
# 如果你願意對事務安全折衷, 並且你正在運行一個小的食物, 你可以設置此值到0或者2來減少由事務日志引起的磁盤I/O
# 0代表日志只大約每秒寫入日志文件並且日志文件刷新到磁盤.
# 2代表日志寫入日志文件在每次提交後,但是日志文件只有大約每秒才會刷新到磁盤上.
innodb_flush_log_at_trx_commit = 1
# Speed up InnoDB shutdown. This will disable InnoDB to do a full purge
# and insert buffer merge on shutdown. It may increase shutdown time a
# lot, but InnoDB will have to do it on the next startup instead.
# 加速InnoDB的關閉. 這會阻止InnoDB在關閉時做全清除以及插入緩沖合並.
# 這可能極大增加關機時間, 但是取而代之的是InnoDB可能在下次啟動時做這些操作.
#innodb_fast_shutdown
# The size of the buffer InnoDB uses for buffering log data. As soon as
# it is full, InnoDB will have to flush it to disk. As it is flushed
# once per second anyway, it does not make sense to have it very large
# (even with long transactions).
# 用來緩沖日志數據的緩沖區的大小.
# 當此值快滿時, InnoDB將必須刷新數據到磁盤上.
# 由於基本上每秒都會刷新一次,所以沒有必要將此值設置的太大(甚至對於長事務而言)
innodb_log_buffer_size = 8M
# Size of each log file in a log group. You should set the combined size
# of log files to about 25%-100% of your buffer pool size to avoid
# unneeded buffer pool flush activity on log file overwrite. However,
# note that a larger logfile size will increase the time needed for the
# recovery process.
# 在日志組中每個日志文件的大小.
# 你應該設置日志文件總合大小到你緩沖池大小的25%~100%
# 來避免在日志文件覆寫上不必要的緩沖池刷新行為.
# 不論如何, 請注意一個大的日志文件大小會增加恢復進程所需要的時間.
innodb_log_file_size = 256M
# Total number of files in the log group. A value of 2-3 is usually good
# enough.
# 在日志組中的文件總數.
# 通常來說2~3是比較好的.
innodb_log_files_in_group = 3
# Location of the InnoDB log files. Default is the MySQL datadir. You
# may wish to point it to a dedicated hard drive or a RAID1 volume for
# improved performance
# InnoDB的日志文件所在位置. 默認是MySQL的datadir.
# 你可以將其指定到一個獨立的硬盤上或者一個RAID1卷上來提高其性能
#innodb_log_group_home_dir
# Maximum allowed percentage of dirty pages in the InnoDB buffer pool.
# If it is reached, InnoDB will start flushing them out agressively to
# not run out of clean pages at all. This is a soft limit, not
# guaranteed to be held.
# 在InnoDB緩沖池中最大允許的髒頁面的比例.
# 如果達到限額, InnoDB會開始刷新他們防止他們妨礙到干淨數據頁面.
# 這是一個軟限制,不被保證絕對執行.
innodb_max_dirty_pages_pct = 90
# The flush method InnoDB will use for Log. The tablespace always uses
# doublewrite flush logic. The default value is "fdatasync", another
# option is "O_DSYNC".
# InnoDB用來刷新日志的方法.
# 表空間總是使用雙重寫入刷新方法
# 默認值是 “fdatasync”, 另一個是 “O_DSYNC”.
#innodb_flush_method=O_DSYNC
# How long an InnoDB transaction should wait for a lock to be granted
# before being rolled back. InnoDB automatically detects transaction
# deadlocks in its own lock table and rolls back the transaction. If you
# use the LOCK TABLES command, or other transaction-safe storage engines
# than InnoDB in the same transaction, then a deadlock may arise which
# InnoDB cannot notice. In cases like this the timeout is useful to
# resolve the situation.
# 在被回滾前,一個InnoDB的事務應該等待一個鎖被批准多久.
# InnoDB在其擁有的鎖表中自動檢測事務死鎖並且回滾事務.
# 如果你使用 LOCK TABLES 指令, 或者在同樣事務中使用除了InnoDB以外的其他事務安全的存儲引擎
# 那麼一個死鎖可能發生而InnoDB無法注意到.
# 這種情況下這個timeout值對於解決這種問題就非常有幫助.
innodb_lock_wait_timeout = 120
[mysqldump]
# Do not buffer the whole result set in memory before writing it to
# file. Required for dumping very large tables
# 不要在將內存中的整個結果寫入磁盤之前緩存. 在導出非常巨大的表時需要此項
quick
max_allowed_packet = 16M
[mysql]
no-auto-rehash
# Only allow UPDATEs and DELETEs that use keys.
# 僅僅允許使用鍵值的 UPDATEs 和 DELETEs .
#safe-updates
[myisamchk]
key_buffer_size = 512M
sort_buffer_size = 512M
read_buffer = 8M
write_buffer = 8M
[mysqlhotcopy]
interactive-timeout
[mysqld_safe]
# Increase the amount of open files allowed per process. Warning: Make
# sure you have set the global system limit high enough! The high value
# is required for a large number of opened tables
# 增加每個進程的可打開文件數量.
# 警告: 確認你已經將全系統限制設定的足夠高!
# 打開大量表需要將此值設大
open-files-limit = 8192
三、配置文件優化(根據實際情況優化)
說明,上文中我對my-innodb-heavy-4G.cnf中默認的所有選項進行了說明,下面我就根據我們公司的實際情況進行優化!
1.服務器的運行環境
硬件服務器:Dell R710,雙至強E5620 CPU、16G內存、6*500G硬盤
操作系統:CentOS5.5 X86_64 系統
Mysql版本:MySQL 5.5.32
適用於:日IP 100-200W ,日PV 200-500W 的站點
2.具體優化配置如下
[client]
port = 3306
socket = /tmp/mysql.sock
default-character-set = utf8 #設置客戶端的字符編碼
[mysqld]
# generic configuration options
port = 3306
socket = /tmp/mysql.sock
#*** char set ***
character-set-server = utf8 #設置服務器端的字符編碼
#*** network ***
back_log = 512
#skip-networking #默認沒有開啟
max_connections = 3000
max_connect_errors = 30
table_open_cache = 4096
#external-locking #默認沒有開啟
max_allowed_packet = 32M
max_heap_table_size = 128M
# *** global cache ***
read_buffer_size = 8M
read_rnd_buffer_size = 64M
sort_buffer_size = 16M
join_buffer_size = 16M
# *** thread ***
thread_cache_size = 16
thread_concurrency = 8
thread_stack = 512K
# *** query cache ***
query_cache_size = 128M
query_cache_limit = 4M
# *** index ***
ft_min_word_len = 8
#memlock #默認沒有開啟
default-storage-engine = INNODB
transaction_isolation = REPEATABLE-READ
# *** tmp table ***
tmp_table_size = 64M
# *** bin log ***
log-bin=mysql-bin
binlog_cache_size = 4M
binlog_format=mixed
#log_slave_updates #默認沒有開啟
#log #默認沒有開啟,此處是查詢日志,開啟會影響服務器性能
log_warnings #開啟警告日志
# *** slow query log ***
slow_query_log
long_query_time = 10
# *** Replication related settings
server-id = 1
#server-id = 2
#master-host = <hostname>
#master-user = <username>
#master-password = <password>
#master-port = <port>
#read_only
#*** MyISAM Specific options
key_buffer_size = 128M
bulk_insert_buffer_size = 256M
myisam_sort_buffer_size = 256M
myisam_max_sort_file_size = 10G
myisam_repair_threads = 1
myisam_recover
# *** INNODB Specific options ***
#skip-innodb #默認沒有開啟
innodb_additional_mem_pool_size = 64M
innodb_buffer_pool_size = 6G #注意在32位系統上你每個進程可能被限制在 2-3.5G 用戶層面內存限制, 所以不要設置的太高.
innodb_data_file_path = ibdata1:10M:autoextend
#innodb_data_home_dir = <directory>
innodb_write_io_threads = 8
innodb_read_io_threads = 8
#innodb_force_recovery=1
innodb_thread_concurrency = 16
innodb_flush_log_at_trx_commit = 2
#說明:innodb_flush_log_at_trx_commit = 2 如果是游戲服務器,建議此值設置為2;如果是對數據安全要求極高的應用,建議設置為1;設置為0性能最高,但如果發生故障,數據可能會有丟失的危險!默認值1的意思是每一次事務提交或事務外的指令都需要把日志寫入(flush)硬盤,這是很費時的。特別是使用電池供電緩存(Battery backed up cache)時。設成2對於很多運用,特別是從MyISAM表轉過來的是可以的,它的意思是不寫入硬盤而是寫入系統緩存。日志仍然會每秒flush到硬盤,所以你一般不會丟失超過1-2秒的更新。設成0會更快一點,但安全方面比較差,即使MySQL掛了也可能會丟失事務的數據。而值2只會在整個操作系統掛了時才可能丟數據。
#innodb_fast_shutdown
innodb_log_buffer_size = 16M
innodb_log_file_size = 512M
innodb_log_files_in_group = 3
#innodb_log_group_home_dir
innodb_max_dirty_pages_pct = 90
#innodb_flush_method=O_DSYNC
innodb_lock_wait_timeout = 120
[mysqldump]
quick
max_allowed_packet = 32M
[mysql]
no-auto-rehash
[myisamchk]
key_buffer_size = 2048M
sort_buffer_size = 2048M
read_buffer = 32M
write_buffer = 32M
[mysqlhotcopy]
interactive-timeout
[mysqld_safe]
open-files-limit = 10240
3.總結
MySQL 配置文件的優化是根據線上環境的實際需要進行優化,不能隨便沒有根據的進行優化,寫這篇博文就是給博友們一些參考!
4.MySQL狀態查看的常用命令
mysql> show status; #顯示狀態信息 mysql> show variables; #顯示系統變量 mysql> show engines; #查看所有引擎 mysql> show engine innodb status; #顯示InnoDB存儲引擎的狀態
本文出自 “Share your knowledge …” 博客
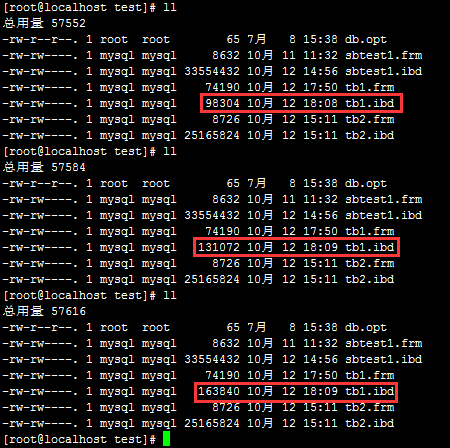
經過幫客之家小編的測試,這樣的效率很不錯,直接拿來就可以使用。